

{kind=link}
Amazon SageMaker JumpStart provides pre-trained, open-source models for a wide range of problem types to help you get started with machine learning (ML). JumpStart also provides solution templates that set up infrastructure for common use cases, and executable example notebooks for ML with Amazon SageMaker.
As a business user, you get to do the following with JumpStart solutions:
Explore the solutions and evaluate which are a good match for your business needs.
Launch solutions with a single click in Amazon SageMaker Studio. This launches an AWS CloudFormation template to create the required resources.
Modify the solution to meet your needs with access to underlying notebook and model assets.
Delete the acquired resources once done.
This post focuses on the five ML solutions that were recently added to address five different business challenges. As of this writing, JumpStart offers 23 business solutions varying from detecting fraud in financial transactions to recognizing handwriting. The number of solutions that are offered through JumpStart increase on a regular basis as more solutions are added to it.
Solution overview
The five new solutions are as follows:
Price optimization – Offers customizable ML models to help you make optimal decisions for setting the price of your product or service in order to achieve your business objective, such as maximizing revenue, profit, or other custom metrics.
Bird species prediction – Shows how you can train and fine-tune an object detection model. It demonstrates model tuning through training image augmentation, and charts the accuracy improvements that occur across the iterations (epochs) of the training job.
Lung cancer survival prediction – Shows how you can feed 2D and 3D radiomic features and patient demographics to an ML algorithm to predict a patient’s lung cancer survival chances. The results from this prediction can help providers take appropriate proactive measures.
Financial payment classification – Demonstrates how to train and deploy an ML model to classify financial transactions based on transaction information. You can also use this solution as an intermediate step in fraud detection, personalization, or anomaly detection.
Churn prediction for mobile phone customers – Demonstrates how to quickly develop a churn prediction model using a mobile call transaction dataset. This is a simple example for users that are new to ML.
Prerequisites
To use these solutions, make sure that you have access to Studio with an execution role that allows you to run SageMaker functionality. For your user role within Studio, make sure that the SageMaker Projects and JumpStart option is turned on.
In the following sections, we go through each of the five new solutions and discuss how it works in detail, along with some recommendations on how you can use it for your own business needs.
Price optimization
Businesses like using various levers to fetch the best results. For example, the price of a product or a service is a lever that a business can control. The question is how to decide what price to set a product or service at, in order to maximize a business objective such as profit or revenue.
This solution provides customizable ML models to help you make optimal decisions for setting the price of your product or service in order to achieve your objective, such as maximizing revenue, profit, or other custom metrics. The solution uses ML and causal inference approaches to learn price-volume relations from historical data, and is able to make dynamic price recommendations in real time to optimize the custom objective metrics.
The following screenshot shows the sample input data.
{kind=link}
The solution includes three parts:
Price elasticity estimation – This is estimated by causal inference via a double ML algorithm
Volume forecast – This is forecasted using the Prophet algorithm
Price optimization – This is achieved by a what-if simulation through different price scenarios
The solution provides the recommended price for the next day for maximizing revenue. In addition, the outputs include the estimated price elasticity, which is a value indicating the effect of price on volume, and a forecast model, which is able to forecast the next day’s volume. The following chart shows how a causal model that incorporated the calculated price elasticity performs much better under a what-if analysis (with large deviations from behavior price) than a predictive model that uses Prophet for forecasting volume using time series data.
{kind=link}
You could apply this solution to your business for the following use cases:
Determine the optimal price of goods for a retail store
Estimate the effect of discount coupons on customer purchases
Predict the effect of various incentive methods in any business
Bird species prediction
There are several computer vision (CV) applications for businesses today. One of those applications is object detection, where an ML algorithm detects the location of an object in an image by drawing a bounding box around it, and identifies the type of object it is. Learning how to apply an object detection model and fine-tune it can be of great value to an organization that has CV needs.
This solution provides an example of how to translate bounding box specifications when providing images to the SageMaker algorithm. This solution also demonstrates how to improve an object detection model by adding training images that are flipped horizontally (mirror images).
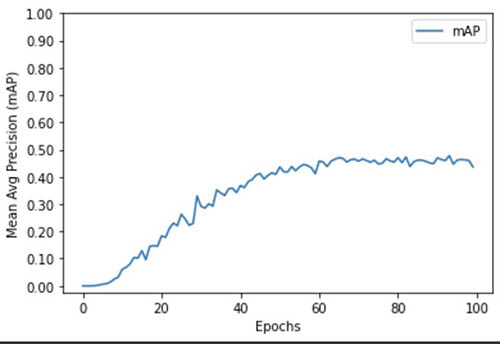
A notebook is provided for experimenting with object detection challenges when there are a large number of classes (200 bird species). The notebook also shows how to chart the accuracy improvements that occur across the epochs of the training job. The following image shows example images from the birds dataset.
