

{kind=link}
As customers continue to come up with new use-cases for machine learning, data gravity is as important as ever. Where latency and network connectivity is not an issue, generating data in one location (such as a manufacturing facility) and sending it to the cloud for inference is acceptable for some use-cases. With other critical use-cases, such as fraud detection for financial transactions, product quality in manufacturing, or analyzing video surveillance in real-time, customers are faced with the challenges that come with having to move that data to the cloud first. One of the challenges customers are facing with performing inference in the cloud is the lack of real-time inference and/or security requirements preventing user data to be sent or stored in the cloud.
Tens of thousands of customers use Amazon SageMaker to accelerate their Machine Learning (ML) journey by helping data scientists and developers to prepare, build, train, and deploy machine learning models quickly. Once you’ve built and trained your ML model with SageMaker, you’ll want to deploy it somewhere to start collecting inputs to run through your model (inference). These models can be deployed and run on AWS, but we know that there are use-cases that don’t lend themselves well for running inference in an AWS Region while the inputs come from outside the Region. Cases include a customer’s data center, manufacturing facility, or autonomous vehicles. Predictions must be made in real-time when new data is available. When you want to run inference locally or on an edge device, a gateway, an appliance or on-premises server, you can optimize your ML models for the specific underlying hardware with Amazon SageMaker Neo. It is the easiest way to optimize ML models for edge devices, enabling you to train ML models once in the cloud and run them on any device. To increase efficiency of your edge ML operations, you can use Amazon SageMaker Edge Manager to automate the manual steps to optimize, test, deploy, monitor and maintain your models on fleets of edge devices.
In this blog post, we will talk about the different use-cases for inference at the edge and the way to accomplish it using Amazon SageMaker features and AWS Outposts. Let’s review each, before we dive into ML with AWS Outposts.
Amazon SageMaker – Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy machine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process to make it easier to develop high quality models.
Amazon SageMaker Edge Manager – Amazon SageMaker Edge Manager provides a software agent that runs on edge devices. The agent comes with a ML model optimized with SageMaker Neo automatically. You don’t need to have Neo runtime installed on your devices in order to take advantage of the model optimizations such as machine learning models performing at up to twice the speed with no loss in accuracy. Other benefits include reduction of hardware resource usage by up to 10x and the ability to run the same ML model on multiple hardware platforms. The agent also collects prediction data and sends a sample of the data to the AWS Region for monitoring, labeling, and retraining so you can keep models accurate over time.
AWS Outposts – AWS Outposts is a fully managed service that offers the same AWS infrastructure, AWS services, APIs, and tools to virtually any data center, co-location space, or on-premises facility for a truly consistent hybrid experience. AWS Outposts is ideal for workloads that require low latency access to on-premises systems, local data processing, data residency, and migration of applications with local system interdependencies.
AWS compute, storage, database, and other services run locally on Outposts. You can access the full range of AWS services available in the Region to build, manage, and scale your on-premises applications using familiar AWS services and tools.
Use cases
Due to low latency needs or large volumes of data, customers need ML inferencing at the edge. Two main use-cases require customers to implement these models for inference at the edge:
Low Latency – In many use-cases, the end user or application must provide inferencing in (near) real-time, requiring the model to be running at the edge. This is a common use case in industries such as Financial Services (risk analysis), Healthcare (medical imaging analysis), Autonomous Vehicles and Manufacturing (shop floor).
Large Volumes of Data – Large volumes of new data being generated at the edge means that inferencing needs to happen closer to where data is being generated. This is a common use case in IoT scenarios, such as in the oil and gas or utilities industries.
Scenario
For this scenario, let’s focus on the low latency use-case. A financial services customer wants to implement fraud detection on all customer transactions. They’ve decided on using Amazon SageMaker to build and train their model in an AWS Region. Given the distance between the data center in which they process transactions and an AWS Region, inference needs to be performed locally, in the same location as the transaction processing. They will use Amazon SageMaker Edge Manager to optimize the trained model to perform inference locally in their data center. The last piece is the compute. The customer is not interested in managing the hardware and their team is already trained in AWS development, operations and management. Given that, the customer chose AWS Outposts as their compute to run locally in their data center.
What does this look like technically? Let’s take a look at an architecture and then talk through the different pieces.
