

{kind=link}
For the past few decades, physician burnout has been a challenge in the healthcare industry. Although patient interaction and diagnosis are critical aspects of a physician’s job, administrative tasks are equally taxing and time-consuming. Physicians and clinicians must keep a detailed medical record for each patient. That record is stored in the hospital electronic health record (EHR) system, a database that contains the records of every patient in the hospital. To maintain these records, physicians often spend multiple hours each day to manually enter data into the EHR system, resulting in lower productivity and increased burnout.
Physician burnout is one of the leading factors that lead to depression, fatigue, and stress for doctors during their careers. In addition, it can lead to higher turnover, reduced productivity, and costly medical errors, affecting people’s lives and health.
In this post, you learn the importance of voice assistants and how they can automate administrative tasks for doctors. We also walk through creating a custom voice assistant using PocketSphinx and Amazon Lex.
Voice assistants as a solution to physician burnout
Voice assistants are now starting to automate the vital yet manual parts of patient care. They can be a powerful tool to help doctors save time, reduce stress, and spend more time focusing on the patient versus the administrative requirements of clinical documentation.
Today, voice assistants are becoming more available as natural language processing models advance, errors decrease, and development becomes more accessible for the average developer. However, most devices are limited, so developers must often build their own customized versions.
As Solutions Architects working in the healthcare industry, we see a growing trend towards the adoption of voice assistants in hospitals and patient rooms.
In this post, you learn how to create a custom voice assistant using PocketSphinx and Amazon Lex. With our easy-to-set-up and managed services, developers and innovators can hit the ground running and start developing the devices of the future.
Custom voice assistant solution architecture
The following architecture diagram presents the high-level overview of our solution.
{kind=link}
In our solution, we first interface with a voice assistant script that runs on your computer. After the wake word is recognized, the voice assistant starts recording what you say and sends the audio to Amazon Lex, where it uses an AWS Lambda function to retrieve dummy patient data stored in Amazon DynamoDB. The sensor data is generated by another Python script, generate_data.py, which you also run on your computer.
Sensor types include blood pressure, blood glucose, body temperature, respiratory rate, and heart rate. Amazon Lex sends back a voice message, and we use Amazon Polly, a service that turns text into lifelike speech, to create a consistent experience.
Now you’re ready to create the components needed for this solution.
Deploy your solution resources
You can find all the files of our custom voice assistant solution on our GitHub repo. Download all the files, including the PocketSphinx model files downloaded from their repo.
You must deploy the DynamoDB table and Lambda function directly by choosing Launch Stack.
The AWS CloudFormation stack takes a few minutes to complete. When it’s complete, you can go to the Resources tab to check out the Lambda function and DynamoDB table created. Note the name of the Lambda function because we reference it later when creating the Amazon Lex bot.
{kind=link}
Create the Amazon Lex bot
When the CloudFormation stack is complete, we’re ready to create the Amazon Lex bot. For this post, we use the newer V2 console.
On the Amazon Lex console, choose Switch to the new Lex V2 console.
In the navigation pane, choose Bots.
Choose Create bot.
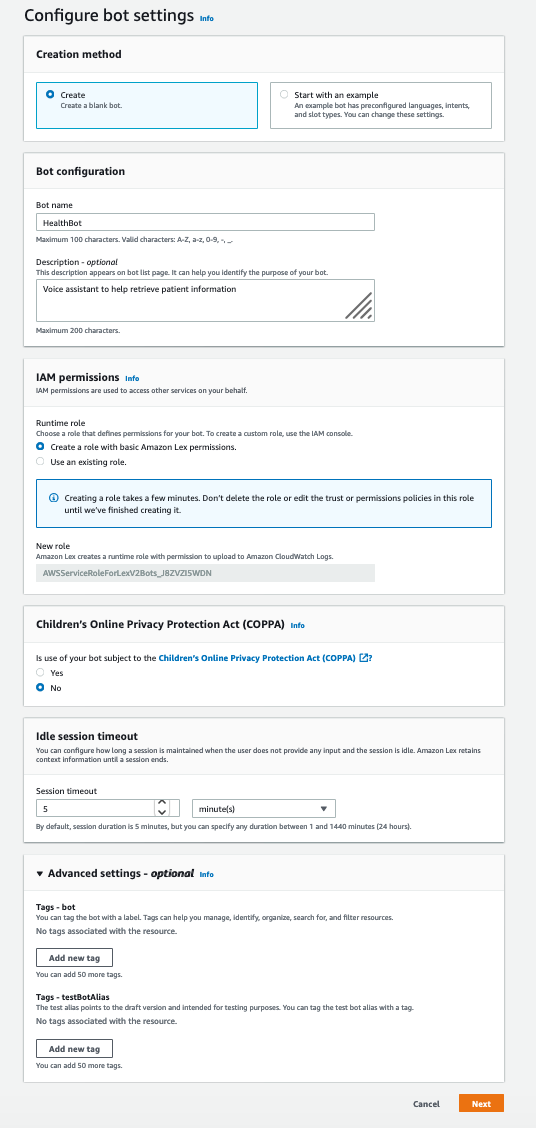
For Bot name, enter Healthbot.
