

{kind=link}
Today, we are launching Amazon SageMaker inference on AWS Graviton to enable you to take advantage of the price, performance, and efficiency benefits that come from Graviton chips.
Graviton-based instances are available for model inference in SageMaker. This post helps you migrate and deploy a machine learning (ML) inference workload from x86 to Graviton-based instances in SageMaker. We provide a step-by-step guide to deploy your SageMaker trained model to Graviton-based instances, cover best practices when working with Graviton, discuss the price-performance benefits, and demo how to deploy a TensorFlow model on a SageMaker Graviton instance.
Brief overview of Graviton
AWS Graviton is a family of processors designed by AWS that provide the best price-performance and are more energy efficient than their x86 counterparts. AWS Graviton 3 processors are the latest in the Graviton processor family and are optimized for ML workloads, including support for bfloat16, and twice the Single Instruction Multiple Data (SIMD) bandwidth. When these two features are combined, Graviton 3 can deliver up to three times better performance vs. Graviton 2 instances. Graviton 3 also uses up to 60% less energy for the same performance as comparable Amazon Elastic Compute Cloud (Amazon EC2) instances. This is a great feature if you want to reduce your carbon footprint and achieve your sustainability goals.
Solution overview
To deploy your models to Graviton instances, you either use AWS Deep Learning Containers or bring your own containers compatible with Arm v8.2 architecture.
The migration (or new deployment) of your models from x86 powered instances to Graviton instances is simple because AWS provides containers to host models with PyTorch, TensorFlow, Scikit-learn, and XGBoost, and the models are architecture agnostic. Nevertheless, if you’re willing to bring your own libraries, you can also do so, just ensure that your container is built with an environment that supports Arm64 architecture. For more information, see Building your own algorithm container.
You need to complete three steps to deploy your model:
Create a SageMaker model: This will contain, among other parameters, the information about the model file location, the container that will be used for the deployment, and the location of the inference script. (If you have an existing model already deployed in an x86 based inference instance, you can skip this step.)
Create an endpoint configuration: This will contain information about the type of instance you want for the endpoint (for example, ml.c7g.xlarge for Graviton3), the name of the model you created in the step 1, and the number of instances per endpoint.
Launch the endpoint with the endpoint configuration created in the step 2.
Prerequisites
Before starting, consider the following prerequisites:
Complete the prerequisites as listed in Prerequisites.
Your model should be either a PyTorch, TensorFlow, XGBoost, or Scikit-learn based model. The following table summarizes the versions currently supported as of this writing. For the latest updates, refer to SageMaker Framework Containers (SM support only).
.
Python
TensorFlow
PyTorch
Scikit-learn
XGBoost
Versions supported
3.8
2.9.1
1.12.1
1.0-1
1.3-1 to 1.5-1
The inference script is stored in Amazon Simple Storage Service (Amazon S3).
In the following sections, we walk you through the deployment steps.
Create a SageMaker model
If you have an existing model already deployed in an x86-based inference instance, you can skip this step. Otherwise, complete the following steps to create a SageMaker model:
Locate the model that you stored in an S3 bucket. Copy the URI.
You use the model URI later in the MODEL_S3_LOCATION.
Identify the framework version and Python version that was used during model training.
You need to select a container from the list of available AWS Deep Learning Containers per your framework and Python version. For more information, refer to Introducing multi-architecture container images for Amazon ECR.
Locate the inference Python script URI in the S3 bucket (the common file name is inference.py).
The inference script URI is needed in the INFERENCE_SCRIPT_S3_LOCATION.
With these variables, you can then call the SageMaker API with the following command:
You can also create multi-architecture images, and use the same image but with different tags. You can indicate on which architecture your instance will be deployed. For more information, refer to Introducing multi-architecture container images for Amazon ECR.
Create an endpoint config
After you create the model, you have to create an endpoint configuration by running the following command (note the type of instance we’re using):
The following screenshot shows the endpoint configuration details on the SageMaker console.