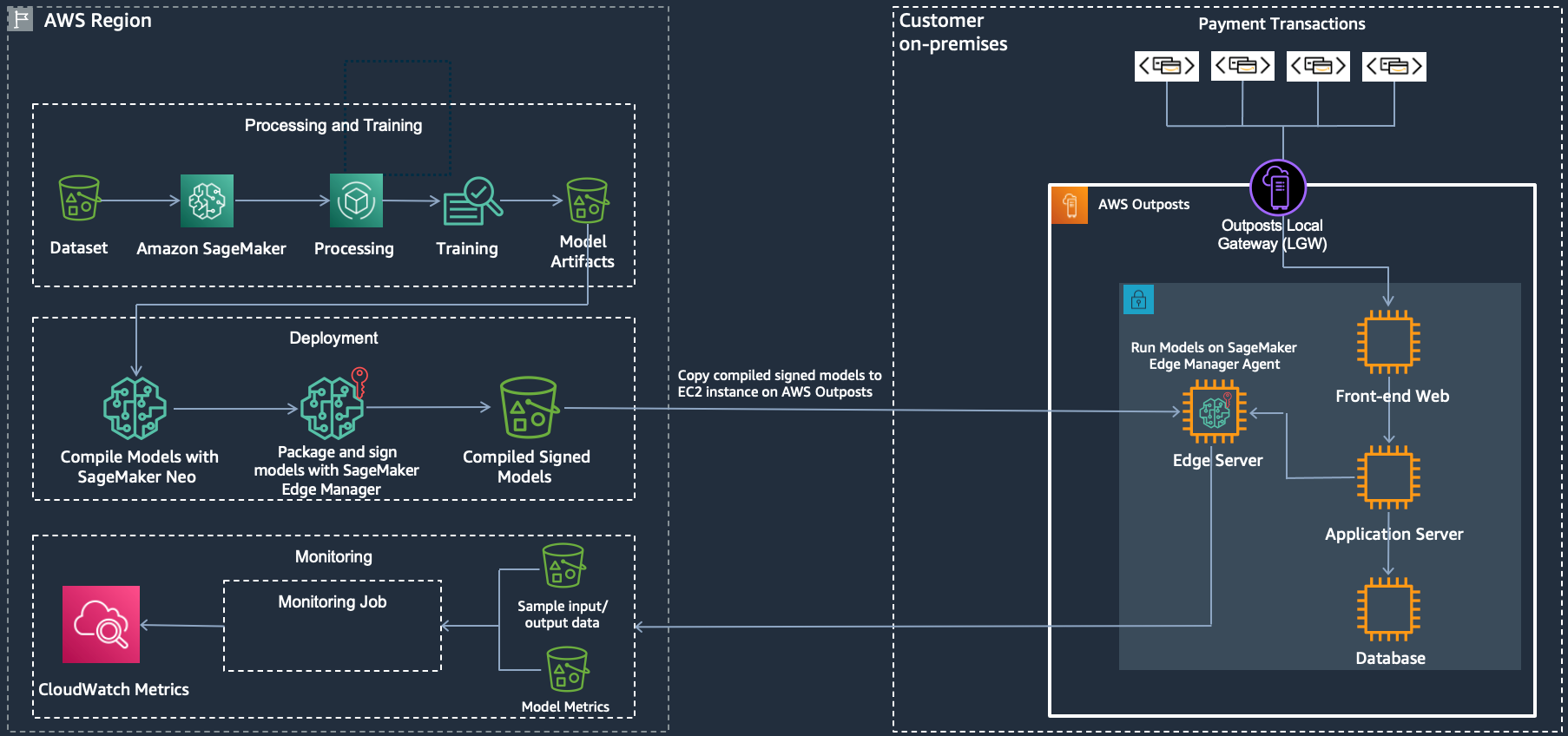{kind=link}
Let’s look at the flow. On the left, training of the model is done in the AWS Region with Amazon SageMaker for training and packaging. On the right, we have a data center, which can be the customer data center or a co-location facility, with AWS Outposts and SageMaker Edge Manager to do the inference.
AWS Region:
Load dataset into Amazon S3, which acts as input for model training.
Use Amazon SageMaker to do processing and training against the dataset.
Store the model artifacts in Amazon S3.
Compile the trained model using Amazon SageMaker Neo.
Package and sign the model with Amazon SageMaker Edge Manger and store in Amazon S3.