For Description, enter an optional description.
For Runtime role, select Create a role with basic Amazon Lex permissions.
In the Children’s Online Privacy Protection Act (COPPA) section, select No.
Keep the settings for Idle session timeout at their default (5 minutes).
Choose Next.
{kind=link}
For Voice interaction, choose the voice you want to use.
Choose Done.
Create custom slot types, intents, and utterances
Now we create a custom slot type for the sensors, our intents, and sample utterances.
On the Slot types page, choose Add slot type.
Choose Add blank slot type.
For Slot type name¸ enter SensorType.
Choose Add.
In the editor, under Slot value resolution, select Restrict to slot values.
{kind=link}
Add the following values:
Blood pressure
Blood glucose
Body temperature
Heart rate
Respiratory rate
{kind=link}
Choose Save slot type.
On the Intents page, we have two intents automatically created for us. We keep the FallbackIntent as the default.
Choose NewIntent.
For Intent name, change to PatientData.
{kind=link}
In the Sample utterances section, add some phrases to invoke this intent.
We provide a few examples in the following screenshot, but you can also add your own.
{kind=link}
In the Add slot section, for Name, enter PatientId.
For Slot type¸ choose AMAZON.AlphaNumeric.
For Prompts, enter What is the patient ID?
This prompt isn’t actually important because we’re using Lambda for fulfillment.
{kind=link}
Add another required slot named SensorType.
For Slot type, choose SensorType (we created this earlier).
For Prompts, enter What would you like to know?
Under Code hooks, select Use a Lambda function for initialization and validation and Use a Lambda function for fulfillment.
{kind=link}
Choose Save intent.
Choose Build.
The build may take a few minutes to complete.
Create a new version
We now create a new version with our new intents. We can’t use the draft version in production.
When the build is complete, on the Bot versions page, choose Create version.
Keep all the settings at their default.
Choose Create.
You should now see Version 1 listed on the Bot Versions page.
{kind=link}
Create an alias
Now we create an Alias to deploy.
Under Deployment in the navigation pane, choose Aliases.
Chose Create alias.
For Alias name¸ enter prod.
Associate this alias with the most recent version (Version 1).
{kind=link}
Choose Create.
On the Aliases page, choose the alias you just created.
Under Languages, choose English (US).
{kind=link}
For Source, choose the Lambda function you saved earlier.
For Lambda function version or alias, choose $LATEST.
{kind=link}
Choose Save.
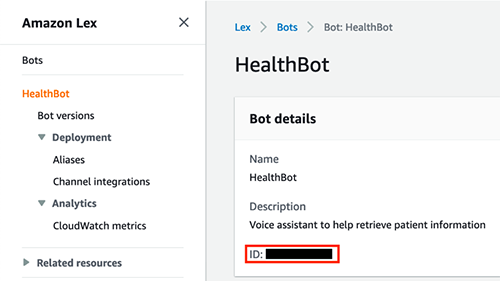
You now have a working Amazon Lex Bot you can start testing with. Before we move on, make sure to save the bot ID and alias ID.
The bot ID is located on the bot details page.
{kind=link}
The alias ID is located on the Aliases page.
{kind=link}
You need to replace these values in the voice assistant script voice_assistant.py later.
In the following sections, we explain how to use PocketSphinx to detect a custom wake word as well as how to start using the solution.
Use PocketSphinx for wake word recognition
The first step of our solution involves invoking a custom wake word before we start listening to your commands to send to Amazon Lex. Voice assistants need an always on, highly accurate, and small footprint program to constantly listen for a wake word. This is usually because they’re hosted on a small, low battery device such as an Amazon Echo.
For wake word recognition, we use PocketSphinx, an open-source continuous speech recognition engine made by Carnegie Mellon University, to process each audio chunk. We decided to use PocketSphinx because it provides a free, flexible, and accurate wake system with good performance.
