
 scalable architecture deploys pose estimation models using Amazon Kinesis Data Streams and Amazon EKS")
{kind=link}
This blog post is co-written by Jonathan Lee, Nelson Leung, Paul Min, and Troy Squillaci from Intel.
In Part 1 of this post, we discussed how Intel®3DAT collaborated with AWS Machine Learning Professional Services (MLPS) to build a scalable AI SaaS application. 3DAT uses computer vision and AI to recognize, track, and analyze over 1,000 biomechanics data points from standard video. It allows customers to create rich and powerful biomechanics-driven products, such as web and mobile applications with detailed performance data and three-dimensional visualizations.
In Part 2 of this post, we dive deeper into each stage of the architecture. We explore the AWS services used to meet the 3DAT design requirements, including Amazon Kinesis Data Streams and Amazon Elastic Kubernetes Service (Amazon EKS), in order to scalably deploy the necessary pose estimation models for this software as a service (SaaS) application.
Architecture overview
The primary goal of the MLPS team was to productionalize the 2D and 3D pose estimation model pipelines and create a functional and scalable application. The following diagram illustrates the solution architecture.
{kind=link}
The complete architecture is broken down into five major components:
User application interface layers
Database
Workflow orchestration
Scalable pose estimation inference generation
Operational monitoring
Let’s go into detail on each component, their interactions, and the rationale behind the design choices.
User application interface layers
The following diagram shows the application interface layers that provide user access and control of the application and its resources.
{kind=link}
These access points support different use cases based on different customer personas. For example, an application user can submit a job via the CLI, whereas a developer can build an application using the Python SDK and embed pose estimation intelligence into their applications. The CLI and SDK are built as modular components—both layers are wrappers of the API layer, which is built using Amazon API Gateway to resolve the API calls and associated AWS Lambda functions, which take care of the backend logic associated with each API call. These layers were a crucial component for the Intel OTG team because it opens up a broad base of customers that can effectively use this SaaS application.
API layer
The solution has a core set of nine APIs, which correspond to the types of objects that operate on this platform. Each API has a Python file that defines the API actions that can be run. The creation of new objects is automatically assigned an object ID sequentially. The attributes of these objects are stored and tracked in the Amazon Aurora Serverless database using this ID. Therefore, the API actions tie back to functions that are defined in a central file that contains the backend logic for querying the Aurora database. This backend logic uses the Boto3 Amazon RDS DataService client to access the database cluster.
The one exception is the /job API, which has a create_job method that handles video submission for creating a new processing job. This method starts the AWS Step Functions workflow logic for running the job. By passing in a job_id, this method uses the Boto3 Step Functions client to call the start_execution method for a specified stateMachineARN (Amazon Resource Name).
The eight object APIs have the methods and similar access pattern as summarized in the following table.
Method Type
Function Name
Description
GET
list_[object_name]s
Selects all objects of this type from the database and displays.
POST
create_[object]
Inserts a new object record with required inputs into the database.
GET
get_[object]
Selects object attributes based on the object ID from the database and displays.
PUT
update_[object]
Updates an existing object record with the required inputs.
DELETE
delete_[object]
Deletes an existing object record from the database based on object ID.
The details of the nine APIs are as follows:
/user – A user is the identity of someone authorized to submit jobs to this application. The creation of a user requires a user name, user email, and group ID that the user belongs to.
/user_group – A user group is a collection of users. Every user group is mapped to one project and one pipeline parameter set. To have different tiers (in terms of infrastructural resources and pipeline parameters), users are divided into user groups. Each user can belong to only one user group. The creation of a user group requires a project ID, pipeline parameter set ID, user group name, and user group description. Note that user groups are different from user roles defined in the AWS account. The latter is used to provide different level of access based on their access roles (for example admin).
/project – A project is used to group different sets of infrastructural resources together. A project is associated with a single project_cluster_url (Aurora cluster) for recording users, jobs, and other metadata, a project_queue_arn (Kinesis Data Streams ARN), and a compute runtime environment (currently controlled via Cortex) used for running inference on the frame batches or postprocessing on the videos. Each user group is associated to one project, and this mechanism is how different tiers are enabled in terms of latency and compute power for different groups of users. The creation of a project requires a project name, project cluster URL, and project queue ARN.
