

{kind=link}
PostgreSQL is considered to be the primary open-source database choice when migrating from commercial databases such as Oracle. AWS provides two managed PostgreSQL options: Amazon Relational Database Service (Amazon RDS) for PostgreSQL and Amazon Aurora PostgreSQL-Compatible Edition. Identifying slow queries and tuning for better performance is an important task for developers and database administrators managing Amazon RDS and Aurora PostgreSQL environments. To identify slow queries, multiple options are available. You can use the pgBadger tool to find the queries from the PostgreSQL log files by generating a report, or you can use Amazon RDS Performance Insights, which provides an easy-to-understand dashboard for detecting performance problems. For more information on finding slow queries, see Optimizing and tuning queries in Amazon RDS PostgreSQL based on native and external tools.
If database slowness is caused by SQL queries, you can generate query plans using the EXPLAIN command and optimize the SQLs accordingly. However, if the slowness is due to PL/pgSQL functions or procedures, the EXPLAIN plan doesn’t help much because it can’t generate plans for the SQLs inside the function or procedure. The SQL queries inside are optimized just like normal SQL queries, however separately and one by one. Or you can use the additional module auto_explain to get more details. Statements inside PL/pgSQL functions are considered nested statements, so you need to turn on the auto_explain.log_nested_statements parameter. For more details, refer to How can I log execution plans of queries for Amazon RDS PostgreSQL or Aurora PostgreSQL to tune query performance.
Generating a plan for SQLs (manually or through auto_explain) is a time-consuming process. To overcome this, you can use the plprofiler extension, which creates performance profiles of UDFs (user-defined PL/pgSQL functions) and stored procedures. You can use this extension to figure out the issue in the PL/pgSQL functions and procedures along with their runtimes. As part of profiling, we can generate HTML reports that contain details of the queries along with their respective runtimes.
The plprofiler tool is available in Amazon RDS for PostgreSQL and Aurora PostgreSQL (supported from version 11.6 and later).
In this post, we discuss how to install and configure the plprofiler extension. We also generate a report for a sample function to troubleshoot and find the queries causing the slowdown.
Solution overview
To use plprofiler, you need to load the extension on the backend (create the extension in the database) and install the plprofiler command line utility to generate reports.
Complete the following steps as part of installation:
Configure and enable plprofiler on Aurora PostgreSQL or Amazon RDS for PostgreSQL.
Install plprofiler on Amazon Elastic Compute Cloud (Amazon EC2) so that the command line utility can be invoked.
Prerequisites
To install and configure plprofiler, you need to complete the following steps as prerequisites:
Create an Aurora PostgreSQL cluster or RDS for PostgreSQL instance if you don’t already have one.
Create an EC2 instance (Ubuntu 16 or Amazon Linux) to install plprofiler and the PostgreSQL client to access the Aurora or RDS for PostgreSQL instance.
Install the PostgreSQL client.
To install PostgreSQL on Ubuntu, complete the following steps:
Create the file repository configuration
Import the repository signing key
Update the package lists
Install the latest version of PostgreSQL. If you want a specific version, use postgresql-12 or similar instead of postgresql
To install PostgreSQL on Amazon Linux, complete the following steps:
Check the available PostgreSQL and Python version and then enable the required versions
Update yum and then install PostgreSQL and Python
Configure and enable plprofiler on Aurora PostgreSQL
Complete the following steps to configure and enable plprofiler on Aurora for PostgreSQL:
Set the shared_preload_libraries parameter to plprofiler in the instance parameter group, as shown in the following screenshot.
{kind=link}
This parameter change requires an Aurora PostgreSQL instance reboot because this is a static parameter.
When the reboot is complete, connect to the database using pgadmin4 or psql client and create the plprofiler extension in the database.
Install plprofiler on an EC2 instance
After the plprofiler is enabled and configured on the database, we can proceed with the following commands to install plprofiler on an EC2 instance, which we can use as a command line utility.
On Ubuntu, log in to the EC2 instance using putty or terminal or Session Manager and connect to the root user.
On Amazon Linux, log in to the EC2 instance using putty or terminal or Session Manager and connect to the root user.
To check where plprofiler is installed, run on the command line which plprofiler:
Test and validate plprofiler
To test plprofiler, we create the sample tables and function shown in the following example. Make sure you create the plprofiler extension in the testing database.
In this example, we created a separate database called plprofiler, sample tables, and a function in the public schema. Then we used the function inventory_in_stock for testing.
Create tables with the following code:
Insert the dummy data using the generate_series function.
The following query inserts 1 million rows – a sequence of numbers for integer columns and a random date from any of the dates in the last 2 years for the timestamp columns:
Create a function with the following code:
After you create the objects, log in to the EC2 instance and run the following command to invoke plprofiler from the command line.
This generates the report inventory_in_stock.html.
Copy the inventory_in_stock.html file to a machine on which you can open it in a web browser.