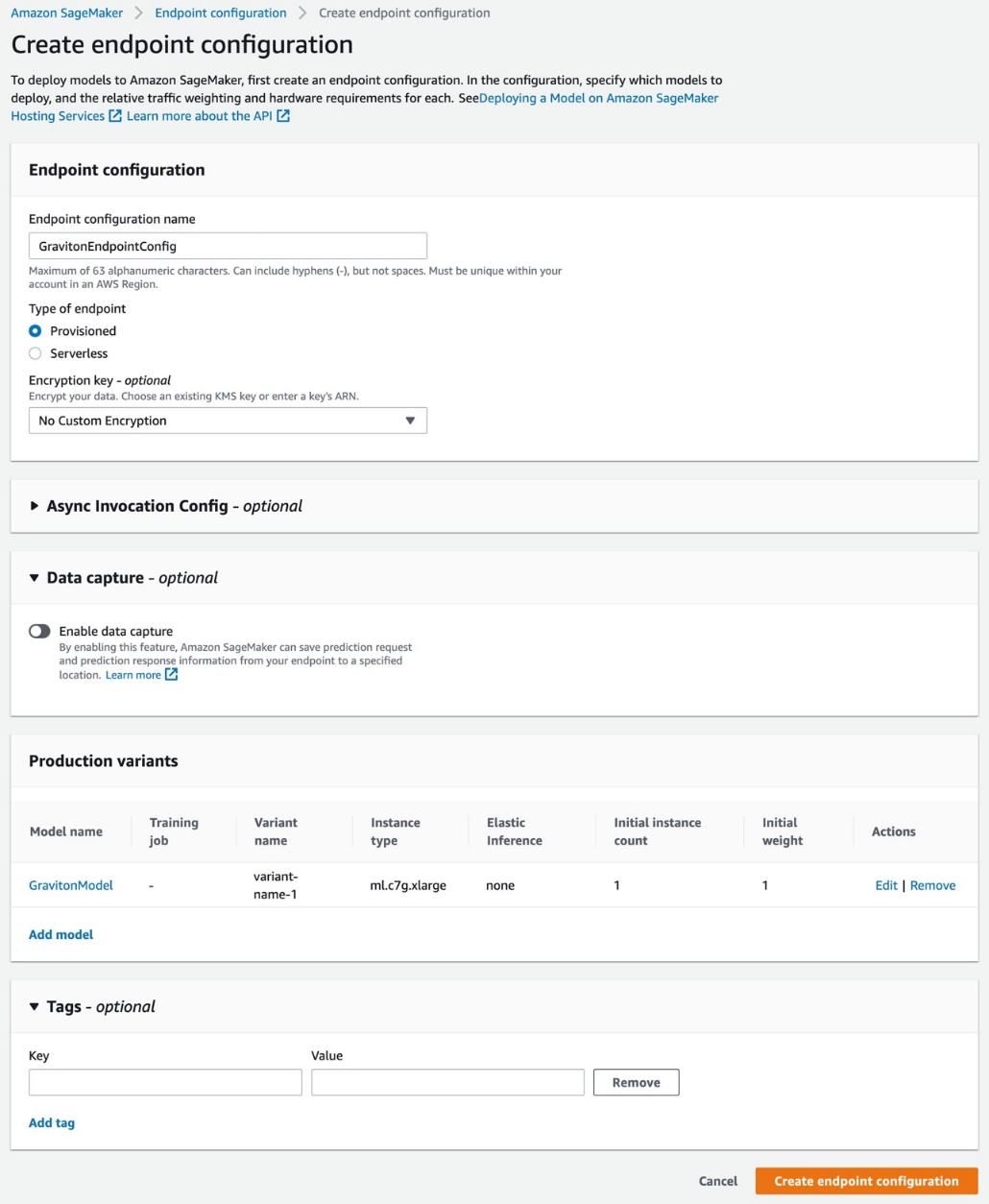{kind=link}
Launch the endpoint
With the endpoint config created in the previous step, you can deploy the endpoint:
Wait until your model endpoint is deployed. Predictions can be requested in the same way you request predictions for your endpoints deployed in x86-based instances.
The following screenshot shows your endpoint on the SageMaker console.
{kind=link}
What is supported
SageMaker provides performance-optimized Graviton deep containers for TensorFlow and PyTorch frameworks. These containers support computer vision, natural language processing, recommendations, and generic deep and wide model-based inference use cases. In addition to deep learning containers, SageMaker also provides containers for classical ML frameworks such as XGBoost and Scikit-learn. The containers are binary compatible across c6g/m6g and c7g instances, therefore migrating the inference application from one generation to another is seamless.
C6g/m6g supports fp16 (half-precision float) and for compatible models provides equivalent or better performance compared to c5 instances. C7g substantially increases the ML performance by doubling the SIMD width and supporting bfloat-16 (bf16), which is the most cost-efficient platform for running your models.
Both c6g/m6g and c7g provide good performance for classical ML (for example, XGBoost) compared to other CPU instances in SageMaker. Bfloat-16 support on c7g allows efficient deployment of bf16 trained or AMP (Automatic Mixed Precision) trained models. The Arm Compute Library (ACL) backend on Graviton provides bfloat-16 kernels that can accelerate even the fp32 operators via fast math mode, without the model quantization.
Recommended best practices
On Graviton instances, every vCPU is a physical core. There is no contention for the common CPU resources (unlike SMT), and the workload performance scaling is linear with every vCPU addition. Therefore, it’s recommended to use batch inference whenever the use case allows. This will enable efficient use of the vCPUs by parallel processing the batch on each physical core. If the batch inference isn’t possible, the optimal instance size for a given payload is required to ensure OS thread scheduling overhead doesn’t outweigh the compute power that comes with the additional vCPUs.
