

{kind=link}
Amazon Aurora is a relational database management system (RDBMS) built for the cloud with full MySQL and PostgreSQL compatibility. Aurora is designed to take advantage of the cloud in areas of scalability, availability, and durability, as well as combine the speed and reliability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases.
Aurora Global Database allows a single Aurora database to span multiple AWS Regions, thereby giving globally distributed applications fast local reads in each Region. It achieves subsecond cross-Region latencies through storage-based replication on dedicated infrastructure. The storage-based replication capability allows your DB instances to be fully devoted to serve application read and write workloads. An Aurora global database has a primary DB cluster in one Region, and can have up to five secondary DB clusters in different Regions. In the unlikely event your primary Region suffers a performance degradation or outage, you can promote one of the secondary Regions to take read/write responsibilities in under a minute.
You may want to migrate your Aurora database from one Region to another for a variety of reasons, such as moving to a Region closer to your customers, regulatory requirements, a change in business requirements, or customer demographics. You can do this using various methods, including cross-Region snapshot copy, logical replication, logical dump restore, or AWS Database Migration Service (AWS DMS), but the drawback is that they either require more effort or a longer downtime.
In this post, we use the managed planned failover feature of Aurora global database, which offers minimal effort and minimal downtime, to migrate an Aurora database to another Region. The managed planned failover feature is intended to be used in controlled environments, such as for operational maintenance and other planned operational procedures, and uses the Aurora global database’s replication topology to fail over your primary cluster to your choice of secondary Region with no data loss.
Solution overview
In this walkthrough, we migrate an Amazon Aurora PostgreSQL-Compatible Edition database from us-east-1 (source Region) to ca-central-1 (target Region) by using the cross-Region failover feature of Aurora global database.
The high-level steps are as follows:
Add ca-central-1 (target Region) as a secondary Region to your Aurora database. This creates the Aurora global database.
Fail over the global database to the secondary Region.
Remove the Aurora cluster in your source Region (us-east-1) from the global database.
Remove the Aurora cluster in your target Region (ca-central-1) from the global database. This creates your target Aurora cluster.
Prerequisites
The prerequisites for this solution include:
An AWS account.
An Aurora database. In this post, we use an Aurora PostgreSQL database, but the steps are similar for an Amazon Aurora MySQL-Compatible Edition database.
An AWS Identity and Access Management (IAM) role with sufficient permission to create and manage Aurora databases.
Limitations
Review the limitations for Aurora global databases prior to the migration. These limitations may make this method infeasible for your database migration in some cases. In other cases, the limitation may exist only during the lifecycle of the migration. Some of the limitations are as follows:
Change your Aurora database to an instance class compatible with Aurora global database prior to following the steps in this walkthrough. You may revert to your original instance class after the migration.
Disable Amazon RDS Proxy for your Aurora database prior to following the steps in this walkthrough. You can re-enable RDS Proxy after the migration.
Aurora multi-master clusters, Amazon Aurora Serverless v1, and backtracking aren’t available with Aurora global databases and can’t be enabled even after migration.
Add a secondary Region to your Aurora database
To add a secondary Region to your database, complete the following steps:
On the Amazon RDS console, choose Databases in the navigation pane.
Select the source Aurora cluster and on the Actions menu, choose Add AWS Region.
Fill in the required details for your secondary Aurora cluster, such as global database identifier, secondary Region, instance class, and more. This will eventually be your target Aurora cluster. You may want to mimic the settings from your source instance so that you have the same database capacity and configuration as the source Region after the migration is complete.
Choose Add Region.
{kind=link}
This creates your Aurora global database. It appears on your Databases page, as shown in the following screenshot.
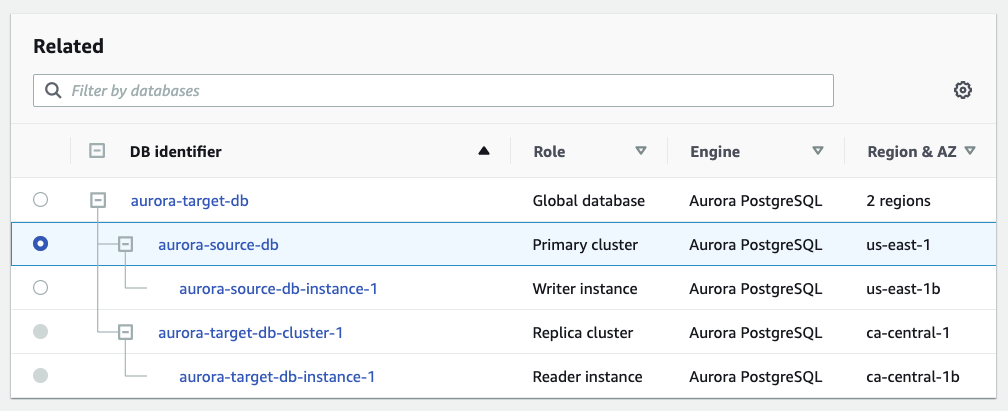{kind=link}
Remember to configure your secondary Aurora cluster to copy the options from your primary Aurora cluster. These configuration options include your read replica setup, cluster parameter and option groups, monitoring mechanisms such as Amazon CloudWatch Events and alarms, and your integration with other services such as AWS Secrets Manager and Amazon Simple Storage Service (Amazon S3).
