

{kind=link}
The future of AI is better AI—designed with ethics and responsibility built in from the start. This means putting the brakes on AI-driven transformation until you have a well-functioning strategy and process in place to ensure your models deliver fair outcomes. Failing to recognize this imperative is a threat to your bottom line. The following post provides a simple framework to follow to keep your business on the right track as you place more trust in algorithms.
AI is inherently sociotechnical. AI systems represent the interconnectedness of humans and technology. They are designed to be used by and to inform humans within specific contexts, and the speed and scale of AI means that any lack of responsibility—such as bias, safety, privacy, scientific excellence etc—will also replicate at that same speed and scale. Without ethics and responsibility built in by design, AI systems lack the critical “inputs” or societal context that enable long term success.
Lawsuits stemming from AI systems that are biased towards certain groups are stacking up. In August 2020, IBM was forced to settle a lawsuit with the city of Los Angeles for misappropriating data it collected for its weather channel app. Health services company, Optum, is being investigated by regulators for creating an algorithm that allegedly recommended that doctors and nurses pay more attention to white patients than to sicker black patients. And Facebook, which granted Cambridge Analytica, a political firm, access to the personal data of more than 50 million people, is buried in legal work. Google has also run into its share of issues with algorithms making egregious mistakes.
While lawsuits are real, the foundational reason ethical AI is critical to your bottom line is trust. Without it, increasingly, consumers will ignore you and choose a brand they do trust. Research from Kantar, which runs one of the largest global brand equity studies (4 million consumers, 18,000 brands, across 50 markets), revealed that almost 9% of a brand’s equity is driven by corporate reputation, of which responsibility is a key attribute. Over the last decade, the importance of responsibility to consumers in relation to making brand choices has tripled.
The study stated brands perceived to be among the world’s most trusted and responsible shared three crucial factors that proved particularly important for building consumer trust and confidence, even when a brand might be new to a market. These are:
Honesty and openness
Respect and inclusion
Identifying with and caring for customers
Brands that develop these associations more strongly tend to outperform their competitors in defending and growing their brand value.
{kind=link}
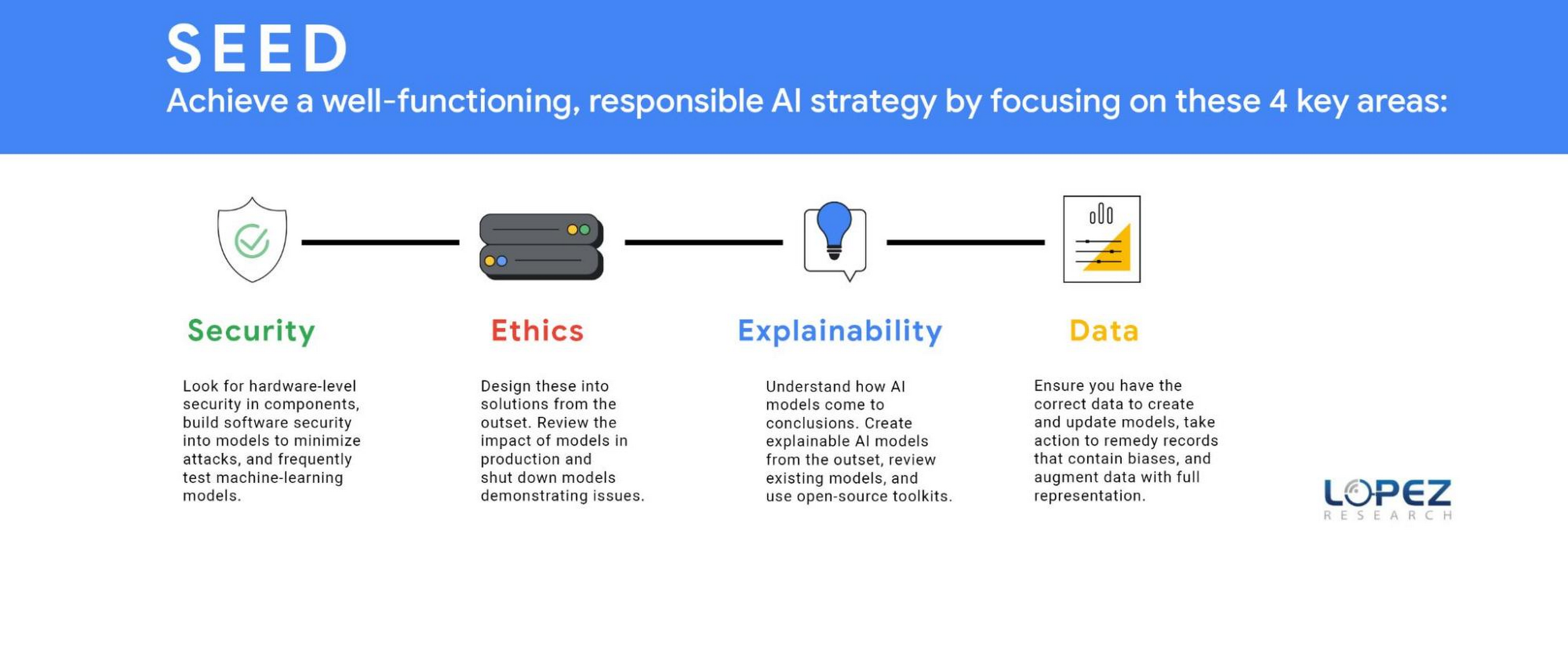
Technology and business leaders need to focus on four areas to accomplish a well-functioning ethical AI strategy. Lopez Research refers to this group of tasks as SEED, which stands for security, ethics, explainability, and data (SEED). Each of these topics could be an article in itself, but this post will define several essential components.