{kind=link}
This solution contains five steps:
Prepare the data, including download and RecordIO file generation.
Create and train an object detection model.
Deploy an endpoint and evaluate model performance.
Create and train an object detection model again with the expanded dataset.
Deploy an endpoint and evaluate the expanded model performance.
You get the following as output:
Object detection results with bonding boxes against your test image
A trained object detection model
A trained object detection model with an additional expanded (flipped) dataset
Two separate endpoints deployed with one of each model
The following chart shows model improvement against model iterations (epochs) during training.
{kind=link}
The following examples are output from two test images.
{kind=link}
{kind=link}
You could apply this solution to your business for the following use cases:
Detect objects on a conveyer belt in a packaging industry
Detect toppings on a pizza
Implement supply chain operational applications that involve object detection
Lung cancer survival prediction
COVID-19 brought a lot more attention to lung-related medical challenges. It has also put a lot of pressure on hospitals, doctors, nurses, and radiologists. Imagine a possibility where you can apply ML as a powerful tool to assist medical practitioners and help them speed up their work. In this solution, we show how 2D and 3D radiomic features and patient demographics can be fed to an ML algorithm to predict a patient’s lung cancer survival chances. Results from this prediction can help providers take appropriate proactive measures.
This solution demonstrates how to build a scalable ML pipeline for the Non-Small Cell Lung Cancer (NSCLC) Radiogenomics dataset, which consists of RNA sequencing data, clinical data (reflective of EHR data), and medical images. Using multiple types of data to create a machine model is referred to as multi-modal ML. This solution predicts survival outcome of patients diagnosed with non-small cell lung cancer.
The following image shows an example of the input data from the Non-Small Cell Lung Cancer (NSCLC) Radiogenomics dataset.
{kind=link}
As part of the solution, total RNA was extracted from the tumor tissue and analyzed with RNA sequencing technology. Although the original data contains more than 22,000 genes, we keep 21 genes from 10 highly coexpressed gene clusters (metagenes) that were identified, validated in publicly available gene-expression cohorts, and correlated with prognosis.
The clinical records are stored in CSV format. Each row corresponds to a patient, and the columns contain information about the patients, including demographics, tumor stage, and survival status.
For genomic data, we keep 21 genes from 10 highly coexpressed gene clusters (metagenes) that were identified, validated in publicly available gene-expression cohorts, and correlated with prognosis.
For medical imaging data, we create patient-level 3D radiomic features that explain the size, shape, and visual attributes of the tumors observed in the CT scans. For each patient study, the following steps are performed:
Read the 2D DICOM slice files for both the CT scan and tumor segmentation, combine them to 3D volumes, save the volumes in NIfTI format.
Align CT volume and tumor segmentation so we can focus the computation inside the tumor.
Compute radiomic features describing the tumor region using the pyradiomics library.
Extract 120 radiomic features of eight classes, such as statistical representations of the distribution and co-occurrence of the intensity within tumorous region of interest, and shape-based measurements describing the tumor morphologically.
To create a multi-modal view of a patient for model training, we join the feature vectors from three modalities. We then process the data. First, we normalize the range of independent features using feature scaling. Then we perform principal component analysis (PCA) on the features to reduce the dimensionality and identify the most discriminative features that contribute 95% variance in the data.
This results in a dimensionality reduction from 215 features down to 45 principal components, which constitute features for the supervised learner.
The solution produces an ML model that predicts NSCLC patients’ survival status (dead or alive) in a form of probability. Besides the model and prediction, we also generate reports to explain the model. The medical imaging pipeline produces 3D lung CT volumes and tumor segmentation for visualization purposes.
You can apply this solution to healthcare and life sciences use cases.
Financial payment classification
Taking all financial transactions of a business or a consumer and organizing them into various categories can be quite helpful. It can help the user learn how much they have spent in which category, and it can also raise alerts when transactions or spending in a given category goes up or down unexpectedly.
This solution demonstrates how to train and deploy an ML model to classify financial transactions based on transaction information. Many banks provide this as a service to give their end-users an overview of their spending habits. You can also use this solution as an intermediate step in fraud detection, personalization, or anomaly detection. We use SageMaker to train and deploy an XGBoost model with the required underlying infrastructure.
The synthetic dataset that we to demonstrate this solution has the following features:
transaction_category – The category of the transaction, out of the following 19 options: Uncategorized, Entertainment, Education, Shopping, Personal Care, Health and Fitness, Food and Dining, Gifts and Donations, Investments, Bills and Utilities, Auto and Transport, Travel, Fees and Charges, Business Services, Personal Services, Taxes, Gambling, Home, and Pension and insurances.
receiver_id – An identifier for the receiving party. The identifier consists of 16 numbers.
sender_id – An identifier for the sending party. The identifier consists of 16 numbers.
amount – The amount that is transferred.
timestamp – The timestamp of the transaction in YYYY-MM-DD HH:MM:SS format.
