

{kind=link}
Data science and data engineering teams spend a significant portion of their time in the data preparation phase of a machine learning (ML) lifecycle performing data selection, cleaning, and transformation steps. It’s a necessary and important step of any ML workflow in order to generate meaningful insights and predictions, because bad or low-quality data greatly reduces the relevance of the insights derived.
Data engineering teams are traditionally responsible for the ingestion, consolidation, and transformation of raw data for downstream consumption. Data scientists often need to do additional processing on data for domain-specific ML use cases such as natural language and time series. For example, certain ML algorithms may be sensitive to missing values, sparse features, or outliers and require special consideration. Even in cases where the dataset is in a good shape, data scientists may want to transform the feature distributions or create new features in order to maximize the insights obtained from the models. To achieve these objectives, data scientists have to rely on data engineering teams to accommodate requested changes, resulting in dependency and delay in the model development process. Alternatively, data science teams may choose to perform data preparation and feature engineering internally using various programming paradigms. However, it requires an investment of time and effort in installation and configuration of libraries and frameworks, which isn’t ideal because that time can be better spent optimizing model performance.
Amazon SageMaker Data Wrangler simplifies the data preparation and feature engineering process, reducing the time it takes to aggregate and prepare data for ML from weeks to minutes by providing a single visual interface for data scientists to select, clean, and explore their datasets. Data Wrangler offers over 300 built-in data transformations to help normalize, transform, and combine features without writing any code. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift, and Snowflake. You can now also use Databricks as a data source in Data Wrangler to easily prepare data for ML.
The Databricks Lakehouse Platform combines the best elements of data lakes and data warehouses to deliver the reliability, strong governance and performance of data warehouses with the openness, flexibility and machine learning support of data lakes. With Databricks as a data source for Data Wrangler, you can now quickly and easily connect to Databricks, interactively query data stored in Databricks using SQL, and preview data before importing. Additionally, you can join your data in Databricks with data stored in Amazon S3, and data queried through Amazon Athena, Amazon Redshift, and Snowflake to create the right dataset for your ML use case.
In this post, we transform the Lending Club Loan dataset using Amazon SageMaker Data Wrangler for use in ML model training.
Solution overview
The following diagram illustrates our solution architecture.
{kind=link}
The Lending Club Loan dataset contains complete loan data for all loans issued through 2007–2011, including the current loan status and latest payment information. It has 39,717 rows, 22 feature columns, and 3 target labels.
To transform our data using Data Wrangler, we complete the following high-level steps:
Download and split the dataset.
Create a Data Wrangler flow.
Import data from Databricks to Data Wrangler.
Import data from Amazon S3 to Data Wrangler.
Join the data.
Apply transformations.
Export the dataset.
Prerequisites
The post assumes you have a running Databricks cluster. If your cluster is running on AWS, verify you have the following configured:
Databricks setup
An instance profile with required permissions to access an S3 bucket
A bucket policy with required permissions for the target S3 bucket
Follow Secure access to S3 buckets using instance profiles for the required AWS Identity and Access Management (IAM) roles, S3 bucket policy, and Databricks cluster configuration. Ensure the Databricks cluster is configured with the proper Instance Profile, selected under the advanced options, to access to the desired S3 bucket.
{kind=link}
After the Databricks cluster is up and running with required access to Amazon S3, you can fetch the JDBC URL from your Databricks cluster to be used by Data Wrangler to connect to it.
Fetch the JDBC URL
To fetch the JDBC URL, complete the following steps:
In Databricks, navigate to the clusters UI.
Choose your cluster.
On the Configuration tab, choose Advanced options.
Under Advanced options, choose the JDBC/ODBC tab.
Copy the JDBC URL.
{kind=link}
Make sure to substitute your personal access token in the URL.
Data Wrangler setup
This step assumes you have access to Amazon SageMaker, an instance of Amazon SageMaker Studio, and a Studio user.
To allow access to the Databricks JDBC connection from Data Wrangler, the Studio user requires following permission:
secretsmanager:PutResourcePolicy
Follow below steps to update the IAM execution role assigned to the Studio user with above permission, as an IAM administrative user.
On the IAM console, choose Roles in the navigation pane.
Choose the role assigned to your Studio user.
Choose Add permissions.
Choose Create inline policy.
For Service, choose Secrets Manager.
On Actions, choose Access level.
