

{kind=link}
Amazon Web Services (AWS) customers migrating their Apache Cassandra workloads to Amazon Keyspaces (for Apache Cassandra) have rediscovered Cassandra’s lightweight transactions (LWT) API. Amazon Keyspaces LWTs have consistent performance, reliable scalability, and improved isolation that allow developers to use LWTs with mission critical workloads. With Amazon Keyspaces, LWTs have similar single digit millisecond latencies as non-LWTs. Additionally, LWTs can be used in combination with non-LWTs without trading off isolation. In this post, we take a close look at Amazon Keyspaces realtime LWTs, their performance characteristics, new levels of isolation, and advanced design patterns.
Apache Cassandra lightweight transactions
Lightweight transactions (LWT) is an Apache Cassandra API feature that allows developers to perform conditional update operations against their table data. Conditional update operations are useful when inserting, updating and deleting records based on conditions that evaluate the current state. Using this feature, developers can implement APIs with delivery semantics such as at-least-once or at-most-once, and design patterns such as optimistic locking.
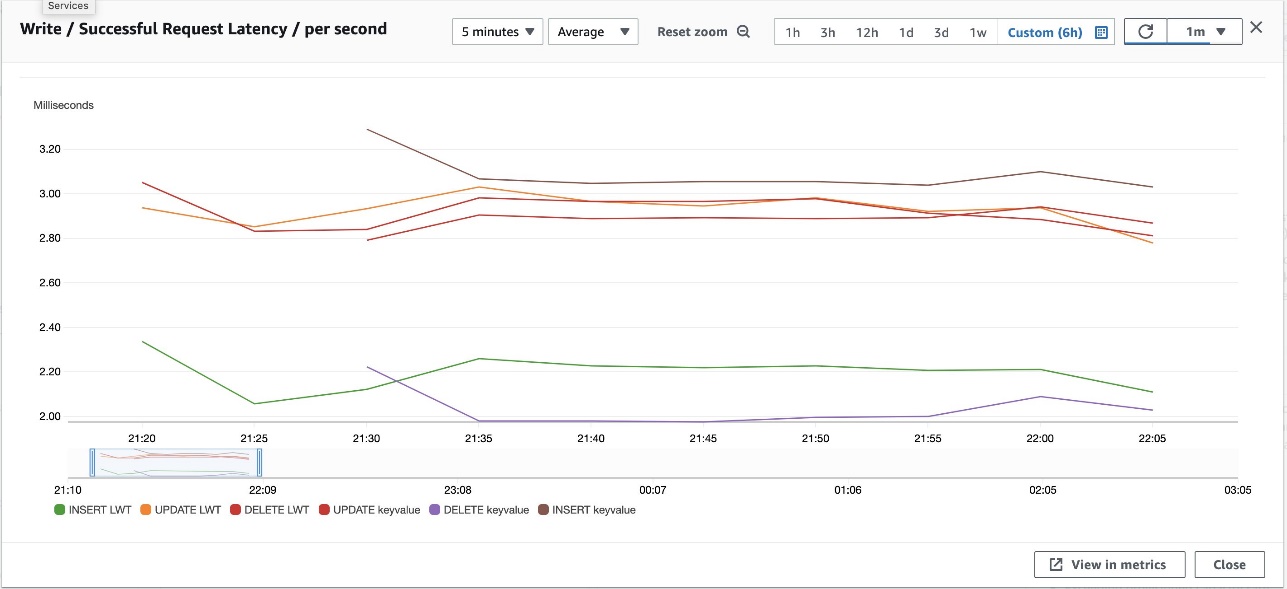
Figure 1 that follows is an Amazon CloudWatch metric showing the results of a workload executing both LWT and non-LWT operations against a table. All requests are within a millisecond variance of each other. In the case where the condition check is false, LWT is actually faster because it avoids the modify operation.
{kind=link}
Figure 1: CloudWatch metric showing LWT and non-LWT operation latencies. Dimensions labeled LWT represent LWT operations and dimensions labeled keyvalue are non-LWT
Set up tables for examples
To run the examples in this post, you must create a keyspace and a table in Amazon Keyspaces. For this post you can use the Amazon Keyspaces CQL console or the cqlsh-expansion library, which extends the existing cqlsh library with additional helpers and best practices for Keyspaces. Use the following command to connect to Keyspaces using the cqlsh-expansion library using the SigV4AuthProvider for short term credentials. This requires setting up the AWS SDK credentials file or environment variables with AWS Identity and Access Management (IAM) assess key, key ID, and AWS Region.
Figure 2 that follows shows a user connecting to Amazon Keyspaces with the cqlsh-expansion library and SigV4AuthProvider that will use AWS credentials.
{kind=link}
Figure 2: A screenshot of a terminal using the cqlsh-expansion python library to connect to Amazon Keyspaces
Start by creating a new keyspace for your model and name it aws_blog. A new keyspace requires you to use a SingleRegionStrategy replication strategy. Amazon Keyspaces replicates data three times across multiple availability zones. Additionally, with Amazon Keyspaces, a keyspace can be assigned AWS resource tags. Efficient tagging provides categorization that enables advanced insights to costs or simplifies managing IAM policies.
