

{kind=link}
Reading the printed word opens up a world of information, imagination, and creativity. However, scanned books and documents may be difficult for people with vision impairment and learning disabilities to consume. In addition, some people prefer to listen to text-based content versus reading it. A document-to-speech solution extends the reach of digital content by giving text content a voice. It has uses across different industry sectors, such as:
Entertainment– You can create your own audiobooks.
Education – Students can convert their lecture notes to speech and access them anywhere.
Patient care – Dosage instructions and precautions are typically in small fonts and hard to read. With this solution, you could take a picture, convert to speech, and listen to the instructions in order to avoid potential harm.
The document-to-speech solution converts scanned books or documents taken on a mobile phone or handheld device automatically to speech. This solution extends the capabilities of Amazon Polly. We extract text from scanned documents using Amazon Textract, and then convert the text to speech using Amazon Polly. Solution benefits include mobility and freedom for the user plus enhanced learning capabilities for early readers.
The idea originated from Harry Pan, one of the blog author’s favorite parent-child activities – reading books. “My son enjoys storybooks, but is too young to read on his own. I love reading to him, but sometimes I need to work or tend to household chores. This sparked an idea to build a document-to-speech solution that could read to him when I was busy”.
Overview of solution
The solution is an event-driven serverless architecture that uses Amazon AI services to convert scanned documents to speech. Amazon Textract and Amazon Polly belong to the topmost layer of the AWS machine learning (ML) stack. These services allow developers to easily add intelligence to any application without prior ML knowledge.
Amazon Textract is an ML service that automatically extracts text, handwriting, and data from scanned documents. It goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables. Amazon Textract uses ML to read and process any type of document, accurately extracting text, handwriting, tables, and other data without any manual effort.
Amazon Polly is a text-to-speech service that turns text into lifelike speech, allowing you to create applications that talk and to build entirely new categories of speech-enabled products. Amazon Polly uses advanced deep learning technologies to synthesize speech that sounds like a human voice.
There are significant advantages of using Amazon AI services:
They take little effort; you can integrate these APIs into any application
They offer highly scalable and cost-effective solutions
Your organization can shift its focus from development of custom models to business outcomes
The solution also uses Amazon API Gateway to quickly stand up APIs that the web UI can invoke to perform operations like uploading documents and converting scanned documents to speech. API Gateway provides a scalable way to create, publish, and maintain secure APIs. In this solution, we also use API Gateway WebSocket support to establish a persistent connection between the web UI and the backend, so the backend can keep sending progress updates to user in real time.
We use AWS Lambda functions to trigger Amazon Textract and Amazon Polly asynchronous jobs. Lambda is a highly available and scalable compute service that lets you run code without provisioning resources.
We use an AWS Step Functions state machine to orchestrate two parallel Lambda functions – one to moderate text and the other to store text in Amazon Simple Storage Service (Amazon S3). Step Functions is a serverless orchestration service to define application workflows as a series of event-driven steps.
Architecture and code
As described in the previous section, we use two key AI services, Amazon Textract and Amazon Polly, to build a document-to-speech conversion solution. One additional service that we haven’t touched upon is AWS Amplify. Amplify allows front-end developers to quickly build extensible, full stack web and mobile apps. With Amplify, you can easily configure a backend, connect an application to it within minutes, and scale effortlessly. We use Amplify to host a web UI that allows users to upload their scanned documents.
You can also use your own UI without Amplify. As we dive deep into this solution, we show how you can use any client application to connect to the backend to convert documents to speech – as long as they support REST and WebSocket APIs. The web UI here is simply to demonstrate key features of this solution. As of this writing, the solution supports JPEG, PNG, and PDF input formats, and the English language.
The following diagram illustrates the solution architecture.
