

{kind=link}
Organizations of all sizes are striving to grow their business, improve efficiency, and serve their customers better than ever before. Even though the future is uncertain, a data-driven, science-based approach can help anticipate what lies ahead to successfully navigate through a sea of choices.
Every industry uses time series forecasting to address a variety of planning needs, including but not limited to:
Developing a cash flow projection based on future expected revenues and expenses
Estimating how many items to manufacture or purchase from suppliers to meet future demand
Knowing where to stock inventory in retail settings to meet on-shelf availability while also minimizing stock-outs and product waste
In wholesale or ecommerce settings, knowing where to position inventory within the supply chain network to maximize regional availability while also minimizing final mile delivery costs
Having a system for detecting outliers in which future actuals far exceed or fall short of the expected plan
Establishing specialized workforces in response to anticipated customer foot traffic, call center operations, manufacturing plans, and other similar workforce demand curves
In this post, we outline five best practices to get started with Amazon Forecast, and apply the power of highly-accurate machine learning (ML) forecasting to your business.
Why Amazon Forecast
AWS offers a fully managed time series forecasting service called Amazon Forecast that allows you to generate and maintain ongoing automated time series forecasts without requiring ML expertise. In addition, you can build and deploy repeatable forecasting operations without the need to write code, build ML models, or manage infrastructure.
The capabilities of Forecast allow it to serve a wide range of customer roles, from analysts and supply chain managers to developers and ML experts. There are several reasons why customers favor Forecast: it offers high accuracy, repeatable results, and the ability to self-serve without waiting on specialized technical resource availability. Forecast is also selected by data science experts because it provides highly accurate results, based on an ensemble of self-tuned models, and the flexibility to experiment quickly without having to deploy or manage clusters of any particular size. Its ML models also make it easier to support forecasts for a large number of items, and can generate accurate forecasts for cold-start items with no history.
Five best practices when getting started with Forecast
Forecast provides high accuracy and quick time-to-market for developers and data scientists. Although developing highly accurate time series models has been made easy, this post provides best practices to speed up your onboarding and time to value. A little rigor and perhaps a couple of rounds of experimentation must be applied to reach success. A successful forecasting journey depends on multiple factors, some subtle.
These are some key items you should consider when starting to work with Forecast.
Start simple
As shown in the following flywheel, consider beginning with a simple model that uses a target time series dataset to develop a baseline as you propose your first set of input data. Subsequent experiments can add in other temporal features and static metadata with a goal of improving model accuracy. Each time a change is made, you can measure and learn how much the change has helped, if at all. Depending on your assessment, you may decide to keep the new set of features provided, or pivot and try another option.
{kind=link}
Focus on the outliers
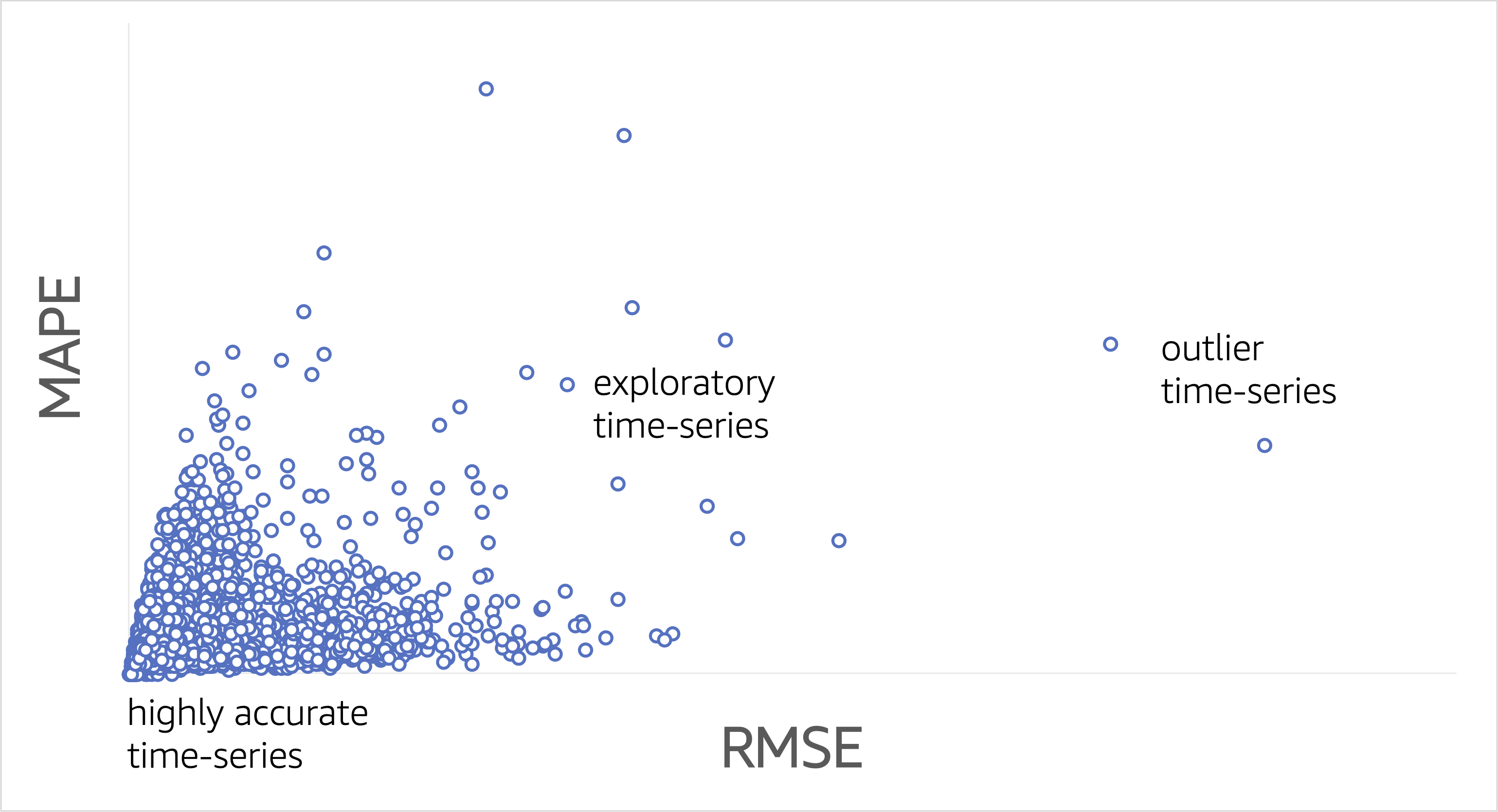
With Forecast, you can obtain accuracy statistics for the entire dataset. It’s important to recognize that although this top-level statistic is interesting, it should be viewed as being only directionally correct. You should concentrate on item-level accuracy statistics rather than top-level statistics. Consider the following scatterplot as a guide. Some of the items in the dataset will have high accuracy; for these no action is required.
{kind=link}