Create your custom wake word
Building the language model using PocketSphinx is simple. The first step is to create a corpus. You can use the included model that is pre-trained with “Amazon” so if you don’t want to train your own wake word, you can skip to the next step. However, we highly encourage you to test out creating your own custom wake word to use with the voice assistant script.
The corpus is a list of sentences that you use to train the language model. You can find our pre-built corpus file in the file corpus.txt that you downloaded earlier.
Modify the corpus file based on the key phrase or wake word you want to use and then go to the LMTool page.
Choose Browse AND select the corpus.txt file you created
Choose COMPILE KNOWLEDGE BASE.
Download the files the tool created and replace the example corpus files that you downloaded previously.
Replace the KEY_PHRASE and DICT variables in the Python script to reflect the new files and wake word.
{kind=link}
Update the bot ID and bot alias ID with the values you saved earlier in the voice assistant script.
{kind=link}
Set up the voice assistant script on your computer
In the GitHub repository, you can download the two Python scripts you use for this post: generate_data.py and voice_assistant.py.
You must complete a few steps before you can run the script, namely installing the correct Python version and libraries.
Download and install Python 3.6.
PocketSphinx supports up to Python 3.6. If you have another version of Python installed, you can use pyenv to switch between Python versions.
Install Pocketsphinx.
Install Pyaudio.
Install Boto3.
Make sure you use the latest version by using pip install boto3==<version>.
Install the AWS Command Line Interface (AWS CLI) and configure your profile.
If you don’t have an AWS Identity and Access Management (IAM) user yet, you can create one. Make sure you set the Region to the same Region where you created your resources earlier.
{kind=link}
Start your voice assistant
Now that we have everything set up, open up a terminal on your computer and run generate_data.py.
{kind=link}
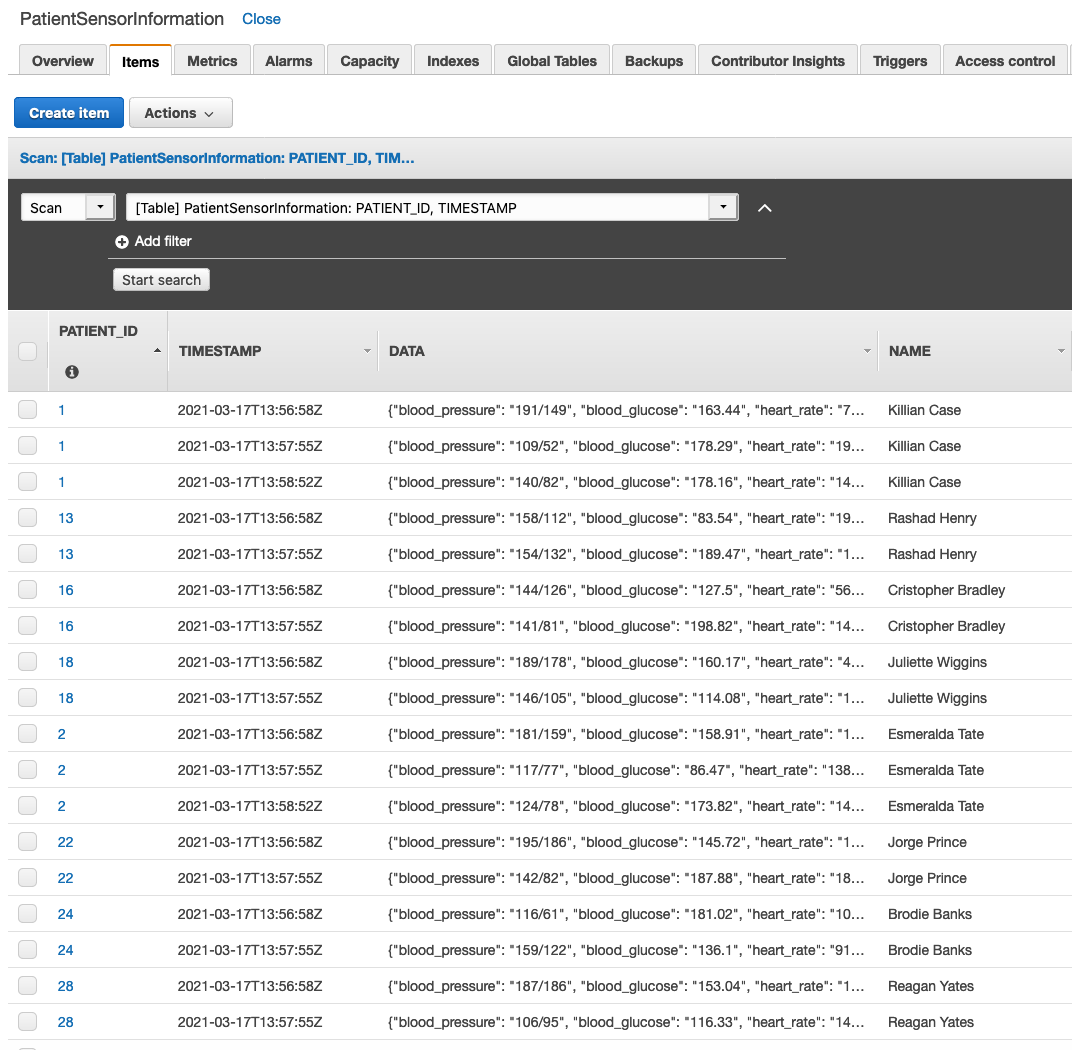
Make sure to run it for at least a minute so that the table is decently populated. Our voice assistant only queries the latest data inserted into the table, so you can stop it after it runs one time. The patient IDs generated are between 0–99, and are asked for later.
