

{kind=link}
As enterprises move from running ad hoc machine learning (ML) models to using AI/ML to transform their business at scale, the adoption of ML Operations (MLOps) becomes inevitable. As shown in the following figure, the ML lifecycle begins with framing a business problem as an ML use case followed by a series of phases, including data preparation, feature engineering, model building, deployment, continuous monitoring, and retraining. For many enterprises, a lot of these steps are still manual and loosely integrated with each other. Therefore, it’s important to automate the end-to-end ML lifecycle, which enables frequent experiments to drive better business outcomes. Data preparation is one of the crucial steps in this lifecycle, because the ML model’s accuracy depends on the quality of the training dataset.
Data scientists and ML engineers spend somewhere between 70–80% of their time collecting, analyzing, cleaning, and transforming data required for model training. Amazon SageMaker Data Wrangler is a fully managed capability of Amazon SageMaker that makes it faster for data scientists and ML engineers to analyze and prepare data for their ML projects with little to no code. When it comes to operationalizing an end-to-end ML lifecycle, data preparation is almost always the first step in the process. Given that there are many ways to build an end-to-end ML pipeline, in this post we discuss how you can easily integrate Data Wrangler with some of the well-known workflow automation and orchestration technologies.
Solution overview
In this post, we demonstrate how users can integrate data preparation using Data Wrangler with Amazon SageMaker Pipelines, AWS Step Functions, and Apache Airflow with Amazon Managed Workflow for Apache Airflow (Amazon MWAA). Pipelines is a SageMaker feature that is a purpose-built and easy-to-use continuous integration and continuous delivery (CI/CD) service for ML. Step Functions is a serverless, low-code visual workflow service used to orchestrate AWS services and automate business processes. Amazon MWAA is a managed orchestration service for Apache Airflow that makes it easier to operate end-to-end data and ML pipelines.
For demonstration purposes, we consider a use case to prepare data to train an ML model with the SageMaker built-in XGBoost algorithm that will help us identify fraudulent vehicle insurance claims. We used a synthetically generated set of sample data to train the model and create a SageMaker model using the model artifacts from the training process. Our goal is to operationalize this process end to end by setting up an ML workflow. Although ML workflows can be more elaborate, we use a minimal workflow for demonstration purposes. The first step of the workflow is data preparation with Data Wrangler, followed by a model training step, and finally a model creation step. The following diagram illustrates our solution workflow.
In the following sections, we walk you through how to set up a Data Wrangler flow and integrate Data Wrangler with Pipelines, Step Functions, and Apache Airflow.
Set up a Data Wrangler flow
We start by creating a Data Wrangler flow, also called a data flow, using the data flow UI via the Amazon SageMaker Studio IDE. Our sample dataset consists of two data files: claims.csv and customers.csv, which are stored in an Amazon Simple Storage Service (Amazon S3) bucket. We use the data flow UI to apply Data Wrangler’s built-in transformations such categorical encoding, string formatting, and imputation to the feature columns in each of these files. We also apply custom transformation to a few feature columns using a few lines of custom Python code with Pandas DataFrame. The following screenshot shows the transforms applied to the claims.csv file in the data flow UI.
Finally, we join the results of the applied transforms of the two data files to generate a single training dataset for our model training. We use Data Wrangler’s built-in join datasets capability, which lets us perform SQL-like join operations on tabular data. The following screenshot shows the data flow in the data flow UI in Studio. For step-by-step instructions to create the data flow using Data Wrangler, refer to the GitHub repository.
You can now use the data flow (.flow) file to perform data transformations on our raw data files. The data flow UI can automatically generate Python notebooks for us to use and integrate directly with Pipelines using the SageMaker SDK. For Step Functions, we use the AWS Step Functions Data Science Python SDK to integrate our Data Wrangler processing with a Step Functions pipeline. For Amazon MWAA, we use a custom Airflow operator and the Airflow SageMaker operator. We discuss each of these approaches in detail in the following sections.