Choose Permissions management.
Choose PutResourcePolicy.
For Resources, choose Specific and select Any in this account.
{kind=link}
Download and split the dataset
You can start by downloading the dataset. For demonstration purposes, we split the dataset by copying the feature columns id, emp_title, emp_length, home_owner, and annual_inc to create a second loans_2.csv file. We remove the aforementioned columns from the original loans file except the id column and rename the original file to loans_1.csv. Upload the loans_1.csv file to Databricks to create a table loans_1 and loans_2.csv in an S3 bucket.
Create a Data Wrangler flow
For information on Data Wrangler pre-requisites, see Get Started with Data Wrangler.
Let’s get started by creating a new data flow.
On the Studio console, on the File menu, choose New.
Choose Data Wrangler flow.
Rename the flow as desired.
{kind=link}
Alternatively, you can create a new data flow from the Launcher.
On the Studio console, choose Amazon SageMaker Studio in the navigation pane.
Choose New data flow.
{kind=link}
Creating a new flow can take a few minutes to complete. After the flow has been created, you see the Import data page.
Import data from Databricks into Data Wrangler
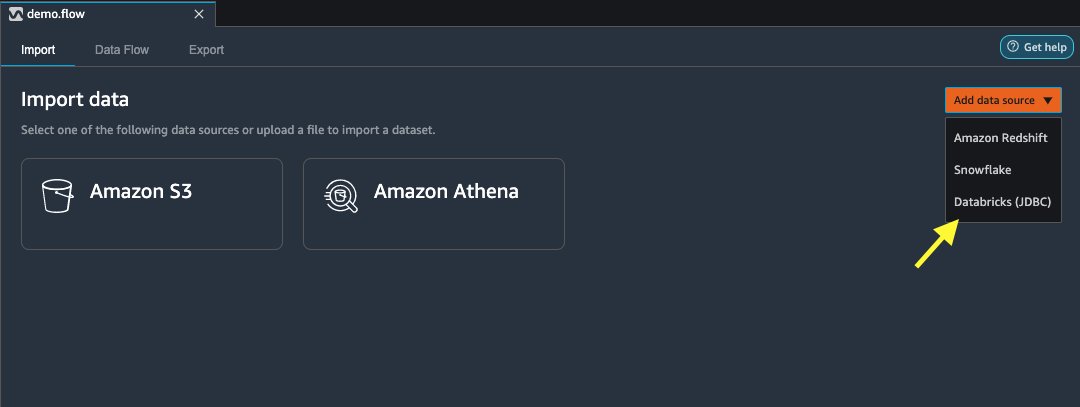
Next, we set up Databricks (JDBC) as a data source in Data Wrangler. To import data from Databricks, we first need to add Databricks as a data source.
On the Import data tab of your Data Wrangler flow, choose Add data source.
On the drop-down menu, choose Databricks (JDBC).
{kind=link}
On the Import data from Databricks page, you enter your cluster details.
For Dataset name, enter a name you want to use in the flow file.
For Driver, choose the driver com.simba.spark.jdbc.Driver.
For JDBC URL, enter the URL of your Databricks cluster obtained earlier.
The URL should resemble the following format jdbc:spark://<serve- hostname>:443/default;transportMode=http;ssl=1;httpPath=<http- path>;AuthMech=3;UID=token;PWD=<personal-access-token>.
In the SQL query editor, specify the following SQL SELECT statement:
If you chose a different table name while uploading data to Databricks, replace loans_1 in the above SQL query accordingly.
In the SQL query section in Data Wrangler, you can query any table connected to the JDBC Databricks database. The pre-selected Enable sampling setting retrieves the first 50,000 rows of your dataset by default. Depending on the size of the dataset, unselecting Enable sampling may result in longer import time.
Choose Run.
Running the query gives a preview of your Databricks dataset directly in Data Wrangler.
{kind=link}
{kind=link}
Data Wrangler provides the flexibility to set up multiple concurrent connections to the one Databricks cluster or multiple clusters if required, enabling analysis and preparation on combined datasets.