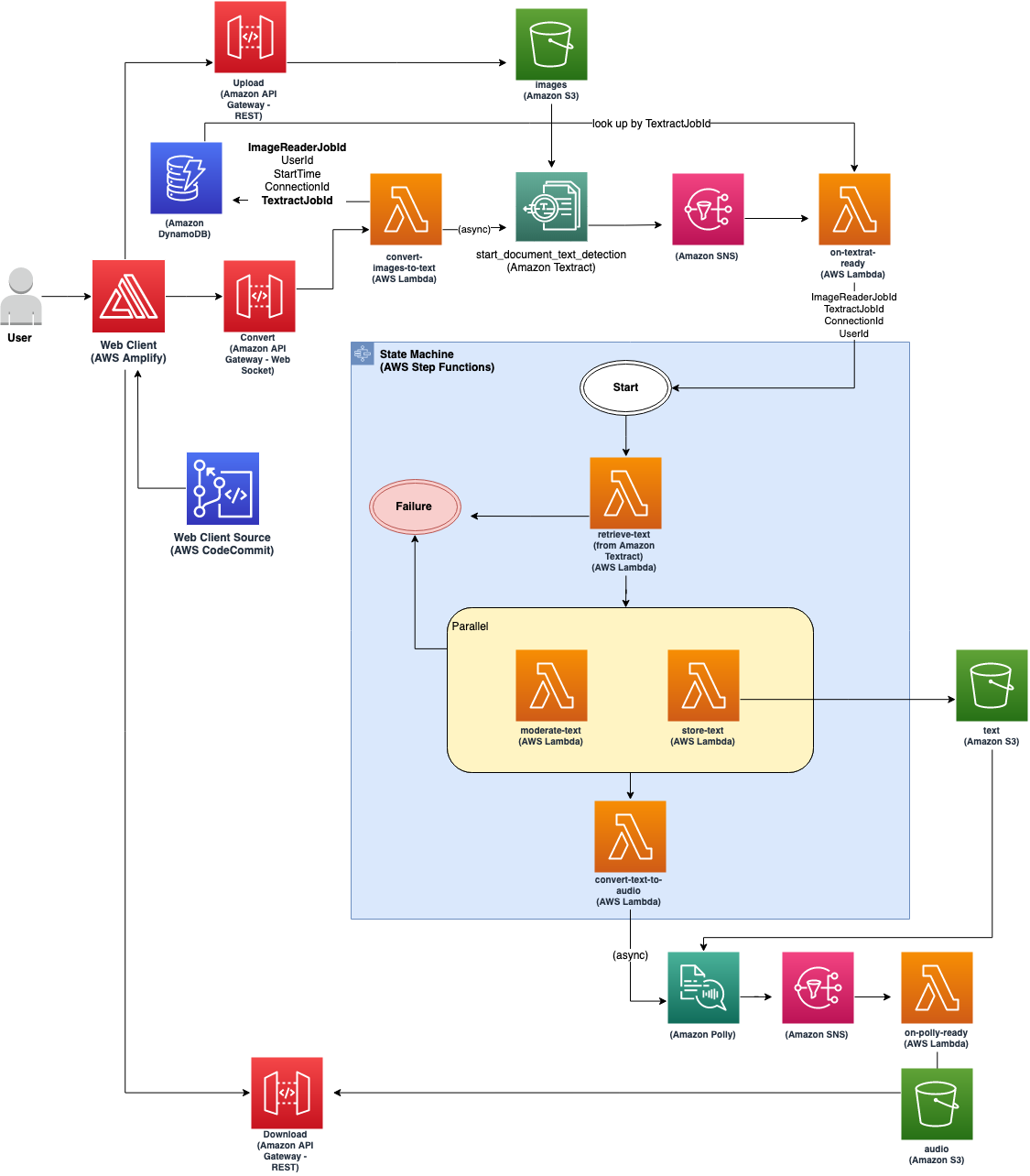{kind=link}
We walk through this architecture by following the path of a single user request:
The user visits the web UI hosted on Amplify. The UI code is the index.html file in the client folder of the code repository.
The user chooses a JPG, PDF, or PNG file to upload using the web UI.
The user initiates the Convert & Play Audio process from the web UI, which uploads the input file to an S3 bucket, through a REST API hosted on API Gateway.
When the upload is complete, the document-to-speech conversion starts as a background process:
During the conversion, the web client keeps a persistent WebSocket connection with the API Gateway. This allows the backend processes (Lambda functions) to continuously send progress updates to the web client.
The request goes through the API Gateway and triggers the Lambda function convert-images-to-text. This function calls Amazon Textract asynchronously to convert the document to text.
When the image-to-text conversion is complete, Amazon Textract sends a notification to Amazon Simple Notification Service (Amazon SNS).
The notification triggers the Lambda function on-textract-ready, which kicks off a Step Functions state machine.
The state machine orchestrates the following steps:
It runs the Lambda function retrieve-text to obtain the converted text from Amazon Textract.
It then runs Lambda functions moderate-text and store-text in parallel. moderate-text stops further processing when undesirable words are detected, and store-text stores a copy of the converted text to an S3 bucket.
After the parallel steps are complete, the state machine runs the Lambda function convert-text-to-audio, which invokes Amazon Polly asynchronously with the converted text, for speech conversion. The state machine finishes after this step.
Similar to Amazon Textract, Amazon Polly sends a notification to Amazon SNS when the job is done. The notification triggers the Lambda function on-polly-ready, which sends a final message to the web UI along with the Amazon S3 location of the converted audio file.
The web UI downloads the final converted audio file from Amazon S3 via a REST API, and then plays it for the user.
The application uses an Amazon DynamoDB table to track job information such as Amazon Textract job ID, Amazon Polly job ID, and more.
The code is hosted on GitHub and is deployed using AWS Cloud Development Kit (AWS CDK), an open-source software development framework to define cloud application resources using familiar programming languages. AWS CDK provisions resources in a repeatable manner through AWS CloudFormation.
Prerequisites
The only prerequisite to deploy this solution is an AWS account.
Deploy the solution
The following steps detail how to deploy the application:
Sign in to your AWS account.
On the AWS Cloud9 console, open an existing environment, or choose Create environment to create a new one.
In your AWS Cloud9 IDE, on the Window menu, choose New Terminal to open a terminal.
All the following steps are done in the same terminal.