After the aws_blog keyspace is ACTIVE, create a new table called account_user_profile. The table is based on a common one-to-many relationship between account and profiles. In this model account_id is the partition key. Each account_id contains multiple rows sorted by a clustering key column profile_id. The combination of partition key and clustering key form the primary key for key value access to a row. The table also includes various data types such as text, int, timestamps, and static columns, which will be used in the examples in this post.
Use the following select statement to query the system tables for ACTIVE status.
Figure 3 that follows shows the output of querying the system table for the status of the table you just created. Once the table has ACTIVE status, it’s ready for reads and writes.
{kind=link}
Checking for existence before insert, update, or delete
Now that you have a keyspace and table created, we use them to learn about using LWTs to insert, update, and delete rows based on existence. In many cases, NoSQL models are designed for idempotent APIs, where a modify request can be retried or repeated without changing the end state. There are cases where non-idempotent modifications are required. This is where LWT can really help simplify design. With LWT, you can use the IF EXISTS or IF NOT EXISTS clause to perform an existence check on modification.
For example, you’re working on a gaming use case to store player profile information in Amazon Keyspaces. There’s a requirement to store the creation_time and modify_time for each profile. One approach is to store the creation_time value only on the initial insert. After the initial insert, you update only the modify_time of the profile. The challenge is determining if the profile exists at the time of insert. Failure to do so could overwrite an existing value of creation_time. You can use LWTs to insert a row only when IF NOT EXISTS is true, to ensure that creation_time is stored at-most once even in the event of retries.
Using the example cql statement below, insert a new player profile with the current time. On first insert, populate both create_time and modify_time with the current time by using the functions toTimestamp() and now(). For cqlsh, you first need to set consistency to LOCAL_QUORUM for strong consistency.
After running the insert you should notice a response indicating the insert was applied. The output, shown in Figure 4 that follows, shows applied is equal to true.
{kind=link}
Running this statement again results in a conditional check failure, as shown in Figure 5 that follows. The value for applied is equal to false and the state of the current row is returned as a result. Since this statement can only succeed once, it’s useful when developers are trying to prevent overwriting data or creating a ledger of immutable rows.
{kind=link}
Update only if a row exists
After you’ve captured the create_time on initial insert, you need to change the modify_time only for existing records. For example, you have a new requirement to persist a stream of profile changes. The stream consists mostly of updates to existing profiles, but there is a 5 percent chance that some events will require creating a new profile. You can use LWT to modify rows only if the row already exists. Using IF EXISTS, you can ensure that modify_time is updated for a row at least once.
In the following example, you can run a LWT using an IF EXISTS clause to update multiple columns of an existing player profile. The following update statement updates the name to John and the modified_time to the current time.
Figure 6 that follows shows the output of a successful update statement. Again, like the insert statement in the previous example, the result is true for the applied field. If false, the row doesn’t exist and there is no additional information to return.
{kind=link}
Cassandra’s default behavior is to treat both INSERT and UPDATE as UPSERT. With LWT, you can effectively change the default behavior of INSERTS and UPDATES to be explicit for the type of modification you desire. With IF NOT EXISTS and IF EXISTS, INSERTS will only insert new rows and UPDATES will only update existing rows.
Implement optimistic locking for a row
A common pattern in NoSQL is to use optimistic locking when modifications require the latest state. For example, you have a new requirement to track the total playing time for a player profile. You receive increments of playing time to be aggregated and stored as the total sum of playing time. To do this you track the total playing time you need to increment the current value and update the profile with the total. Since there can be multiple clients updating the playing_time field, you can implement an optimistic locking pattern with LWT to have better guarantees around updating the latest total.
Start by inserting a new profile with a profile_version of v0 and playing_time of 500 seconds using IF NOT EXISTS to ensure at-most-once delivery. You can then query the profile to select the current values.
Figure 7 that follows shows successful insert of a new row and verification of the results. The results of the select statement are used as inputs to the next steps.
{kind=link}
Figure 7: Terminal window showing the successful output of a LWT and the retrieval of the latest values
Now that you have the first version in place, next you update the playing time by 200. You need to add 200 to the current value of 500 and store it back as an aggregated value of 700. By using a conditional check on the profile_version you can ensure playing_time wasn’t modified before storing the updated version. You also want to increment the profile_version to reflect the change to the profile.
Verify the results by running the SELECT statement. You should receive a profile_version v1 and playing_time of 700.
The output in figure 8 that follows shows a successful update to the profile’s playing time. Verification of results shows the playing time of 700 and the version number has increased to v1.
{kind=link}
As an experiment, repeat the command to see the API result in a check failure. The result will contain the current values for version_number and playing_time. You can now retry the operation with the latest values. The output in Figure 9 that follows shows an example of a conditional check failure response for an update statement.