/pipeline – A pipeline is associated with a single configuration for a sequence of processing containers that perform video processing in the Amazon EKS inference generation cluster coordinated by Cortex (see the section on video processing inference generation for more details). Typically, this consists of three containers: preprocessing and decoding, object detection, and pose estimation. For example, the decode and object detection step are the same for the 2D and 3D pipelines, but swapping out the last container using either HRNet or 3DMPPE results in the parameter set for 2D vs. 3D processing pipelines. You can create new configurations to define possible pipelines that can be used for processing, and it requires as input a new Python file in the Cortex repo that details the sequence of model endpoints call that define that pipeline (see the section on video processing inference generation). The pipeline endpoint is the Cortex endpoint that is called to process a single frame. The creation of a pipeline requires a pipeline name, pipeline description, and pipeline endpoint.
/pipeline_parameter_set – A pipeline parameter set is a flexible JSON collection of multiple parameters (a pipeline configuration runtime) for a particular pipeline, and is added to provide flexibility for future customization when multiple pipeline configuration runtimes are required. User groups can be associated with a particular pipeline parameter set, and its purpose is to have different groups of parameters per user group and per pipeline. This was an important forward-looking addition for Intel OTG to build in customization that supports portability as different customers, particularly ISVs, start using the application.
/pipeline_parameters – A single collection of pipeline parameters is an instantiation of a pipeline parameter set. This makes it a 1:many mapping of a pipeline parameter set to pipeline parameters. This API requires a pipeline ID to associate with the set of pipeline parameters that enables the creation of a pipeline for a 1:1 mapping of pipeline parameters to the pipeline. The other inputs required by this API are a pipeline parameter set ID, pipeline parameters value, and pipeline parameters name.
/video – A video object is used to define individual videos that make up a .zip package submitted during a job. This file is broken up into multiple videos after submission. A video is related to the job_id for the job where the .zip package is submitted, and Amazon Simple Storage Service (Amazon S3) paths for the location of the raw separated videos and the postprocessing results of each video. The video object also contains a video progress percentage, which is consistently updated during processing of individual frame batches of that video, as well as a video status flag for complete or not complete. The creation of a video requires a job ID, video path, video results path, video progress percentage, and video status.
/frame_batch – A frame_batch object is a mini-batch of frames created by sampling a single video. Separating a video into regular-sized frame batches provides a lever to tune latency and increases parallelization and throughput. This is the granular unit that is run through Kinesis Data Streams for inference. A creation of a frame batch requires a video ID, frame batch start number, frame batch end number, frame batch input path, frame batch results path, and frame batch status.
/job – This interaction API is used for file submission to start a processing job. This API has a different function from other object APIs because it’s the direct path to interact with the video processing backend Step Functions workflow coordination and Amazon EKS cluster. This API requires a user ID, project ID, pipeline ID, pipeline parameter set ID, job parameters, and job status. In the job parameters, an input file path is specified, which is the location in Amazon S3 where the .zip package of videos to be processed is located. File upload is handled with the upload_handler method, which generates a presigned S3 URL for the user to place a file. A WORKFLOW_STATEMACHINE_ARN is an environment variable that is passed to the create_job API to specify where a video .zip package with an input file path is submitted to start a job.
The following table summarizes the API’s functions.
Method Type
Function
Description
GET
list_jobs
Selects all jobs from the database and displays.
POST
create_ job
Inserts a new job record with user ID, project ID, pipeline ID, pipeline parameter set ID, job results path, job parameters, and job status.
GET
get_ job
Selects job attributes based on job ID from the database and displays.
GET
upload_handler
Generates a presigned S3 URL as the location for the .zip file upload. Requires an S3 bucket name and expects an application/zip file type.
Python SDK layer
Building upon the APIs, the team created a Python SDK client library as a wrapper to make it easier for developers to access the API methods. They used the open-source Poetry, which handles Python packaging and dependency management. They created a client.py file that contains functions wrapping each of the APIs using the Python requests library to handle API requests and exceptions.