While building a model, you should explore some of the points labeled as “exploratory time-series.” In these exploratory cases, determine how to improve accuracy by incorporating more input data, such as price variations, promotional spend, explicit seasonality features, and the inclusion of local, market, global, and other real-world events and conditions.
Review predictor accuracy before creating forecasts
Don’t create future dated forecasts with Forecast until you have reviewed prediction accuracy during the backtest period. The preceding scatterplot illustrates time series level accuracy, which is your best indication for what future dated predictions will look like, all other things being the same. If this period isn’t providing your required level of accuracy, don’t proceed with the future dated forecast operation, because this may lead to inefficient spend. Instead, focus on augmenting your input data and trying another round at the innovation flywheel, as discussed earlier.
Reduce training time
You can reduce training time through two mechanisms. First, use Forecast’s retrain function to help reduce training time through transfer learning. Second, prevent model drift with predictor monitoring by training only when necessary.
Build repeatable processes
We encourage you not to build Forecast workflows through the AWS Management Console or using APIs from scratch until you have at least evaluated our AWS samples GitHub repo. Our mission with GitHub samples is to help remove friction and expedite your time-to-market with repeatable workflows that have already been thoughtfully designed. These workflows are serverless and can be scheduled to run on a regular schedule.
Visit our official GitHub repo, where you can quickly deploy our solution guidance by following the steps provided. As shown in the following figure, the workflow provides a complete end-to-end pipeline that can retrieve historical data, import it, build models, and produce inference against the models—all without needing to write code.
The following figure offers a deeper view into just one module, which is able to harvest historical data for model training from a myriad of database sources that are supported by Amazon Athena Federated Query.
Get started today
You can implement a fully automated production workflow in a matter of days to weeks, especially when paired with our workflow orchestration pipeline available at our GitHub sample repository.
This re:Invent video highlights a use case of a customer who automated their workflow using this GitHub model:
Forecast has many built-in capabilities to help you achieve your business goals through highly accurate ML-based forecasting. We encourage you to contact your AWS account team if you have any questions and let them know that you would like to speak with a time series specialist in order to provide guidance and direction. We can also offer workshops to assist you in learning how to use Forecast.
We are here to support you and your organization as you endeavor to automate and improve demand forecasting in your company. A more accurate forecast can result in higher sales, a significant reduction in waste, a reduction in idle inventory, and ultimately higher levels of customer service.
Take action today; there is no better time than the present to begin creating a better tomorrow.
About the Author
Charles Laughlin is a Principal AI/ML Specialist Solution Architect and works inside the Time Series ML team at AWS. He helps shape the Amazon Forecast service roadmap and collaborates daily with diverse AWS customers to help transform their businesses using cutting-edge AWS technologies and thought leadership. Charles holds a M.S. in Supply Chain Management and has spent the past decade working in the consumer packaged goods industry.
{kind=link}
Dan Sinnreich is a Sr. Product Manager for Amazon Forecast. He is focused on democratizing low-code/no-code machine learning and applying it to improve business outcomes. Outside of work, he can be found playing hockey, trying to improve his tennis serve, scuba diving, and reading science fiction.
{kind=link}
Read MoreAWS Machine Learning Blog