

{kind=link}
Babelfish for Aurora PostgreSQL understands T-SQL, Microsoft SQL Server’s proprietary SQL dialect, and supports the same communications protocol, so your applications that were originally written for SQL Server can now work with Amazon Aurora PostgreSQL-Compatible Edition with fewer code changes. With Babelfish, you still have to migrate the data from your SQL Server database to Aurora PostgreSQL. You can use Microsoft-licensed SQL Server Integration Services (SSIS) to migrate data from SQL Server to Aurora PostgreSQL using Babelfish. In this post, we show how to migrate a large SQL Server database to Aurora PostgreSQL using SSIS and Babelfish. We use SSIS Data Flow tasks and configure the ADO.NET source (SQL Server) and ADO.NET destination (Aurora PostgreSQL cluster with Babelfish turned on) to copy data between the source and target databases.
Prerequisites
Install the below components before moving onto the steps to start copying the data.
Install SSIS from your SQL Server installation media. If you have License Included SQL Server on EC2, it’s already installed. Check Install Integration Services for the instructions to install or verify SSIS installation.
Install Visual Studio 2019. Note that Visual Studio 2022 doesn’t support Integration Services Data Tools.
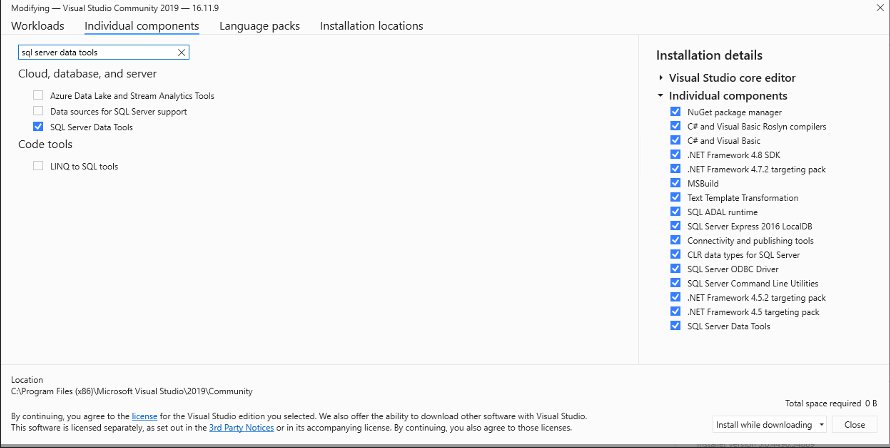
Once you have Visual Studio installed, search for SQL Server Data Tools on the Individual components tab in Visual Studio 2019. Select SQL Server Data Tools and install it. Visit Change workloads or individual components for the instructions to install the Individual components.
Next, Install SSIS project components (Microsoft.DataTools.IntegrationServices) from the Visual Studio Marketplace.
{kind=link}
{kind=link}
Migrate your data
The following is an outline of the migration process. Make sure you have completed the prerequisites before proceeding with the below steps.
Create a new Data Flow task
Select SQL Server as the source
Select your Babelfish endpoint of your Aurora PostgreSQL cluster as the destination
Run the Data Flow task
Create a Data Flow task
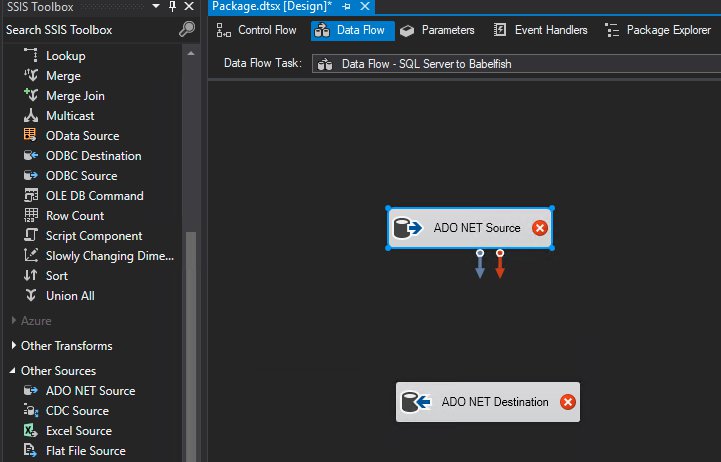
The Data Flow task encapsulates the data flow engine that moves data between sources and destinations, and lets you transform, clean, and modify data as it’s moved. We use an ADO.NET source (SQL Server database) and ADO.NET destination (Aurora PostgreSQL cluster with Babelfish turned on).
Create a new integration service project in Visual Studio. Click here for instructions to create a new project in Visual Studio.
Create a new Data Flow task and rename it (if needed).
Double Click and open the Data Flow task to add the ADO.NET source and destination.
Choose the source to create the ADO.NET source connection and choose New.