For developers to launch the Intel 3DAT SDK, they need to install and build the Poetry package. Then, they can add a simple Python import of intel_3dat_sdk to any Python code.
To use the client, you can create an instance of the client, specifying the API endpoint:
You can then use the client to call the individual methods such as the create_pipeline method (see the following code), taking in the proper arguments such as pipeline name and pipeline description.
CLI layer
Similarly, the team built on the APIs to create a command line interface for users who want to access the API methods with a straightforward interface without needing to write Python code. They used the open-source Python package Click (Command Line Interface Creation Kit). The benefits of this framework are the arbitrary nesting of commands, automatic help page generation, and support of lazy loading of subcommands at runtime. In the same client.py file as in the SDK, each SDK client method was wrapped using Click and the required method arguments were converted to command line flags. The flag inputs are then used when calling the SDK command.
To launch the CLI, you can use the CLI configure command. You’re prompted for the endpoint URL:
Now you can use the CLI to call different commands related to the API methods, for example:
Database
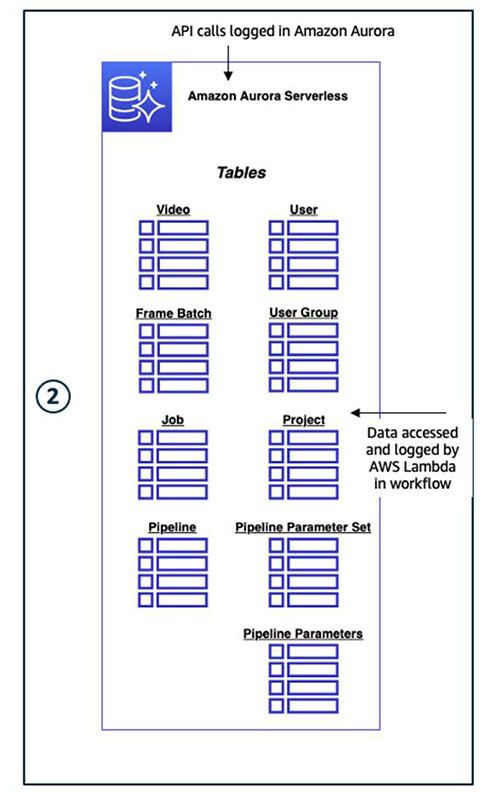
As a database, this application uses Aurora Serverless to store metadata associated with each of the APIs with MYSQL as the database engine. Choosing the Aurora Serverless database service adheres to the design principle to minimize infrastructural overhead by utilizing serverless AWS services when possible. The following diagram illustrates this architecture.
{kind=link}
The serverless engine mode meets the intermittent usage pattern because this application scales up to new customers and workloads are still uncertain. When launching a database endpoint, a specific DB instance size isn’t required, only a minimum and maximum range for cluster capacity. Aurora Serverless handles the appropriate provisioning of a router fleet and distributes the workload amongst the resources. Aurora Serverless automatically performs backup retention for a minimum of 1 day up to 35 days. The team optimized for safety by setting the default to the maximum value of 35.
In addition, the team used the Data API to handle access to the Aurora Serverless cluster, which doesn’t require a persistent connection, and instead provides a secure HTTP endpoint and integration with AWS SDKs. This feature uses AWS Secrets Manager to store the database credentials so there is no need to explicitly pass credentials. CREATE TABLE scripts were written in .sql files for each of the nine tables that correspond to the nine APIs. Because this database contained all the metadata and state of objects in the system, the API methods were run using the appropriate SQL commands (for example select * from Job for the list_jobs API) and passed to the execute_statement method from the Amazon RDS client in the Data API.
Workflow orchestration
The functional backbone of the application was handled using Step Functions to coordinate the workflow, as shown in the following diagram.