Integrate Data Wrangler with Pipelines
SageMaker Pipelines is a native workflow orchestration tool for building ML pipelines that take advantage of direct SageMaker integration. Along with the SageMaker model registry, Pipelines improves the operational resilience and reproducibility of your ML workflows. These workflow automation components enable you to easily scale your ability to build, train, test, and deploy hundreds of models in production; iterate faster; reduce errors due to manual orchestration; and build repeatable mechanisms. Each step in the pipeline can keep track of the lineage, and intermediate steps can be cached for quickly rerunning the pipeline. You can create pipelines using the SageMaker Python SDK.
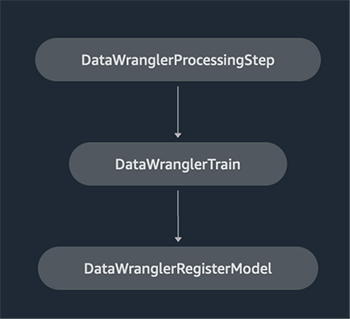
A workflow built with SageMaker pipelines consists of a sequence of steps forming a Directed Acyclic Graph (DAG). In this example, we begin with a processing step, which runs a SageMaker Processing job based on the Data Wrangler’s flow file to create a training dataset. We then continue with a training step, where we train an XGBoost model using SageMaker’s built-in XGBoost algorithm and the training dataset created in the previous step. After a model has been trained, we end this workflow with a RegisterModel step to register the trained model with the SageMaker model registry.
{kind=link}
Installation and walkthrough
To run this sample, we use a Jupyter notebook running Python3 on a Data Science kernel image in a Studio environment. You can also run it on a Jupyter notebook instance locally on your machine by setting up the credentials to assume the SageMaker execution role. The notebook is lightweight and can be run on an ml.t3.medium instance. Detailed step-by-step instructions can be found in the GitHub repository.
You can either use the export feature in Data Wrangler to generate the Pipelines code, or build your own script from scratch. In our sample repository, we use a combination of both approaches for simplicity. At a high level, the following are the steps to build and run the Pipelines workflow:
Generate a flow file from Data Wrangler or use the setup script to generate a flow file from a preconfigured template.
Create an Amazon Simple Storage Service (Amazon S3) bucket and upload your flow file and input files to the bucket. In our sample notebook, we use the SageMaker default S3 bucket.
Follow the instructions in the notebook to create a Processor object based on the Data Wrangler flow file, and an Estimator object with the parameters of the training job.
In our example, because we only use SageMaker features and the default S3 bucket, we can use Studio’s default execution role. The same AWS Identity and Access Management (IAM) role is assumed by the pipeline run, the processing job, and the training job. You can further customize the execution role according to minimum privilege.
Continue with the instructions to create a pipeline with steps referencing the Processor and Estimator objects, and then run the pipeline. The processing and training jobs run on SageMaker managed environments and take a few minutes to complete.
In Studio, you can see the pipeline details monitor the pipeline run. You can also monitor the underlying processing and training jobs from the SageMaker console or from Amazon CloudWatch.
Integrate Data Wrangler with Step Functions
With Step Functions, you can express complex business logic as low-code, event-driven workflows that connect different AWS services. The Step Functions Data Science SDK is an open-source library that allows data scientists to create workflows that can preprocess datasets and build, deploy, and monitor ML models using SageMaker and Step Functions. Step Functions is based on state machines and tasks. Step Functions creates workflows out of steps called states, and expresses that workflow in the Amazon States Language. When you create a workflow using the Step Functions Data Science SDK, it creates a state machine representing your workflow and steps in Step Functions.
For this use case, we built a Step Functions workflow based on the common pattern used in this post that includes a processing step, training step, and RegisterModel step. In this case, we import these steps from the Step Functions Data Science Python SDK. We chain these steps in the same order to create a Step Functions workflow. The workflow uses the flow file that was generated from Data Wrangler, but you can also use your own Data Wrangler flow file. We reuse some code from the Data Wrangler export feature for simplicity. We run the data preprocessing logic generated by Data Wrangler flow file to create a training dataset, train a model using the XGBoost algorithm, and save the trained model artifact as a SageMaker model. Additionally, in the GitHub repo, we also show how Step Functions allows us to try and catch errors, and handle failures and retries with FailStateStep and CatchStateStep.