Import the data from Amazon S3 into Data Wrangler
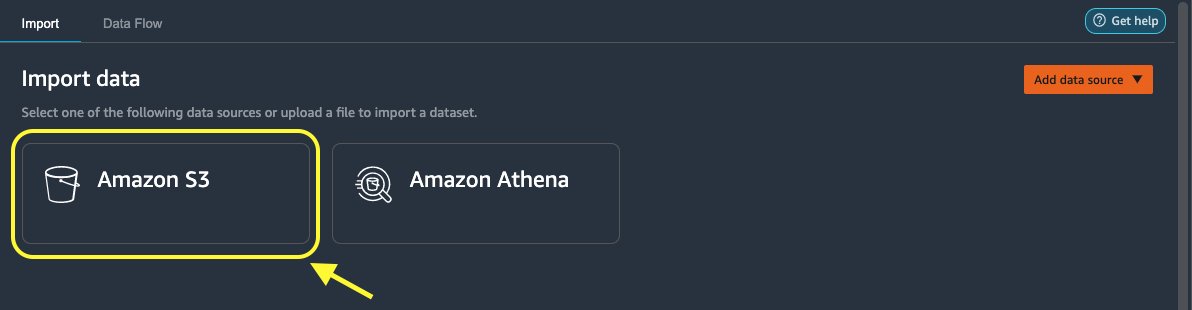
Next, let’s import the loan_2.csv file from Amazon S3.
On the Import tab, choose Amazon S3 as the data source.
Navigate to the S3 bucket for the loan_2.csv file.
{kind=link}
When you select the CSV file, you can preview the data.
In the Details pane, choose Advanced configuration to make sure Enable sampling is selected and COMMA is chosen for Delimiter.
Choose Import.
{kind=link}
After the loans_2.csv dataset is successfully imported, the data flow interface displays both the Databricks JDBC and Amazon S3 data sources.
{kind=link}
Join the data
Now that we have imported data from Databricks and Amazon S3, let’s join the datasets using a common unique identifier column.
On the Data flow tab, for Data types, choose the plus sign for loans_1.
Choose Join.
Choose the loans_2.csv file as the Right dataset.
Choose Configure to set up the join criteria.
For Name, enter a name for the join.
For Join type, choose Inner for this post.
Choose the id column to join on.
Choose Apply to preview the joined dataset.
Choose Add to add it to the data flow.
{kind=link}
{kind=link}
{kind=link}
Apply transformations