{kind=link}
The state machine consisted of a sequence of four Lambda functions, which starts when a job is submitted using the create_job method from the job API. The user ID, project ID, pipeline ID, pipeline parameter set ID, job results path, job parameters, and job status are required for job creation. You can first upload a .zip package of video files using the upload_handler method from the job API to generate a presigned S3 URL. During job submission, the input file path is passed via the job parameters, to specify the location of the file. This starts the run of the workflow state machine, triggering four main steps:
Initializer Lambda function
Submitter Lambda function
Completion Check Lambda function
Collector Lambda function
Initializer Lambda function
The main function of the Initializer is to separate the .zip package into individual video files and prepare them for the Submitter. First, the .zip file is downloaded, and then each individual file, including video files, is unzipped and extracted. The videos, preferably in .mp4 format, are uploaded back into an S3 bucket. Using the create_video method in the video API, a video object is created with the video path as input. This inserts data on each video into the Aurora database. Any other file types, such as JSON files, are considered metadata and similarly uploaded, but no video object is created. A list of the names of files and video files extracted is passed to the next step.
Submitter Lambda function
The Submitter function takes the video files that were extracted by the Initializer and creates mini-batches of video frames as images. Most current computer vision models in production have been trained on images so even when video is processed, they’re first separated into image frames before model inference. This current solution using a state-of-the-art pose estimation model is no different—the frame batches from the Submitter are passed to Kinesis Data Streams to initiate the inference generation step.
First, the video file is downloaded by the Lambda function. The frame rate and number of frames is calculated using the FileVideoStream module from the imutils.video processing library. The frames are extracted and grouped according to a specified mini-batch size, which is one of the key tunable parameters of this pipeline. Using the Python pickle library, the data is serialized and uploaded to Amazon S3. Subsequently, a frame batch object is created and the metadata entry is created in the Aurora database. This Lambda function was built using a Dockerfile with dependencies on opencv-python, numpy, and imutils libraries.
Completion Check Lambda function
The Completion Check function continues to query the Aurora database to see, for each video in the .zip package for this current job, how many frame batches are in the COMPLETED status. When all frame batches for all videos are complete, then this check process is complete.
Collector Lambda function
The Collector function takes the outputs of the inferences that were performed on each frame during the Consumer stage and combines them across a frame batch and across a video. The combined merged data is then upload to an S3 bucket. The function then invokes the Cortex postprocessing API for a particular ML pipeline in order to perform any postprocessing computations, and adds the aggregated results by video to the output bucket. Many of these metrics are calculated across frames, such as speed, acceleration, and joint angle, so this calculation needs to be performed on the aggregated data. The main outputs include body key points data (aggregated into CSV format), BMA calculations (such as acceleration), and visual overlay of key points added to each frame in an image file.
Scalable pose estimation inference generation
The processing engine that powers the scaling of ML inference happens in this stage. It involves three main pieces, each with have their own concurrency levers that can be tuned for latency tradeoffs (see the following diagram).
{kind=link}
This architecture allows for experimentation in testing latency gains, as well as flexibility for the future when workloads may change with different mixes of end-user segments that access the application.
Kinesis Data Streams
The team chose Kinesis Data Streams because it’s typically used to handle streaming data, and in this case is a good fit because it can handle frame batches in a similar way to provide scalability and parallelization. In the Submitter Lambda function, the Kinesis Boto3 client is used, with the put_record method passing in the metadata associated with a single frame batch, such as the frame batch ID, frame batch starting frame, frame batch ending frame, image shape, frame rate, and video ID.
We defined various job queue and Kinesis data stream configurations to set levels of throughput that tie back to the priority level of different user groups. Access to different levels of processing power is linked by passing a project queue ARN when creating a new project using the project API. Every user group is then linked to a particular project during user group creation. Three default stream configurations are defined in the AWS Serverless Application Model (AWS SAM) infrastructure template:
Standard – JobStreamShardCount
Priority – PriorityJobStreamShardCount
High priority – HighPriorityJobStreamShardCount
The team used a few different levers to differentiate the processing power of each stream or tune the latency of the system, as summarized in the following table.
Lever
Description
Default value
Shard
A shard is native to Kinesis Data Streams; it’s the base unit of throughput for ingestion. The default is 1MB/sec, which equates to 1,000 data records per second.