SECURITY (S)
It might not seem obvious, but a robust AI strategy requires an embedded security strategy. Companies should look for hardware-level security in components such as GPUs and CPUs. IT leaders should build software security into models to minimize attacks such as poisoning, evasion, deepfakes, backdoors, and model extraction. The threat of adversarial data poisoning attacks machine learning models by maliciously introducing inaccurate data designed to corrupt the model’s ability to be accurate. Another security threat is model extraction, also known as model cloning, where a hacker finds a way to either reconstruct a black-box machine learning model or extract the training data. The first line of defense against all security attacks is to design security at the outset, but the next best step is to frequently test models to ensure they are operating as planned. Business leaders, data science experts, and IT leaders must work together to regularly review the outcomes of AI models.
ETHICS (E)
Today, organizations must understand that ethics should be designed into the solution at its outset. The ethics process starts with defining the potential positive and negative outcomes of the model that your business is creating. Once the team has evaluated potential harmful effects, which means unpacking the systems, beliefs, power hierarchies and dynamics that interconnect with the technology, it’s your responsibility to eliminate or minimize the impact of these outcomes. It’s also critically important to review the impact of models in production and shut down models demonstrating issues. An example of this was the public beta release of the Tay chatbot that Microsoft deployed and rapidly shut down because it propagated negative biases.
Yet, many organizations aren’t taking this action. The FICO study revealed that 93% of companies said responsible AI was critical for success but only 33% of these companies were measuring AI model outputs to ensure these models were operating as expected (measuring for model drift). Another survey by Pew Research revealed that 68% believe that ethical principles focused primarily on the public good will not be employed in most AI systems by 2030.
Regulations may turn this tide, regardless of whether organizations plan to adopt an ethical AI framework. Laws governing the ethical use of data in AI are expected to be finalized as soon as 2022, such as the European Commission’s proposed legal framework for AI. Organizations that start with ethical use of AI in mind will be better positioned to deal with customer privacy concerns and regulatory compliance.
EXPLAINABILITY(E)
As models have become more sophisticated, it’s also become increasingly difficult to explain why a model created a specific outcome. In the FICO Responsible AI report, 65% of respondents could not explain how specific AI model decisions or predictions are made, and only 35% said their organization made an effort to use AI in a way that was transparent and accountable. However, it’s never been more important to clarify how AI models came to conclusions such as why a loan was denied, why a particular strategy should be implemented, and how AI selected a set of resumes to review for a position. The goal is to create an explainable AI model from the outset but many of today’s models lack this capability. Every business should review its existing models and use open-source toolkits that can be found on Github.com that support the interpretability and explainability of machine learning models.
Keep in mind that explainability isn’t one-size-fits-all. Different stakeholders need different types of information. Much of explainability to date has focused on “opening the black box” which gets equated to information that is only useful for other data scientists. That’s important, but it doesn’t help the line of business users whose workflows AI is integrated into, or end users who deserve information about how decisions are made; or policymakers who don’t have data science backgrounds, and so on.
DATA (D)
An equally important item in ethics is data. Ethics starts with ensuring you have the correct data to create and update models. Three main issues include representative data, inherent biases within existing data, and inaccurate data. A critical issue that most companies miss in creating models is that current data sets frequently lack full market representation. A recent Capgemini Research Institute report revealed that 65% of executives “were aware of the issue of discriminatory bias” with these systems.
Awareness is the first step, but organizations must take action to remedy this issue. Historical data may no longer serve a company’s current needs for model creation. Historical records may contain biases against certain groups. For example, historical criminal data records show an imbalance in ethnic groups’ incarceration, which would lead to model biases. Additionally, laws and societal norms also change. Certain groups were prosecuted for sexual preference in the past, but today this information would create an inaccurate model.
Companies have also discovered that using demographic data, a common practice in marketing, can also lead to model bias. For example, individuals that primarily used cash for transactions and others that lived in specific zip codes were at a disadvantage in banking models to determine creditworthiness. To minimize these issues, a company needs to augment its data with full representation in areas such as ethnicity, gender, age, behavioral and economic profiles.
{kind=link}
Design AI models with a continuous feedback loop
Another, more prominent, yet tricky issue is data accuracy. As the adage says, garbage in, equals garbage out. The least appreciated but arguably the most essential component of the AI model lifecycle is ensuring the model has accurate data at all times. Inaccurate data from either poor data hygiene or data that was tampered with for security purposes can cause model failures. Organizations need to invest the time and resources to ensure they have the correct data. Data privacy is another key element that businesses must address, but the concepts of data privacy, sovereignty, and security are significant enough that we will come back to this in a separate article.
Overall, it’s clear that while we may have an abundance of data, it most likely doesn’t represent what we want to model for the future. A successful AI strategy is an ethical AI strategy that requires the organization to be thoughtful in its model creation by ensuring it has a broad representation of accurate data and testing the outcomes to ensure the models are secure and operating as expected.
Organizations that define an AI model lifecycle with a continuous feedback loop will reap the benefits of better intelligence. This will increasingly mean stronger, longer lasting trust with customers and staying on the right side of new laws and regulations.
Cloud BlogRead More