

{kind=link}
Today, we’re excited to announce new Cloud TPU VMs, which make it easier than ever before to use our industry-leading TPU hardware by providing direct access to TPU host machines, offering a new and improved user experience to develop and deploy TensorFlow, PyTorch, and JAX on Cloud TPUs. Instead of accessing Cloud TPUs remotely over the network, Cloud TPU VMs let you set up your own interactive development environment on each TPU host machine.
Now you can write and debug an ML model line-by-line using a single TPU VM, then scale it up on a Cloud TPU Pod slice to take advantage of the super-fast TPU interconnect. You have root access to every TPU VM you create, so you can install and run any code you wish in a tight loop with your TPU accelerators. You can use local storage, execute custom code in your input pipelines, and more easily integrate Cloud TPUs into your research and production workflows.
In addition to Cloud TPU integrations with TensorFlow, PyTorch, and JAX, and you can even write your own integrations via a new libtpu shared library on the VM.
“Direct access to TPU VMs has completely changed what we’re capable of building on TPUs and has dramatically improved the developer experience and model performance.”— Aidan Gomez, co-founder and CEO, Cohere
A closer look at the new Cloud TPU architecture
Until now, you could only access Cloud TPUs remotely. You would typically create one or more VMs that would then communicate with Cloud TPU host machines over the network using gRPC:
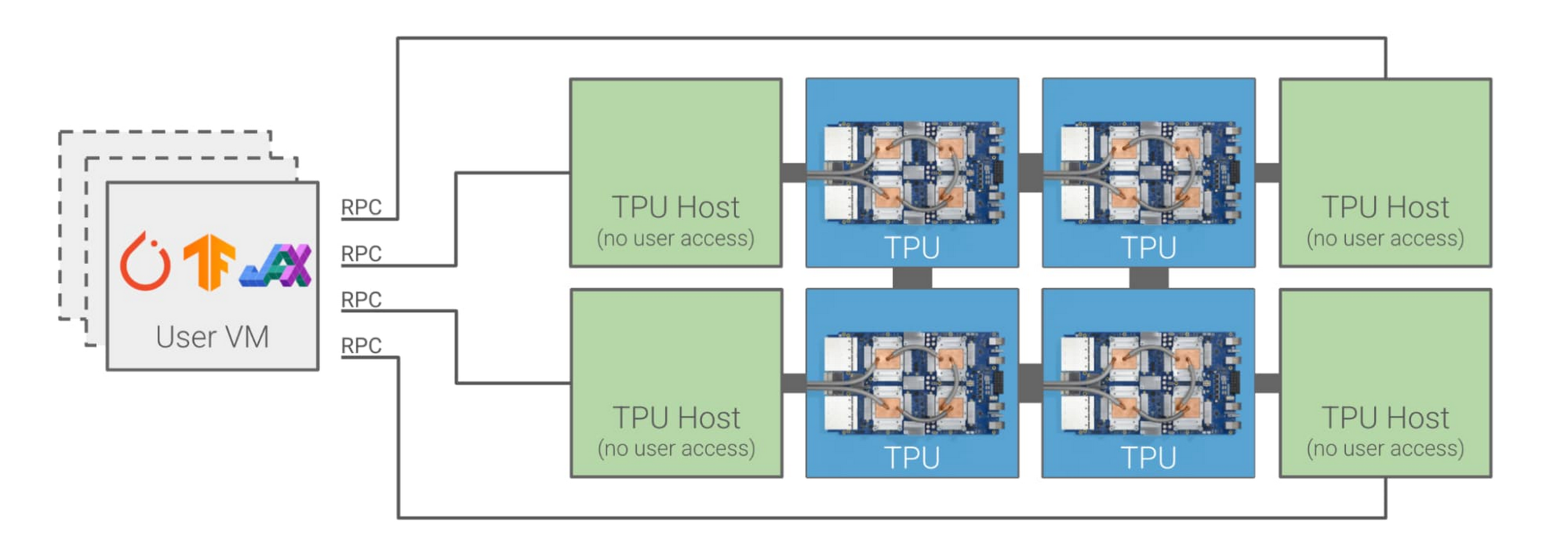{kind=link}
By contrast, Cloud TPU VMs run on the TPU host machines that are directly attached to TPU accelerators, as shown below:
{kind=link}
This new Cloud TPU system architecture is simpler and more flexible. In addition to major usability benefits, you may also achieve performance gains because your code no longer needs to make round trips across the datacenter network to reach the TPUs. Furthermore, you may also see significant cost savings: If you previously needed a fleet of powerful Compute Engine VMs to feed data to remote hosts in a Cloud TPU Pod slice, you can now run that data processing directly on the Cloud TPU hosts and eliminate the need for the additional Compute Engine VMs.