TensorFlow comes with Eigen kernels by default, and it’s recommended to switch to OneDNN with ACL to get the most optimized inference backend. The OneDNN backend and the bfloat-16 fast math mode can be enabled while launching the container service:
The preceding serving command hosts a standard resnet50 model with two important configurations:
These can be passed to the inference container in the following way:
Deployment example
In this post, we show you how to deploy a TensorFlow model, trained in SageMaker, on a Graviton-powered SageMaker inference instance.
You can run the code sample either in a SageMaker notebook instance, an Amazon SageMaker Studio notebook, or a Jupyter notebook in local mode. You need to retrieve the SageMaker execution role if you use a Jupyter notebook in local mode.
The following example considers the CIFAR-10 dataset. You can follow the notebook example from the SageMaker examples GitHub repo to reproduce the model that is used in this post. We use the trained model and the cifar10_keras_main.py Python script for inference.
The model is stored in an S3 bucket: s3://aws-ml-blog/artifacts/run-ml-inference-on-graviton-based-instances-with-amazon-sagemaker/model.tar.gz
The cifar10_keras_main.py script, which can be used for the inference, is stored at:s3://aws-ml-blog/artifacts/run-ml-inference-on-graviton-based-instances-with-amazon-sagemaker/script/cifar10_keras_main.py
We use the us-east-1 Region and deploy the model on an ml.c7g.xlarge Graviton-based instance. Based on this, the URI of our AWS Deep Learning Container is 763104351884.dkr.ecr.us-east-1.amazonaws.com/tensorflow-inference-graviton:2.9.1-cpu-py38-ubuntu20.04-sagemaker
Set up with the following code:
Download the dataset for endpoint testing:
Create the model and endpoint config, and deploy the endpoint:
Optionally, you can add your inference script to Environment in create_model if you didn’t originally add it as an artifact to your SageMaker model during training:
You have to wait a couple of minutes for the deployment to take place.
Verify the endpoint status with the following code:
You can also check the AWS Management Console to see when your model is deployed.
Set up the runtime environment to invoke the endpoints:
Now we prepare the payload to invoke the endpoint. We use the same type of images used for the training of the model. These were downloaded in previous steps.
Cast the payload to tensors and set the correct format that the model is expecting. For this example, we only request one prediction.
We get the model output as an array.
We can turn this output into probabilities if we apply a softmax to it:
Clean up resources
The services involved in this solution incur costs. When you’re done using this solution, clean up the following resources:
Price-performance comparison
Graviton-based instances offer the lowest price and the best price-performance when compared to x86-based instances. Similar to EC2 instances, the SageMaker inference endpoints with ml.c6g instances (Graviton 2) offer a 20% lower price compared to ml.c5, and the Graviton 3 ml.c7g instances are 15% cheaper than ml.c6 instances. For more information, refer to Amazon SageMaker Pricing.
Conclusion
In this post, we showcased the newly launched SageMaker capability to deploy models in Graviton-powered inference instances. We gave you guidance on best practices and briefly discussed the price-performance benefits of the new type of inference instances.
To learn more about Graviton, refer to AWS Graviton Processor. You can get started with AWS Graviton-based EC2 instances on the Amazon EC2 console and by referring to AWS Graviton Technical Guide. You can deploy a Sagemaker model endpoint for inference on Graviton with the sample code in this blog post.
About the authors
Victor Jaramillo, PhD, is a Senior Machine Learning Engineer in AWS Professional Services. Prior to AWS, he was a university professor and research scientist in predictive maintenance. In his free time, he enjoys riding his motorcycle and DIY motorcycle mechanics.
{kind=link}
Zmnako Awrahman, PhD, is a Practice Manager, ML SME, and Machine Learning Technical Field Community (TFC) member at Amazon Web Services. He helps customers leverage the power of the cloud to extract value from their data with data analytics and machine learning.
{kind=link}
Sunita Nadampalli is a Software Development Manager at AWS. She leads Graviton software performance optimizations for machine leaning, HPC, and multimedia workloads. She is passionate about open-source development and delivering cost-effective software solutions with Arm SoCs.
{kind=link}
Johna Liu is a Software Development Engineer in the Amazon SageMaker team. Her current work focuses on helping developers efficiently host machine learning models and improve inference performance. She is passionate about spatial data analysis and using AI to solve societal problems.
{kind=link}
Alan Tan is a Senior Product Manager with SageMaker, leading efforts on large model inference. He’s passionate about applying machine learning to the area of analytics. Outside of work, he enjoys the outdoors.
{kind=link}
Read MoreAWS Machine Learning Blog