2
KinesisBatchSize
The maximum number of records that Kinesis Data Streams retrieves in a single batch before invoking the consumer Lambda function.
1
KinesisParallelizationFactor
The number of batches to process from each shard concurrently.
1
Enhanced fan-out
Data consumers who have enhanced fan-out activated have a dedicated ingestion throughput per consumer (such as the default 1MB/sec) instead of sharing throughput across consumers.
Off
Consumer Lambda function
From the perspective of Kinesis Data Streams, a data consumer is an AWS service that retrieves data from a data stream shard as data is generated in a stream. This application uses a Consumer Lambda function, which is invoked when messages are passed from the data stream queues. Each Consumer function processes one frame batch by performing the following steps. First, a call is made to the Cortex processor API synchronously, which is the endpoint that hosts the model inference pipeline (see the next section regarding Amazon EKS with Cortex for more details). The results are stored in Amazon S3, and an update is made to the database by changing the status of the processed frame batch to Complete. Error handling is built in to manage the Cortex API call with a retry loop to handle any 504 errors from the Cortex cluster, with number of retries set to 5.
Amazon EKS with Cortex for ML inference
The team used Amazon EKS, a managed Kubernetes service in AWS, as the compute engine for ML inference. A design choice was made to use Amazon EKS to host ML endpoints, giving the flexibility of running upstream Kubernetes with the option of clusters both fully managed in AWS via AWS Fargate, or on-premises hardware via Amazon EKS Anywhere. This was a critical piece of functionality desired by Intel OTG, which provided the option to hook up this application to specialized on-premises hardware, for example.
The three ML models that were the building blocks for constructing the inference pipelines were a custom Yolo model (for object detection), a custom HRNet model (for 2D pose estimation), and a 3DMPPE model (for 3D pose estimation) (see the previous ML section for more details). They used the open-source Cortex library to handle deployment and management of ML inference pipeline endpoints, and launching and deployment of the Amazon EKS clusters. Each of these models were packaged up into Docker containers—model files were stored in Amazon S3 and model images were stored in Amazon Elastic Container Registry (Amazon ECR)—and deployed as Cortex Realtime APIs. Versions of the model containers that run on CPU and GPU were created to provide flexibility for the type of compute hardware. In the future, if additional models or model pipelines need to be added, they can simply create additional Cortex Realtime APIs.
They then constructed inference pipelines by composing together the Cortex Realtime model APIs into Cortex Realtime pipeline APIs. A single Realtime pipeline API consisted of calling a sequence of Realtime model APIs. The Consumer Lambda functions treated a pipeline API as a black box, using a single API call to retrieve the final inference output for an image. Two pipelines were created: a 2D pipeline and a 3D pipeline.
The 2D pipeline combines a decoding preprocessing step, object detection using a custom Yolo model to locate the athlete and produce bounding boxes, and finally a custom HRNet model for creating 2D key points for pose estimation.
{kind=link}
The 3D pipeline combines a decoding preprocessing step, object detection using a custom Yolo model to locate the athlete and produce bounding boxes, and finally a 3DMPPE model for creating 3D key points for pose estimation.
{kind=link}
After generating inferences on a batch of frames, each pipeline also includes a separate postprocessing Realtime Cortex endpoint that generates three main outputs:
Aggregated body key points data into a single CSV file
BMA calculations (such as acceleration)
Visual overlay of key points added to each frame in an image file
The Collector Lambda function submits the appropriate metadata associated with a particular video, such as the frame IDs and S3 locations of the pose estimation inference outputs, to the endpoint to generate these postprocessing outputs.
Cortex is designed to be integrated with Amazon EKS, and only requires a cluster configuration file and a simple command to launch a Kubernetes cluster:
Another lever for performance tuning was the instance configuration for the compute clusters. Three tiers were created with varying mixes of M5 and G4dn instances, codified as .yaml files with specifications such as cluster name, Region, and instance configuration and mix. M5 instances are lower-cost CPU-based and G4dn are higher cost GPU-based to provide some cost/performance tradeoffs.