AWS Outposts
Launch an Amazon EC2 instance (use the instance family that you’ve optimized the model for) in a subnet that lives on the AWS Outposts.
Install Amazon SageMaker Edge Manager agent onto the instance. Learn more about installing the agent here.
Copy the compiled and signed model from Amazon S3 in the AWS Region to the Amazon EC2 instance on the AWS Outposts. Here’s an example using the AWS CLI to copy a model file (model-ml_m5.tar.gz) from Amazon S3 to the current directory (.):
{kind=link}
Financial transactions come into the data center and are routed into the Outposts via the Local Gateway (LGW), to the front-end web server and then to the application server.
The transaction gets stored in the database and at the same time, the application server generates a customer profile based on multiple variables, including transaction history.
The customer profile is sent to Edge Manager agent to run inference against the compiled model using the customer profile as input.
The fraud detection model will generate a score once inference is complete. Based on that score the application server will return one of the following back to the client:
Approve the transaction.
Ask for 2nd factor (two factor authentication).
Deny the transaction.
Additionally, sample input/output data as well as model metrics are captured and sent back to the AWS Region for monitoring with Amazon SageMaker Edge Manager.
AWS Region
Monitor your model with Amazon SageMaker Edge Manager and push metrics in to CloudWatch, which can be used as a feedback loop to improve the model’s performance on an on-going basis.
Considerations for Using Amazon SageMaker Edge Manager with AWS Outposts
Factors to consider when choosing between inference in an AWS Region vs AWS Outposts:
Security: Whether other factors are relevant to your use-case or not, security of your data is a priority. If the data you must perform inference on is not permissible to be stored in the cloud, AWS Outposts for inference at the edge will perform inference without sacrificing data security.
Real-time processing: Is the data you need to perform inference on time bound? If the value of the data diminishes as more time passes, then sending the data to an AWS Region for inference may not have value.
WAN Connectivity: Along with the speed and quality of your connection, the time from where the data is generated and sent to the cloud (latency) is also important. You may only need near real-time inference and cloud-based inference is an option.
Do you have enough bandwidth to send the amount of data back to an AWS Region? If not, is the required bandwidth cost effective?
Is the quality of network link back to the AWS Region suitable to meet your requirements?
What are the consequences of a network outage?
If link quality is an issue, if bandwidth costs are not reasonable, or a network outage is detrimental to your business, then using AWS Outposts for inference at the edge can help to ensure that you’re able to continually perform inference regardless of the state of your WAN connectivity.
As of the writing of this blog post, Amazon SageMaker Edge Manager supports common CPU (ARM, x86), GPU (ARM, Nvidia) based devices with Linux and Windows operating systems. Over time, SageMaker Edge Manager will expand to support more embedded processors and mobile platforms that are also supported by SageMaker Neo.
Additionally, you need to use Amazon SageMaker Neo to compile the model in order to use Amazon SageMaker Edge Manager. Amazon SageMaker Neo converts and compiles your models into an executable that you can then package and deploy on to your edge devices. Once the model package is deployed, Amazon SageMaker Edge Manager agent will unpack the model package and run the model on the device.
Conclusion
Whether it’s providing quality assurance to manufactured goods, real-time monitoring of cameras, wind farms, or medical devices (and countless other use-cases), Amazon SageMaker combined with AWS Outposts provides you with world class machine learning capabilities and inference at the edge.
To learn more about Amazon SageMaker Edge Manager, you can visit the Edge Manager product page and check out this demo. To learn more about AWS Outposts, visit the Outposts product page and check out this introduction.
About the Author
Josh Coen is a Senior Solutions Architect at AWS specializing in AWS Outposts. Prior to joining AWS, Josh was a Cloud Architect at Sirius, a national technology systems integrator, where he helped build and run their AWS practice. Josh has a BS in Information Technology and has been in the IT industry since 2003.
{kind=link}
Mani Khanuja is an Artificial Intelligence and Machine Learning Specialist SA at Amazon Web Services (AWS). She helps customers use machine learning to solve their business challenges using AWS. She spends most of her time diving deep and teaching customers on AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. She is passionate about ML at edge and has created her own lab with a self-driving kit and prototype manufacturing production line, where she spends a lot of her free time.
{kind=link}
Read MoreAWS Machine Learning Blog