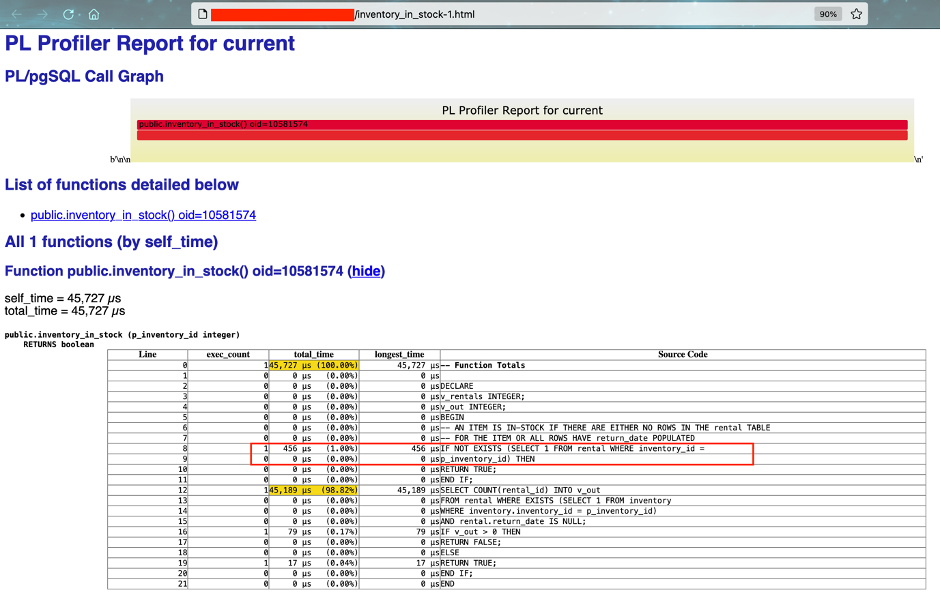
Extract the time-consuming query, as highlighted in the following screenshot, and generate the run plan as follows:
{kind=link}
In this plan, we can see that the query is taking more time because it’s performing a sequential scan on table.
To resolve this, add an index on the inventory_id column.
Check the query plan with the index created, which now shows the index scan.
Rerun the plprofiler report from the EC2 instance.
If we check the inventory_in_stock.html report again, we can see that the same query is taking less time (almost 67% less) to run after we added the index.
{kind=link}
Creating an index on the inventory_id column of the rental table resolved the performance issue. However, if you look at the design prospective and as a best practice, you need a primary key on the inventory_id column of the inventory table and a referential key (foreign key) on the inventory_id column of the rental table.
Use the following ALTER statements to add the primary and foreign keys for the tables accordingly.
Generate a new plprofiler report for the function.
We can see that performance improved by approximately 50%.
{kind=link}
Cleanup
Resource cleanup is one of the important process after all testing is completed. In our case after completion of testing, we have terminated the EC2 and Aurora PostgreSQL instances which were not required. If you’re no longer going to use them, make sure you terminate them as well:
Terminate your EC2 instance
Terminate your Amazon RDS for PostgreSQL instance or your Aurora PostgreSQL instance
Conclusion
The plprofiler tool helps expedite the process of fine-tuning complex user-defined functions and stored procedures in Aurora for PostgreSQL or Amazon RDS for PostgreSQL by reducing the manual effort. As explained in this post, you can generate a plprofiler report for a problematic function or procedure. You can then review the report to find the part of the function or procedure where it is slow and take necessary actions to improve performance.
If you have any questions or suggestions about this post, leave a comment.
About the Authors
Rajesh Madiwale is a Lead Consultant with Amazon Web Services. He has deep expertise on database development and administration on Amazon RDS for PostgreSQL, Aurora PostgreSQL, Redshift, MySQL and Greenplum databases. He is an ardent member of the PostgreSQL community and has been working on PostgreSQL his entire tenure. He has also delivered several sessions at PostgreSQL conferences.
{kind=link}
Baji Shaik is a Sr. Lead Consultant with AWS ProServe, GCC India. His background spans a wide depth and breadth of expertise and experience in SQL/NoSQL database technologies. He is a Database Migration Expert and has developed many successful database solutions addressing challenging business requirements for moving databases from on-premises to Amazon RDS and Aurora PostgreSQL/MySQL. He is an eminent author, having written several books on PostgreSQL. A few of his recent works include “PostgreSQL Configuration“, “Beginning PostgreSQL on the Cloud”, and “PostgreSQL Development Essentials“. Furthermore, he has delivered several conference and workshop sessions.
{kind=link}
Bhanu Akula is a Consultant with Amazon Web Services. She has expertise in database administration, consulting, solutioning on Amazon RDS for PostgreSQL, Aurora PostgreSQL, and Greenplum databases. She has been working with the database community on Oracle, PostgreSQL, Greenplum since the beginning of her career. She is working actively for the customers from all over the world in the Assess part of their migration journey, in discovering data through various discovery tools and recommending the right sized recommendations.
{kind=link}
Read MoreAWS Database Blog