Data Wrangler comes with over 300 built-in transforms, which require no coding. Let’s use built-in transforms to prepare the dataset.
Drop column
First we drop the redundant ID column.
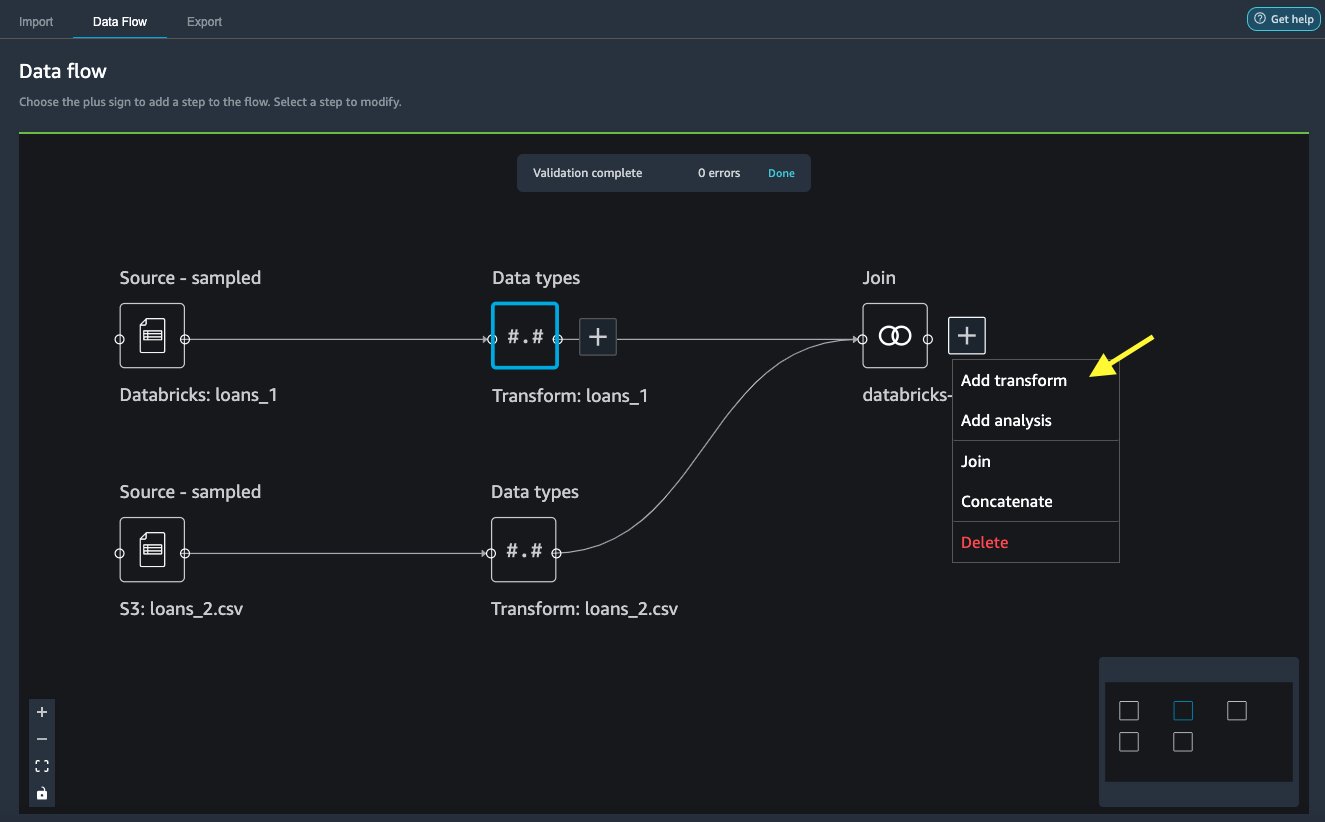
On the joined node, choose the plus sign.
Choose Add transform.
Under Transforms, choose + Add step.
Choose Manage columns.
For Transform, choose Drop column.
For Columns to drop, choose the column id_0.
Choose Preview.
Choose Add.
{kind=link}
{kind=link}
Format string
Let’s apply string formatting to remove the percentage symbol from the int_rate and revol_util columns.
On the Data tab, under Transforms, choose + Add step.
Choose Format string.
For Transform, choose Strip characters from right.
{kind=link}
Data Wrangler allows you to apply your chosen transformation on multiple columns simultaneously.
For Input columns, choose int_rate and revol_util.
For Characters to remove, enter %.
Choose Preview.
Choose Add.
{kind=link}
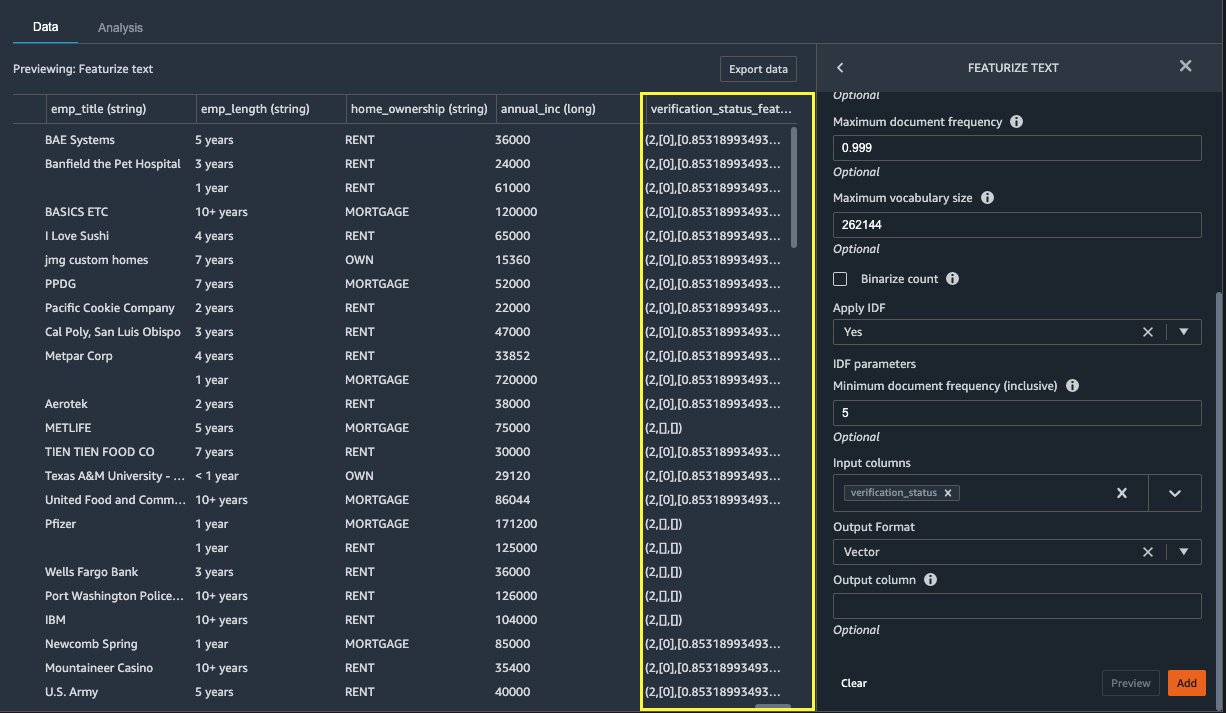
Featurize text
Let’s now vectorize verification_status, a text feature column. We convert the text column into term frequency–inverse document frequency (TF-IDF) vectors by applying the count vectorizer and a standard tokenizer as described below. Data Wrangler also provides the option to bring your own tokenizer, if desired.