The resulting flow diagram, as shown in the following screenshot, is available on the Step Functions console after the workflow has started. This helps data scientists and engineers visualize the entire workflow and every step within it, and access the linked CloudWatch logs for every step.
Installation and walkthrough
To run this sample, we use a Python notebook running with a Data Science kernel in a Studio environment. You can also run it on a Python notebook instance locally on your machine by setting up the credentials to assume the SageMaker execution role. The notebook is lightweight and can be run on a t3 medium instance for example. Detailed step-by-step instructions can be found in the GitHub repository.
You can either use the export feature in Data Wrangler to generate the Pipelines code and modify it for Step Functions or build your own script from scratch. In our sample repository, we use a combination of both approaches for simplicity. At a high level, the following are the steps to build and run the Step Functions workflow:
Generate a flow file from Data Wrangler or use the setup script to generate a flow file from a preconfigured template.
Create an S3 bucket and upload your flow file and input files to the bucket.
Configure your SageMaker execution role with the required permissions as mentioned earlier. Refer to the GitHub repository for detailed instructions.
Follow the instructions to run the notebook in the repository to start a workflow. The processing job runs on a SageMaker-managed Spark environment and can take few minutes to complete.
Go to Step Functions console and track the workflow visually. You can also navigate to the linked CloudWatch logs to debug errors.
Let’s review some important sections of the code here. To define the workflow, we first define the steps in the workflow for the Step Function state machine. The first step is the data_wrangler_step for data processing, which uses the Data Wrangler flow file as an input to transform the raw data files. We also define a model training step and a model creation step named training_step and model_step, respectively. Finally, we create a workflow by chaining all the steps we created, as shown in the following code:
In our example, we built the workflow to take job names as parameters because they’re unique and need to be randomly generated during every pipeline run. We pass these names when the workflow runs. You can also schedule Step Functions workflow to run using CloudWatch (see Schedule a Serverless Workflow with AWS Step Functions and Amazon CloudWatch), invoked using Amazon S3 Events, or invoked from Amazon EventBridge (see Create an EventBridge rule that triggers a Step Functions workflow). For demonstration purposes, we can invoke the Step Functions workflow from the Step Functions console UI or using the following code from the notebook.
Integrate Data Wrangler with Apache Airflow
Another popular way of creating ML workflows is using Apache Airflow. Apache Airflow is an open-source platform that allows you to programmatically author, schedule, and monitor workflows. Amazon MWAA makes it easy to set up and operate end-to-end ML pipelines with Apache Airflow in the cloud at scale. An Airflow pipeline consists of a sequence of tasks, also referred to as a workflow. A workflow is defined as a DAG that encapsulates the tasks and the dependencies between them, defining how they should run within the workflow.
We created an Airflow DAG within an Amazon MWAA environment to implement our MLOps workflow. Each task in the workflow is an executable unit, written in Python programming language, that performs some action. A task can either be an operator or a sensor. In our case, we use an Airflow Python operator along with SageMaker Python SDK to run the Data Wrangler Python script, and use Airflow’s natively supported SageMaker operators to train the SageMaker built-in XGBoost algorithm and create the model from the resulting artifacts. We also created a helpful custom Data Wrangler operator (SageMakerDataWranglerOperator) for Apache Airflow, which you can use to process Data Wrangler flow files for data processing without the need for any additional code.
The following screenshot shows the Airflow DAG with five steps to implement our MLOps workflow.
{kind=link}
The Start step uses a Python operator to initialize configurations for the rest of the steps in the workflow. SageMaker_DataWrangler_Step uses SageMakerDataWranglerOperator and the data flow file we created earlier. SageMaker_training_step and SageMaker_create_model_step use the built-in SageMaker operators for model training and model creation, respectively. Our Amazon MWAA environment uses the smallest instance type (mw1.small), because the bulk of the processing is done via Processing jobs, which uses its own instance type that can be defined as configuration parameters within the workflow.