For Configure ADO.NET Connection Manager, choose New.
For Provider, choose .Net Providers for OleDbSQL Server Native Client 11.0.
For Server name, enter the SQL Server source database.
Choose the authentication mechanism.
Choose the database.
Test Connection to make sure the test connection succeeds, then choose OK.
Choose the destination to create the ADO.NET destination connection and choose New to open the Connection Manager dialog.
On the Configure ADO.NET Connection Manager dialog, select New to create a new connection.
For Provider, choose .Net Providers for OleDbSQL Server Native Client 11.0.
For Server name, enter the cluster endpoint of your Aurora PostgreSQL cluster and the TDS port (by default, 1433). Refer our documentation for more information on connecting to an Aurora PostgreSQL cluster with Babelfish turned on.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This step assumes that you have already created the destination tables using a script generated by SQL Server Management Studio (SSMS). If not, refer to Migrate from SQL Server to Amazon Aurora using Babelfish to get the optional assessment report and create tables in Babelfish for Aurora PostgreSQL.
Enter the credentials to connect.
Choose the database.
Choose Test Connection to make sure the test connection succeeds, then choose OK.
After the connections are created, open the ADO.NET source and choose the newly created connection.
For Data access mode, choose Table or View.
On the drop-down menu, choose the table to be copied.
Open the ADO.NET destination and choose the newly created connection.
For Use a table or view, type the table name.
Deselect Use Bulk Insert when possible.
Choose Mappings and confirm the mapping is populated and correctly mapped between the columns.
Choose OK.
On the Control Flow tab, choose the Data Flow task, then right-click and choose Execute Task.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
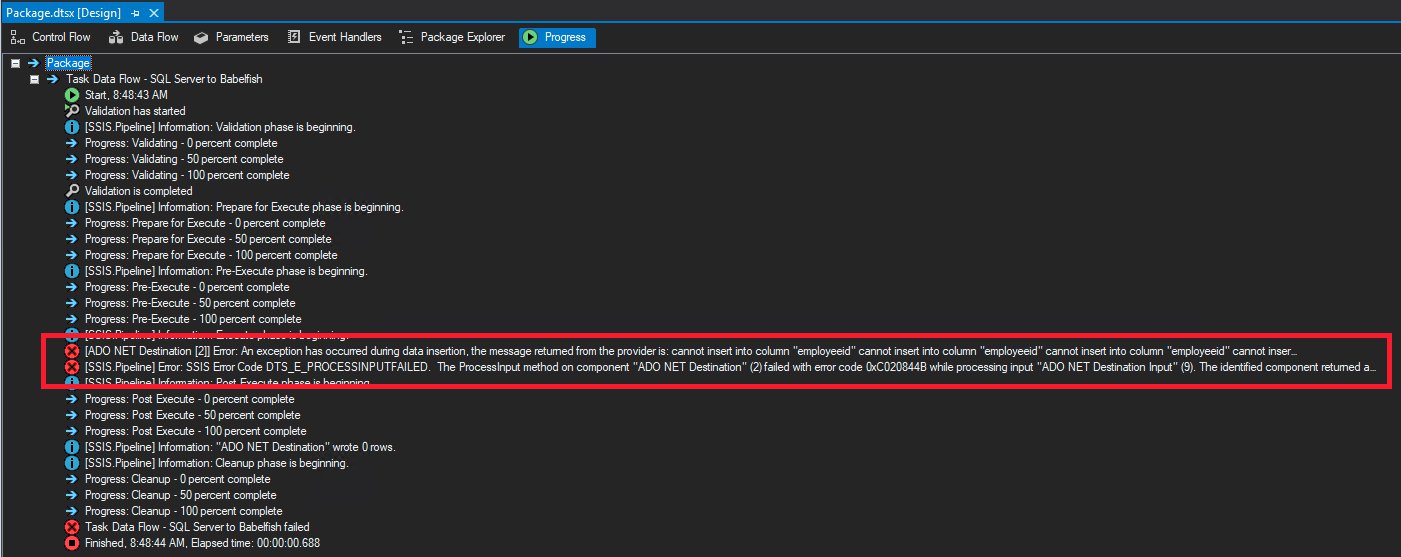
In our case, the table contains the identity column, so the Data Flow task fails with the following error.
{kind=link}
The Data Flow task is trying to insert the value into the identity column, which caused the task to fail. As a best practice, turn off the identity column during the data copy because you need to copy the existing data and don’t want to create an identity value at the target during data load.
Using a PostgreSQL client, connect to the Aurora PostgreSQL cluster on the PostgreSQL port (by default, 5432) and run the following SQL command to turn off the identity value for this table:
For details about connecting to a DB cluster using Aurora PostgreSQL, see Connecting to an Amazon Aurora PostgreSQL DB cluster.