Fail over the global database
Before you start the managed planned failover, we recommend you do the following to optimize application availability:
Perform the migration during non-peak hours or at another time when writes to the primary Aurora cluster are minimal.
Take applications offline to prevent writes from being sent to the primary cluster of the Aurora global database. This will reduce the failover time.
Check lag times for the secondary Aurora cluster in the Aurora global database. This metric tells you how far behind (in milliseconds) the secondary is to the primary cluster. Its value is directly proportional to the time it’ll take for Aurora to complete the failover.
To fail over your global database, complete the following steps:
On the Databases page, select the global database.
On the Actions menu, choose Fail over global database.
A pop-up box appears asking you to confirm the failover.
Choose the secondary Aurora cluster you want to fail over to, then choose Fail over global database.
{kind=link}
The primary Aurora cluster becomes read-only when the failover begins. The secondary Aurora cluster assumes the primary cluster role and promotes its read-only node to full writer status. Your application is unavailable for a short time while the primary and the secondary cluster assume their new roles. The top banner shows you the failover progress.
{kind=link}
All connections are lost during the failover and in-flight transactions must be retried.
The failover is complete when the secondary Aurora cluster catches up with the changes from the primary cluster. You can see the success notification in the top banner.
{kind=link}
You can now configure your application to use the new primary cluster’s database endpoints. You can find the endpoint names on the Connectivity & Security tab by selecting the DB identifier.
{kind=link}
Remove the Aurora clusters in your source Region from the global database (Optional)
Complete these steps only if you have completed the testing in the new Region and are ready to migrate the database. You can skip this section if you plan to operate out of both Regions or want to keep the source Region as a disaster recovery option.
The source Aurora cluster became the secondary cluster after the failover. Complete the following steps to remove the secondary Aurora cluster from the global database:
On the Databases page, select the secondary Aurora cluster.
On the Actions menu, choose Remove from global database.
Choose Remove and promote in the pop-up box when asked to confirm.
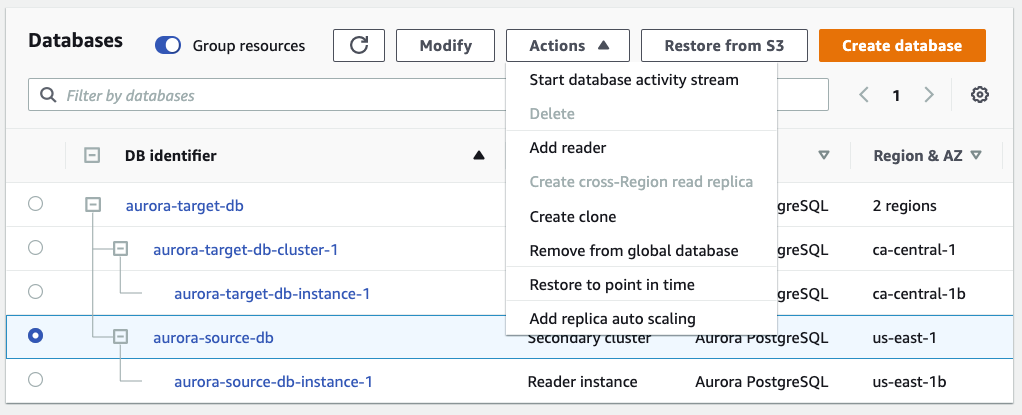{kind=link}
The promotion process should take less than a minute.
Remove the Aurora cluster in your target Region from the global database
The target Aurora cluster became the primary cluster after the failover. To remove the primary cluster from the global database, complete the following steps:
On the Databases page, select the primary DB cluster (target Region).
On the Actions menu, choose Remove from global database.
Choose Remove and promote in the pop-up box when asked to confirm.
{kind=link}
The promotion process should take less than a minute. When it’s complete, the primary DB cluster’s role becomes Regional. This is your target Aurora cluster.
Clean up unused resources
You can delete unused resources post-migration to the new Region:
On the Databases page, select the instance in your source Aurora cluster. Repeat the process if you have other instances in the source cluster.
On the Actions menu, choose Delete.
Select your global database and on the Actions menu, choose Delete.
{kind=link}
{kind=link}
Other considerations
There are other considerations when migrating using Aurora Global Database:
Cost – The costs for this solution fall into two categories (for more information, see Pricing Example):
The cost for the replicated write I/O between the primary Region and secondary Region.
The standard Aurora rates for DB instance, storage, I/O, data transfer, and backup storage.
Backups and snapshots – You can copy your existing snapshots across Regions. Specify the AWS Key Management Service (AWS KMS) key in the destination Region if your snapshot is encrypted.
Conclusion
In this post, we showed how you can migrate your Aurora MySQL or PostgreSQL database from one Region to another using the storage-based replication capability of Aurora Global Database. This solution requires minimal effort and downtime. It also limits the impact to database performance because the replication is performed at storage level.
Read more about how to use Aurora global databases and other use cases, such as disaster recovery.
About the authors
Vineedh George is a Sr. Solutions Architect helping organizations accelerate their adoption of cloud-based solutions.
{kind=link}
Tianxin Li is a Migration Solutions Architect with AWS Canada and is based in Toronto. He helps customers accelerate their migration journey to the cloud.
{kind=link}
Pratima Bhardwaj leads a team of Solution Architects at AWS. She is based in Toronto. She works with Enterprise customers in various industry sectors.
{kind=link}
Read MoreAWS Database Blog