The first five observations of the dataset are as follows:
{kind=link}
For this solution, we use XGBoost, a popular and efficient open-source implementation of the gradient boosted trees algorithm. Gradient boosting is a supervised learning algorithm that attempts to accurately predict a target variable by combining an ensemble of estimates from a set of simpler and weaker models. Its implementation is available in the SageMaker built-in algorithms.
The financial payment classification solution contains four steps:
Prepare the data.
Build a feature store.
Create and train an XGBoost model.
Deploy an endpoint and evaluate model performance.
We get the following output:
A trained XGBoost model based on our example dataset
A SageMaker endpoint that can predict the transaction category
After running this solution, you should see a classification report similar to the following.
{kind=link}
Possible applications for your business include the following:
Various financial applications in retail and investment banking
When transactions need to be classified in any use case (not just financial)
Churn prediction for mobile phone customers
Predicting customer churn is a very common business need. Numerous studies show that the cost of retaining an existing customer is much less than acquiring a new customer. The challenge often comes from businesses having a tough time understanding why a customer is churning, or building a model that predicts churning.
In this example, users that are new to ML can experience how a churn prediction model can be quickly developed using a mobile call transaction dataset. This solution uses SageMaker to train and deploy an XGBoost model on a customer profile dataset to predict whether a customer is likely to leave a mobile phone operator.
The dataset this solution uses is publicly available and is mentioned in the book Discovering Knowledge in Data by Daniel T. Larose. It is attributed by the author to the University of California Irvine Repository of Machine Learning Datasets.
This dataset uses the following 21 attributes to describe the profile of a customer of an unknown US mobile operator.
State: the US state in which the customer resides, indicated by a two-letter abbreviation; for example, OH or NJ
Account Length: the number of days that this account has been active
Area Code: the three-digit area code of the corresponding customer’s phone number
Phone: the remaining seven-digit phone number
Int’l Plan: whether the customer has an international calling plan: yes/no
VMail Plan: whether the customer has a voice mail feature: yes/no
VMail Message: the average number of voice mail messages per month
Day Mins: the total number of calling minutes used during the day
Day Calls: the total number of calls placed during the day
Day Charge: the billed cost of daytime calls
Eve Mins, Eve Calls, Eve Charge: the billed cost for calls placed during the evening
Night Mins, Night Calls, Night Charge: the billed cost for calls placed during nighttime
Intl Mins, Intl Calls, Intl Charge: the billed cost for international calls
CustServ Calls: the number of calls placed to Customer Service
Churn?: whether the customer left the service: true/false
This solution contains three stages:
Prepare the data.
Create and train an XGBoost model.
Deploy an endpoint and evaluate model performance.
We get the following output:
A trained XGBoost model based on our example dataset to predict user churn
A SageMaker endpoint that can predict user churn
This model helps estimate how many of the 5,000 mobile phone customers are likely to stop using their current mobile phone operator.
The following chart shows a probability distribution of the churn as an output from the model.
{kind=link}
You could apply this to your business for the following use cases:
Predict customer churn in your own business
Classify which customers may open your marketing email and who will not (binary classification)
Predict which students are likely to drop out from a course
Clean up resources
After you’re done running a solution in JumpStart, make sure to choose Delete all resources so all the resources that you have created in the process are deleted and your billing is stopped.
{kind=link}
Summary
This post showed you how to solve various business problems by applying ML, based on JumpStart solutions. Although this post focused on the five new solutions that were recently added to JumpStart, there are a total of 23 available solutions. We encourage you to log in to Studio and look at the JumpStart solutions yourselves and start deriving immediate value out of them. For more information, refer to Amazon SageMaker Studio and SageMaker JumpStart.
Note: If you don’t see all of the above five solutions in the JumpStart console of your AWS region, please wait for a week and check again. We are releasing them to various regions in a phased manner.
About the Authors
Dr. Raju Penmatcha is an AI/ML Specialist Solutions Architect in AI Platforms at AWS. He works on the low-code/no-code suite of services in SageMaker that help customers easily build and deploy machine learning models and solutions. When not helping customers, he likes traveling to new places.
{kind=link}
Manan Shah is a Software Development Manager at Amazon Web Services. He is an ML enthusiast and focuses on building no-code/low-code AI/ML products. He strives to empower other talented, technical people to build great software.
{kind=link}
Read MoreAWS Machine Learning Blog