Operational monitoring
To maintain operational logging standards, all Lambda functions include code to record and ingest logs via Amazon Kinesis Data Firehose. For example, every frame batch processed from the Submitter Lambda function is logged with the timestamp, name of action, and Lambda function response JSON and saved to Amazon S3. The following diagram illustrates this step in the architecture.
{kind=link}
Deployment
Deployment is handled using AWS SAM, an open-source framework for building serverless applications in AWS. AWS SAM enables infrastructure design, including functions, APIs, databases, and event source mappings to be codified and easily deployed in new AWS environments. During deployment, the AWS SAM syntax is translated into AWS CloudFormation to handle the infrastructure provisioning.
A template.yaml file contains the infrastructure specifications along with tunable parameters, such as Kinesis Data Streams latency levers detailed in the preceding sections. A samconfig.toml file contains deployment parameters such as stack name, S3 bucket name where application files like Lambda function code is stored, and resource tags for tracking cost. A deploy.sh shell script with the simple commands is all that is required to build and deploy the entire template:
User work flow
To sum up, after the infrastructure has been deployed, you can follow this workflow to get started:
Create an Intel 3DAT client using the client library.
Use the API to create a new instance of a pipeline corresponding to the type of processing that is required, such as one for 3D pose estimation.
Create a new instance of a project, passing in the cluster ARN and Kinesis queue ARN.
Create a new instance of a pipeline parameter set.
Create a new instance of pipeline parameters that map to the pipeline parameter set.
Create a new user group that is associated with a project ID and a pipeline parameter set ID.
Create a new user that is associated with the user group.
Upload a .zip file of videos to Amazon S3 using a presigned S3 URL generated by the upload function in the job API.
Submit a create_job API call, with job parameters that specify location of the video files. This starts the processing job.
Conclusion
The application is now live and ready to be tested with athletes and coaches alike. Intel OTG is excited to make innovative pose estimation technology using computer vision accessible for a variety of users, from developers to athletes to software vendor partners.
The AWS team is passionate about helping customers like Intel OTG accelerate their ML journey, from the ideation and discovery stage with ML Solutions Lab to the hardening and deployment stage with AWS ML ProServe. We will all be watching closely at the 2021 Tokyo Olympics this summer to envision all the progress that ML can unlock in sports.
Get started today! Explore your use case with the services mentioned in this post and many others on the AWS Management Console.
About the Authors
Han Man is a Senior Manager- Machine Learning & AI at AWS based in San Diego, CA. He has a PhD in engineering from Northwestern University and has several years of experience as a management consultant advising clients in manufacturing, financial services, and energy. Today he is passionately working with customers from a variety of industries to develop and implement machine learning & AI solutions on AWS. He enjoys following the NBA and playing basketball in his spare time.
{kind=link}
Iman Kamyabi is an ML Engineer with AWS Professional Services. He has worked with a wide range of AWS customers to champion best practices in setting up repeatable and reliable ML pipelines.
{kind=link}
Jonathan Lee is the Director of Sports Performance Technology, Olympic Technology Group at Intel. He studied the application of machine learning to health as an undergrad at UCLA and during his graduate work at University of Oxford. His career has focused on algorithm and sensor development for health and human performance. He now leads the 3D Athlete Tracking project at Intel.
{kind=link}
Nelson Leung is the Platform Architect in the Sports Performance CoE at Intel, where he defines end-to-end architecture for cutting-edge products that enhance athlete performance. He also leads the implementation, deployment and productization of these machine learning solutions at scale to different Intel partners.
{kind=link}
Troy Squillaci is a DecSecOps engineer at Intel where he delivers professional software solutions to customers through DevOps best practices. He enjoys integrating AI solutions into scalable platforms in a variety of domains.
{kind=link}
Paul Min is an Associate Solutions Architect Intern at Amazon Web Services (AWS), where he helps customers across different industry verticals advance their mission and accelerate their cloud adoption. Previously at Intel, he worked as a Software Engineering Intern to help develop the 3D Athlete Tracking Cloud SDK. Outside of work, Paul enjoys playing golf and can be heard singing.
{kind=link}
Read MoreAWS Machine Learning Blog