Check the table to make sure that data is generating.
{kind=link}
Now you can run voice_assistant.py.
{kind=link}
Your computer is listening for the wake word you set earlier (or the default “Amazon”) and doesn’t start recording until it detects the wake word. The wake word detection is processed using PocketSphinx’s decoder. The decoder continuously checks for the KEYPHRASE or WakeWord in the audio channel.
To initiate the conversation, say the utterance you set in your intent earlier. The following is a sample conversation:
You: Hey Amazon
You: I want to get patient data.
Lex: What is the ID of the patient you wish to get information on?
You: 45
Lex: What would you like to know about John Smith?
You: blood pressure
Lex: The blood pressure for John Smith is 120/80.
Conclusion
Congratulations! You have set up a healthcare voice assistant that can serve as a patient information retrieval bot. Now you have completed the first step towards creating a personalized voice assistant.
Physician burnout is an important issue that needs to be addressed. Voice assistants, with their increasing sophistication, can help make a difference in the medical community by serving as virtual scribes, assistants, and much more. Instead of burdening physicians with menial tasks such as ordering medication or retrieving patient information, they can use innovative technologies to relieve themselves of the undifferentiated administrative tasks.
We used PocketSphinx and Amazon Lex to create a voice assistant with the simple task of retrieving some patient information. Instead of running the program on your computer, you can try hosting this on any small device that supports Python, such as the Raspberry Pi.
Furthermore, Amazon Lex is HIPAA-eligible, which means that you can integrate it with existing healthcare systems by following the HL7/FHIR standards.
Personalized healthcare assistants can be vital in helping physicians and nurses care for their patients, and retrieving sensor data is just one of the many use cases that can be viable. Other use cases such as ordering medication and scribing conversations can benefit doctors and nurses across hospitals.
We want to challenge you to try out Amazon Lex and see what you can make!
About the Author
David Qiu is a Solutions Architect working in the HCLS sector, helping healthcare companies build secure and scalable solutions in AWS. He is passionate about educating others on cloud technologies and big data processing. Outside of work, he also enjoys playing the guitar, video games, cigars, and whiskey. David holds a Bachelors in Economics and Computer Science from Washington University in St. Louis.
{kind=link}
Manish Agarwal is a technology enthusiast having 20+ years of engineering experience ranging from leading cutting-edge Healthcare startup to delivering massive scale innovations at companies like Apple and Amazon. Having deep expertise in AI/ML and healthcare, he truly believes that AI/ML will completely revolutionize the healthcare industry in next 4-5 years. His interests include precision medicine, Virtual assistants, Autonomous cars/ drones, AR/VR and blockchain. Manish holds Bachelors of Technology from Indian Institute of Technology (IIT).
Navneet Srivastava, a Principal Solutions Architect, is responsible for helping provider organizations and healthcare companies to deploy data lake, data mesh, electronic medical records, devices, and AI/ML-based applications while educating customers about how to build secure, scalable, and cost-effective AWS solutions. He develops strategic plans to engage customers and partners, and works with a community of technically focused HCLS specialists within AWS. Navneet has a M.B.A from NYIT and a bachelors in Software Engineering and holds several associate and professional certifications for architecting on AWS.
{kind=link}
Read MoreAWS Machine Learning Blog