

{kind=link}
In December 2020, AWS announced the general availability of Amazon SageMaker JumpStart, a capability of Amazon SageMaker that helps you quickly and easily get started with machine learning (ML). In March 2022, we also announced the support for APIs in JumpStart. JumpStart provides one-click fine-tuning and deployment of a wide variety of pre-trained models across popular ML tasks, as well as a selection of end-to-end solutions that solve common business problems. These features remove the heavy lifting from each step of the ML process, making it simpler to develop high-quality models and reducing time to deployment.
In this post, we demonstrate how to run automatic model tuning with JumpStart.
SageMaker automatic model tuning
Traditionally, ML engineers implement a trial and error method to find the right set of hyperparameters. Trial and error involves running multiple jobs sequentially or in parallel while provisioning the resources needed to run the experiment.
With SageMaker automatic model tuning, ML engineers and data scientists can offload the time-consuming task of optimizing their model and let SageMaker run the experimentation. SageMaker takes advantage of the elasticity of the AWS platform to efficiently and concurrently run multiple training simulations on a dataset and find the best hyperparameters for a model.
SageMaker automatic model tuning finds the best version of a model by running many training jobs on your dataset using the algorithm and ranges of hyperparameters that you specify. It then chooses the hyperparameter values that result in a model that performs the best, as measured by a metric that you choose.
Automatic model tuning uses either a Bayesian (default) or a random search strategy to find the best values for hyperparameters. Bayesian search treats hyperparameter tuning like a regression problem. When choosing the best hyperparameters for the next training job, it considers everything that it knows about the problem so far and allows the algorithm to exploit the best-known results.
In this post, we use the default Bayesian search strategy to demonstrate the steps involved in running automatic model tuning with JumpStart using the LightGBM model.
JumpStart currently supports 10 example notebooks with automatic model tuning. It also supports four popular algorithms for tabular data modeling. The tasks and links to their sample notebooks are summarized in the following table.
Task
Pre-trained Models
Supports Custom Dataset
Frameworks Supported
Example Notebooks
Image Classification
yes
yes
PyTorch, TensorFlow
Introduction to JumpStart – Image Classification
Object Detection
yes
yes
PyTorch, TensorFlow, MXNet
Introduction to JumpStart – Object Detection
Semantic Segmentation
yes
yes
MXNet
Introduction to JumpStart – Semantic Segmentation
Text Classification
yes
yes
TensorFlow
Introduction to JumpStart – Text Classification
Sentence Pair Classification
yes
yes
TensorFlow, Hugging Face
Introduction to JumpStart – Sentence Pair Classification
Question Answering
yes
yes
PyTorch
Introduction to JumpStart – Question Answering
Tabular Classification
yes
yes
LightGBM, CatBoost, XGBoost, Linear Learner
Introduction to JumpStart – Tabular Classification – LightGBM, CatBoost
Introduction to JumpStart – Tabular Classification – XGBoost, Linear Learner
Tabular Regression
yes
yes
LightGBM, CatBoost, XGBoost, Linear Learner
Introduction to JumpStart – Tabular Regression – LightGBM, CatBoost
Introduction to JumpStart – Tabular Regression – XGBoost, Linear Learner
Solution overview
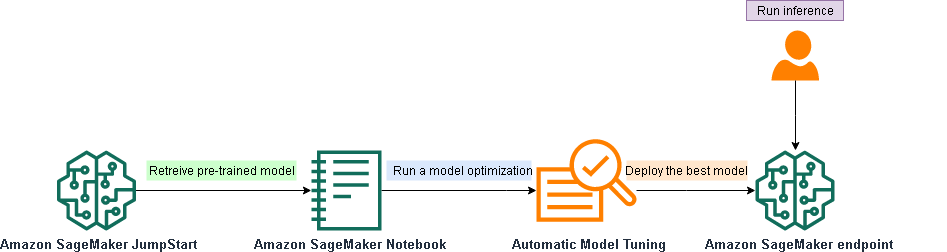
This technical workflow gives an overview of the different Amazon Sagemaker features and steps needed to automatically tune a JumpStart model.
{kind=link}
In the following sections, we provide a step-by-step walkthrough of how to run automatic model tuning with JumpStart using the LightGBM algorithm. We provide an accompanying notebook for this walkthrough.
We walk through the following high-level steps:
Retrieve the JumpStart pre-trained model and images container.
Set static hyperparameters.
Define the tunable hyperparameter ranges.
Initialize the automatic model tuning.
Run the tuning job.
Deploy the best model to an endpoint.
Retrieve the JumpStart pre-trained model and images container
In this section, we choose the LightGBM classification model for fine-tuning. We use the ml.m5.xlarge instance type on which the model is run. We then retrieve the training Docker container, the training algorithm source, and the pre-trained model. See the following code:
training_instance_type = “ml.m5.xlarge”
# Retrieve the docker image
train_image_uri = image_uris.retrieve(
region=None,
framework=None,
model_id=train_model_id,
model_version=train_model_version,
image_scope=train_scope,
instance_type=training_instance_type,
)
# Retrieve the training script
train_source_uri = script_uris.retrieve(
model_id=train_model_id, model_version=train_model_version, script_scope=train_scope
)
# Retrieve the pre-trained model tarball to further fine-tune
train_model_uri = model_uris.retrieve(
model_id=train_model_id, model_version=train_model_version, model_scope=train_scope
)
Set static hyperparameters
We now retrieve the default hyperparameters for this LightGBM model, as preconfigured by JumpStart. We also override the num_boost_round hyperparameter with a custom value.