Under Transformers, choose + Add step.
Choose Featurize text.
For Transform, choose Vectorize.
For Input columns, choose verification_status.
Choose Preview.
Choose Add.
{kind=link}
Export the dataset
After we apply multiple transformations on different columns types, including text, categorical, and numeric, we’re ready to use the transformed dataset for ML model training. The last step is to export the transformed dataset to Amazon S3. In Data Wrangler, you have multiple options to choose from for downstream consumption of the transformations:
Choose Export step to automatically generate a Jupyter notebook with SageMaker Processing code for processing and export the transformed dataset to an S3 bucket. For more information, see the Launch processing jobs with a few clicks using Amazon SageMaker Data Wrangler.
Export a Studio notebook that creates a SageMaker pipeline with your data flow, or a notebook that creates an Amazon SageMaker Feature Store feature group and adds features to an offline or online feature store.
Choose Export data to export directly to Amazon S3.
In this post, we take advantage of the Export data option in the Transform view to export the transformed dataset directly to Amazon S3.
Choose Export data.
For S3 location, choose Browse and choose your S3 bucket.
Choose Export data.
{kind=link}
{kind=link}
Clean up
If your work with Data Wrangler is complete, shut down your Data Wrangler instance to avoid incurring additional fees.
Conclusion
In this post, we covered how you can quickly and easily set up and connect Databricks as a data source in Data Wrangler, interactively query data stored in Databricks using SQL, and preview data before importing. Additionally, we looked at how you can join your data in Databricks with data stored in Amazon S3. We then applied data transformations on the combined dataset to create a data preparation pipeline. To explore more Data Wrangler’s analysis capabilities, including target leakage and bias report generation, refer to the following blog post Accelerate data preparation using Amazon SageMaker Data Wrangler for diabetic patient readmission prediction.
To get started with Data Wrangler, see Prepare ML Data with Amazon SageMaker Data Wrangler, and see the latest information on the Data Wrangler product page.
About the Authors
Roop Bains is a Solutions Architect at AWS focusing on AI/ML. He is passionate about helping customers innovate and achieve their business objectives using Artificial Intelligence and Machine Learning. In his spare time, Roop enjoys reading and hiking.
{kind=link}
Igor Alekseev is a Partner Solution Architect at AWS in Data and Analytics. Igor works with strategic partners helping them build complex, AWS-optimized architectures. Prior joining AWS, as a Data/Solution Architect, he implemented many projects in Big Data, including several data lakes in the Hadoop ecosystem. As a Data Engineer, he was involved in applying AI/ML to fraud detection and office automation. Igor’s projects were in a variety of industries including communications, finance, public safety, manufacturing, and healthcare. Earlier, Igor worked as full stack engineer/tech lead.
{kind=link}
Huong Nguyen is a Sr. Product Manager at AWS. She is leading the user experience for SageMaker Studio. She has 13 years’ experience creating customer-obsessed and data-driven products for both enterprise and consumer spaces. In her spare time, she enjoys reading, being in nature, and spending time with her family.
Henry Wang is a software development engineer at AWS. He recently joined the Data Wrangler team after graduating from UC Davis. He has an interest in data science and machine learning and does 3D printing as a hobby.
{kind=link}
Read MoreAWS Machine Learning Blog