What customers are saying
Early access customers have been using Cloud TPU VMs since last October, and several teams of researchers and engineers have used them intensively since then. Here’s what they have to say:
Alex Barron is a Lead Machine Learning Engineer at Gridspace. Gridspace provides an out-of-the-box product for observing, analyzing and automating 100% of voice calls in real time. The company’s software powers voice operations at USAA, Bloomberg and Square, among other leading companies.
“At Gridspace we’ve been using JAX and Cloud TPU VMs to train massive speech and language models. These models power advanced analytics and automation capabilities inside our largest contact center customers. We saw an immediate 2x speed up over the previous Cloud TPU offering for training runs on the same size TPU and were able to scale to a 32-host v3-256 with no code changes. We’ve been incredibly satisfied with the power and ease of use of Cloud TPU VMs and we look forward to continuing to use them in the future.”— Alex Barron
James Townsend is a researcher at the UCL Queen Square Institute of Neurology in London. His team has been using JAX on Cloud TPU VMs to apply deep learning to medical imaging.
“Google Cloud TPU VMs enabled us to radically scale up our research with minimal implementation complexity. There is a low-friction pathway, from implementing a model and debugging on a single TPU device, up to multi-device and multi-host (pod scale) training. This ease-of-use, at this scale, is unique, and is a game changer for us in terms of research possibilities. I’m really excited to see the impact this work can have.”— James Townsend
Patrick von Platen is a Research Engineer at Hugging Face. Hugging Face is an open-source provider of natural language processing (NLP) technologies and creator of the popular Transformers library. With Hugging Face, researchers and engineers can leverage state-of-the-art NLP models with just a couple lines of code.
“At Hugging Face we’ve recently integrated JAX alongside TensorFlow and PyTorch into our Transformers library. This has enabled the NLP community to efficiently train popular NLP models, such as BERT, on Cloud TPU VMs. Using a single v3-8, it is now possible to pre-train a base-sized BERT model in less than a day using a batch size of up to 2048. At Hugging Face, we believe that providing easy access to Cloud TPU VMs will make pre-training of large language models possible for a much wider spectrum of the NLP community, including small start-ups as well as educational institutions.”— Patrick von Platen
Ben Wang is an independent researcher who works on Transformer-based models for language and multimodal applications. He has published open-source code for training large-scale transformers on Cloud TPU VMs and for orchestrating training over several Cloud TPU VMs with Ray.
“JAX on Cloud TPU VMs enables high-performance direct access to TPUs along with the flexibility to build unconventional training setups, such as pipeline parallel training across preemptible TPU pod slices using Ray.”— Ben Wang
Keno Fischer is a core developer of the Julia programming language and co-founder of Julia Computing, where he leads a team applying machine learning to scientific modeling and simulation. He is the author of significant parts of the Julia compiler, including Julia’s original TPU backend.
“The new TPU VM offering is a massive step forward for the usability of TPUs on the cloud. By being able to take direct advantage of the TPU hardware, we are no longer limited by the bandwidth and latency constraints of an intermediate network connection. This is of critical importance in our work where machine learning models are often directly coupled to scientific simulations running on the host machine.” — Keno Fischer
The Julia team is working on a second-generation Cloud TPU integration using the new libtpu shared library. Please sign up here to receive updates.
And finally, Shrestha Basu Mallick is a Product Manager on the Sandbox@Alphabet team, which has successfully adapted TPUs for classical simulations of quantum computers and to perform large-scale quantum chemistry computations.
“Thanks to Google Cloud TPU VMs, and the ability to seamlessly scale from 1 to 2048 TPU cores, our team has built one of the most powerful classical simulators of quantum circuits. The simulator is capable of evolving a wavefunction of 40 qubits, which entails manipulating one trillion complex amplitudes! Also, TPU scalability has been key to enabling our team to perform quantum chemistry computations of huge molecules, with up to 500,000 orbitals. We are very excited about Cloud TPUs.”— Shrestha Basu Mallick
Pricing and availability
Cloud TPU VMs are now available via preview in the us-central1 and europe-west4 regions. You can use single Cloud TPU devices as well as Cloud TPU Pod slices, and you can choose TPU v2 or TPU v3 accelerator hardware. Cloud TPU VMs are available for as little as $1.35 per hour per TPU host machine with our preemptible offerings. You can find additional pricing information here.
Get started today
You can get up and running quickly and start training ML models using JAX, PyTorch, and TensorFlow using Cloud TPUs and Cloud TPU Pods in any of our available regions. Check out our documentation to get started:
Cloud BlogRead More