# Retrieve the default hyper-parameters for fine-tuning the model
hyperparameters = hyperparameters.retrieve_default(
model_id=train_model_id, model_version=train_model_version
)
# [Optional] Override default hyperparameters with custom values
Define the tunable hyperparameter ranges
Next we define the hyperparameter ranges to be optimized by automatic model tuning. We define the hyperparameter name as expected by the model and then the ranges of values to be tried for this hyperparameter. Automatic model tuning draws samples (equal to the max_jobs parameter) from the space of hyperparameters, using a technique called Bayesian search. For each drawn hyperparameter sample, the tuner creates a training job to evaluate the model with that configuration. See the following code:
hyperparameter_ranges = {
“learning_rate”: ContinuousParameter(1e-4, 1, scaling_type=”Logarithmic”),
“num_boost_round”: IntegerParameter(2, 30),
“early_stopping_rounds”: IntegerParameter(2, 30),
“num_leaves”: IntegerParameter(10, 50),
“feature_fraction”: ContinuousParameter(0, 1),
“bagging_fraction”: ContinuousParameter(0, 1),
“bagging_freq”: IntegerParameter(1, 10),
“max_depth”: IntegerParameter(5, 30),
“min_data_in_leaf”: IntegerParameter(5, 50),
}
Initialize the automatic model tuning
We start by creating an Estimator object with all the required assets that define the training job, such as the pre-trained model, the training image, and the training script. We then define a HyperparameterTuner object to interact with SageMaker hyperparameter tuning APIs.
The HyperparameterTuner accepts as parameters the Estimator object, the target metric based on which the best set of hyperparameters is decided, the total number of training jobs (max_jobs) to start for the hyperparameter tuning job, and the maximum parallel training jobs to run (max_parallel_jobs). Training jobs are run with the LightGBM algorithm, and the hyperparameter values that has the minimal mlogloss metric is chosen. For more information about configuring automatic model tuning, see Best Practices for Hyperparameter Tuning.
# Create SageMaker Estimator instance
tabular_estimator = Estimator(
role=aws_role,
image_uri=train_image_uri,
source_dir=train_source_uri,
model_uri=train_model_uri,
entry_point=”transfer_learning.py”,
instance_count=1,
instance_type=training_instance_type,
max_run=360000,
hyperparameters=hyperparameters,
output_path=s3_output_location,
)
tuner = HyperparameterTuner(
estimator=tabular_estimator,
objective_metric_name=”multi_logloss”,
hyperparameter_ranges=hyperparameter_ranges,
metric_definitions=[{“Name”: “multi_logloss”, “Regex”: “multi_logloss: ([0-9\.]+)”}],
strategy=”Bayesian”,
max_jobs=10,
max_parallel_jobs=2,
objective_type=”Minimize”,
base_tuning_job_name=training_job_name,
)
In the preceding code, we tell the tuner to run at most 10 experiments (max_jobs) and only two concurrent experiments at a time (max_parallel_jobs). Both of these parameters keep your cost and training time under control.
Run the tuning job
To launch the SageMaker tuning job, we call the fit method of the hyperparameter tuner object and pass the Amazon Simple Storage Service (Amazon S3) path of the training data:
tuner.fit({“training”: training_dataset_s3_path}, logs=True)
While automatic model tuning searches for the best hyperparameters, you can monitor their progress either on the SageMaker console or on Amazon CloudWatch. When training is complete, the best model’s fine-tuned artifacts are uploaded to the Amazon S3 output location specified in the training configuration.
Deploy the best model to an endpoint
When the tuning job is complete, the best model has been selected and stored in Amazon S3. We now can deploy that model by calling the deploy method of the HyperparameterTuner object and passing the needed parameters, such as the number of instances to be used for the created endpoint, their type, the image to be deployed, and the script to run:
tuner.deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
entry_point=”inference.py”,
image_uri=deploy_image_uri,
source_dir=deploy_source_uri,
endpoint_name=endpoint_name,
enable_network_isolation=True
)
We can now test the created endpoint by making inference requests. You can follow the rest of the process in the accompanying notebook.
Conclusion
With automatic model tuning in SageMaker, you can find the best version of your model by running training jobs on the provided dataset with one of the supported algorithms. Automatic model tuning allows you to reduce the time to tune a model by automatically searching for the best hyperparameter configuration within the hyperparameter ranges that you specify.
In this post, we showed the value of running automatic model tuning on a JumpStart pre-trained model using SageMaker APIs. We used the LightGBM algorithm and defined a maximum of 10 training jobs. We also provided links to example notebooks showcasing the ML frameworks that support JumpStart model optimization.
For more details on how to optimize a JumpStart model with automatic model tuning, refer to our example notebook.
About the Author
Doug Mbaya is a Senior Partner Solution architect with a focus in data and analytics. Doug works closely with AWS partners, helping them integrate data and analytics solution in the cloud.
{kind=link}
Kruthi Jayasimha Rao is a Partner Solutions Architect in the Scale-PSA team. Kruthi conducts technical validations for Partners enabling them progress in the Partner Path.
{kind=link}
Giannis Mitropoulos is a Software Development Engineer for SageMaker Automatic Model Tuning.
{kind=link}
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He is an active researcher in machine learning and statistical inference and has published many papers in NeurIPS, ICML, ICLR, JMLR, and ACL conferences.
{kind=link}
Read MoreAWS Machine Learning Blog