Clone the git repository and enter the project directory:
Create a Python virtual environment:
After the init process is complete and the virtual environment is created, use the following step to activate your virtual environment:
After the virtual environment is activated, install the required dependencies:
You can now synthesize the CloudFormation templates from the AWS CDK code:
Deploy the AWS CDK application and capture AWS CDK outputs needed later:
You must confirm changes to be deployed for each stack. You can check the stack creation progress on the AWS Cloud Formation console.
To visit the web client, run the following command and follow its output to kick off front-end deployment and use the web client:
Key things to note:
The extract-cdk-outputs.py script prints out the URL of the web UI. The script also prints out strings of the S3 bucket name, file API endpoint, and conversion API endpoint, which need to be set on the web UI before uploading a document.
You can set the list of undesirable words in the variable in the moderate-text Lambda function.
Use the application
The following steps demonstrate how to use the application via the web UI.
Following the last step of the deployment, fill in the fields for S3 Bucket Name, File Endpoint, and Conversion Endpoint in the web UI.
Choose Choose File to upload an input file.
Choose Convert & Play Audio.
{kind=link}
The web UI shows the progress of the ongoing conversion.
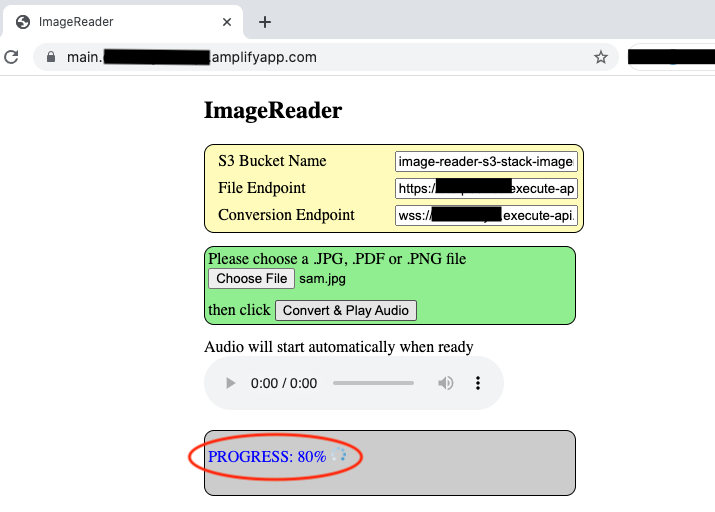{kind=link}
The web UI plays the audio automatically when the conversion is complete.
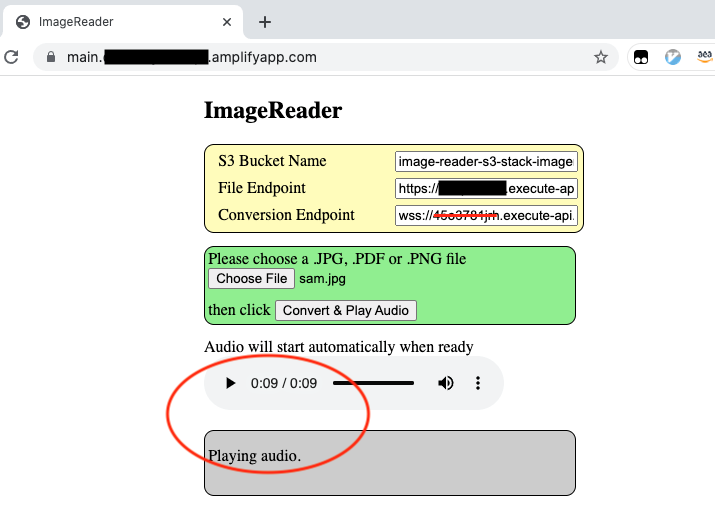{kind=link}
Clean up
Run the following command to delete all resources and avoid incurring future charges:
Conclusion
In this post, we demonstrated a solution to quickly deploy a document-to-speech conversion application by using two powerful AI services: Amazon Textract and Amazon Polly. We showed how the solution works and provided a detailed walkthrough of the code and deployment steps. This solution is meant to be a reference architecture or quick start that you can further enhance. Notably, you could add support for more human languages, add a queue for buffering incoming requests, and authenticate users.
As discussed in this post, we see multiple use cases for this solution across different industry verticals. Give it a try and let us know how this solved your use case by leaving feedback in the comments section. You can access the resources for the solution in the document to speech GitHub repository.
References
More information is available at the following resources:
Amazon Textract Developer Guide
Amazon Polly Developer Guide
Working with WebSocket APIs
AWS CDK Construct Library
AWS Amplify Construct Library
About the Authors
Harry Pan is an ISV Solutions Architect at Amazon Web Services based in the San Francisco Bay Area, where he helps software companies achieve their business goals by building well-architected IT systems. He loves spending his spare time with his family, as well as playing tennis, coding in Haskell, and traveling.
Chaitra Mathur is a Principal Solutions Architect at AWS. She guides partners and customers in building highly scalable, reliable, secure, and cost-effective solutions on AWS. In her spare time, she enjoys reading, yoga and spending time with her daughters.
Read MoreAWS Machine Learning Blog