Installation and walkthrough
Detailed step-by-step installation instructions to deploy this solution can be found in our GitHub repository. We used a Jupyter notebook with Python code cells to set up the Airflow DAG. Assuming you have already generated the data flow file, the following is a high-level overview of the installation steps:
Create an S3 bucket and subsequent folders required by Amazon MWAA.
Create an Amazon MWAA environment. Note that we used Airflow version 2.0.2 for this solution.
Create and upload a requirements.txt file with all the Python dependencies required by the Airflow tasks and upload it to the /requirements directory within the Amazon MWAA primary S3 bucket. This is used by the managed Airflow environment to install the Python dependencies.
Upload the SMDataWranglerOperator.py file to the /dags directory. This Python script contains code for the custom Airflow operator for Data Wrangler. This operator can be used for tasks to process any .flow file.
Create and upload the config.py script to the /dags directory. This Python script is used for the first step of our DAG to create configuration objects required by the remaining steps of the workflow.
Finally, create and upload the ml_pipelines.py file to the /dags directory. This script contains the DAG definition for the Airflow workflow. This is where we define each of the tasks, and set up dependencies between them. Amazon MWAA periodically polls the /dags directory to run this script to create the DAG or update the existing one with any latest changes.
The following is the code for SageMaker_DataWrangler_step, which uses the custom SageMakerDataWranglerOperator. With just a few lines of code in your DAG definition Python script, you can point the SageMakerDataWranglerOperator to the Data Wrangler flow file location (which is an S3 location). Behind the scenes, this operator uses SageMaker Processing jobs to process the .flow file in order to apply the defined transforms to your raw data files. You can also specify the type of instance and number of instances needed by the Data Wrangler processing job.
The config parameter accepts a dictionary (key-value pairs) of additional configurations required by the processing job, such as the output prefix of the final output file, type of output file (CSV or Parquet), and URI for the built-in Data Wrangler container image. The following code is what the config dictionary for SageMakerDataWranglerOperator looks like. These configurations are required for a SageMaker Processing processor. For details of each of these config parameters, refer to sagemaker.processing.Processor().
Clean up
To avoid incurring future charges, delete the resources created for the solutions you implemented.
Follow these instructions provided in the GitHub repository to clean up resources created by the SageMaker Pipelines solution.
Follow these instructions provided in the GitHub repository to clean up resources created by the Step Functions solution.
Follow these instructions provided in the GitHub repository to clean up resources created by the Amazon MWAA solution.
Conclusion
This post demonstrated how you can easily integrate Data Wrangler with some of the well-known workflow automation and orchestration technologies in AWS. We first reviewed a sample use case and architecture for the solution that uses Data Wrangler for data preprocessing. We then demonstrated how you can integrate Data Wrangler with Pipelines, Step Functions, and Amazon MWAA.
As a next step, you can find and try out the code samples and notebooks in our GitHub repository using the detailed instructions for each of the solutions discussed in this post. To learn more about how Data Wrangler can help your ML workloads, visit the Data Wrangler product page and Prepare ML Data with Amazon SageMaker Data Wrangler.
About the authors
Rodrigo Alarcon is a Senior ML Strategy Solutions Architect with AWS based out of Santiago, Chile. In his role, Rodrigo helps companies of different sizes generate business outcomes through cloud-based AI and ML solutions. His interests include machine learning and cybersecurity.
{kind=link}
Ganapathi Krishnamoorthi is a Senior ML Solutions Architect at AWS. Ganapathi provides prescriptive guidance to startup and enterprise customers helping them to design and deploy cloud applications at scale. He is specialized in machine learning and is focused on helping customers leverage AI/ML for their business outcomes. When not at work, he enjoys exploring outdoors and listening to music.
{kind=link}
Anjan Biswas is a Senior AI Services Solutions Architect with focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand, and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations and is actively helping customers get started and scale on AWS AI services.
{kind=link}
Read MoreAWS Machine Learning Blog