Rerun the Data Flow task so that it can load the data from the SQL Server database to your Aurora PostgreSQL cluster.
{kind=link}
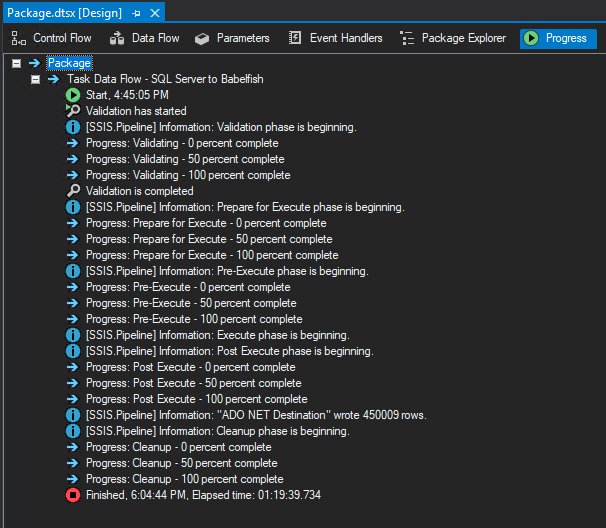
The following screenshot shows the load was successful. If you have multiple tables, you can create multiple data flow tasks accordingly to load data from SQL Server to the Babelfish-enabled Aurora database cluster.
{kind=link}
When the data load is complete, enable the identity value for this column by connecting to the Aurora PostgreSQL cluster endpoint on the PostgreSQL port (by default, 5432) using a PostgreSQL client, with the appropriate start value:
Note: When you alter the table to add GENERATED ALWAYS AS IDENTITY, make sure to get the max of the identity column and add one to it (max+1). In this case, we have 450009 records and our next increment should be 450010.
This way, any new records getting inserted in to the table respect the identity value. Below is a sample of loading multiple tables at a same time.
{kind=link}
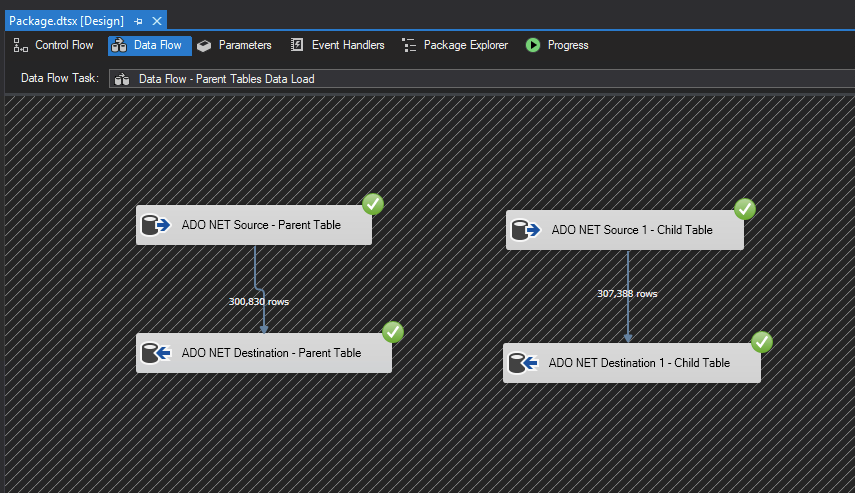{kind=link}
{kind=link}
SSIS parallel loads and performance improvements
You can run the SSIS package in parallel by taking advantage of the SSIS Scale Out Master and Worker deployment model. You must have SSIS installed on multiple servers, and you can run package execution in parallel in Scale Out mode from SQL Server Management mode. This feature is only available for SQL Server 2017 onwards in Enterprise Edition. For details about configuring the SSIS Scale Out feature, see Walkthrough: Set up Integration Services (SSIS) Scale Out.
Summary
In this post, we showed you the steps involved in creating an ADO.NET Data Flow task to load data from a SQL Server database to an Aurora PostgreSQL database with SSIS and Babelfish. Once the data is copied to the Aurora PostgreSQL cluster, you can point your SQL Server application to the cluster endpoint on the TDS port (by default,1433).
To learn more about Babelfish for Aurora PostgreSQL, check out Get started with Babelfish for Aurora PostgreSQL.
About the Authors
Yogeshwari Barot is Microsoft Specialist Senior Solution Architect at AWS, she has 22 years of experience working with different Microsoft technologies, her specialty is in SQL Server and different database technologies. Yogi has in depth AWS knowledge and expertise in running Microsoft workload on AWS.
Ramesh Kumar Venkatraman is a Solutions Architect at AWS who is passionate about containers and databases. He works with AWS customers to design, deploy and manage their AWS workloads and architectures. In his spare time, he loves to play with his two kids and follows cricket.
{kind=link}
Read MoreAWS Database Blog