{kind=link}
Figure 9: Terminal window showing a conditional check failure of a LWT attempting to update a row with a different version number than expected
Implement partition-level optimistic locking using LWT and static columns
In the previous example, LWTs were used to create optimistic locking on a row. You can also perform optimistic locking on a logical partition by using LWTs and static columns. When you declare a column in an Amazon Keyspaces table as static, the cell value of the static column is shared among all rows in a logical partition. By using a static column with LWTs, you can implement a mechanism for versioning partition modifications. This pattern allows applications to perform atomic modification on the current state of a partition.
For example, in the previous example you updated the playing time for an individual profile, but now the requirement is to also aggregate playing time for every profile in a given account. You now have to manage access of multiple writers across multiple rows. By using LWTs and static columns, you can modify the static column cell value and row data atomically while also applying conditions that enable optimistic locking.
Before continuing, it’s important to review the following:
With NoSQL you can still model relationships. The data model in this example demonstrates a one-to-many relationship between an account and profiles. The account is represented by the partition key and static columns. Profiles are represented by the clustering key and the row’s cells.
In the Cassandra API, inserts and updates are upserts. An update will insert a new row if one is not already present as long as you provide the primary key in the where clause.
You can use equality and inequalities =, <, <=, >, >=, and != in your LWT IF statement. You can also check for null and access items in a collection.
Figure 10 that follows is a visual representation of the model of account and profile. Unique accounts are represented by the partition key. Account data is stored in static columns, which can be retrieved by returning any row in the partition. Each unique profile is represented as a row in a partition. Reading any row will also return both profile and account data.
{kind=link}
Figure 10: Visualization of an account user profile table mapped to Cassandra data modeling concepts of partition key, clustering key, rows, and static columns
You can run a select statement for the account_id of unique_account_C. This account and partition shouldn’t exist yet, and will result in 0 rows returned. You can reuse this command throughout this example to verify the current partition state.
Insert a new profile to an account
First, insert a new account and profile. Make sure that neither the partition nor row exists yet. You can do this by performing an LWT with a conditional check on null for profile_version and account_version. The profile_version acts as an optimistic lock for the row and account_version acts as an optimistic lock for the partition. If both are null, then the update will perform an insert. Including a check on profile_version might seem redundant, but it serves as a useful mechanism for returning the current value in case of a conditional check failure.
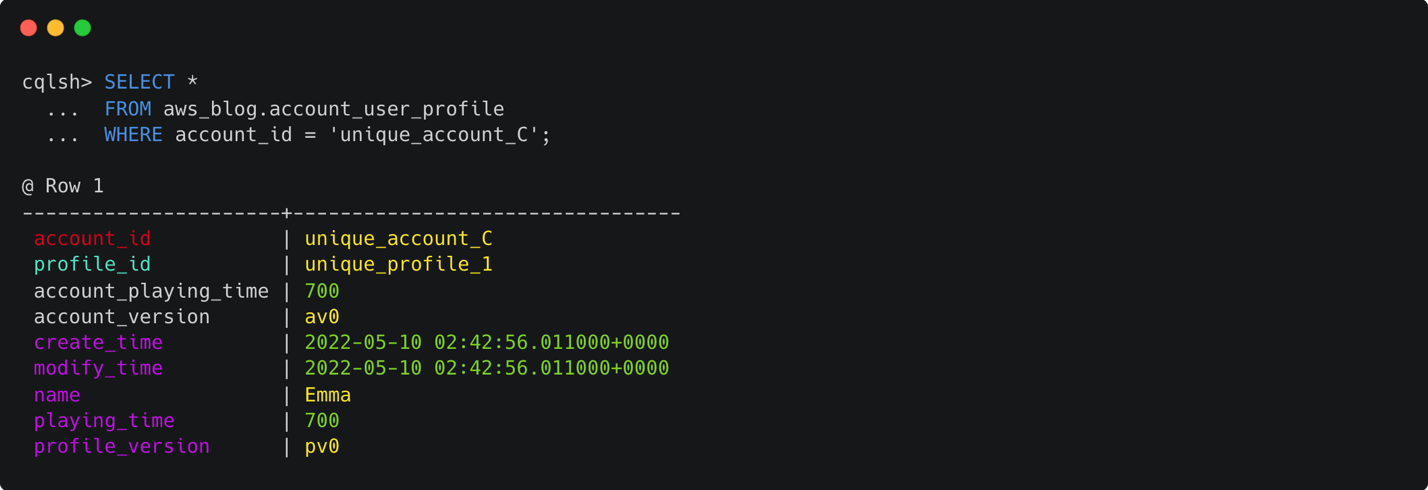
Figure 11 that follows shows the results of the initial insert. You can see that both account_version and profile_version are initialized as version 0 and playing_time and account_playing_time are both equal to 700. The fields create_time and modify_time are omitted in the select statement for readability.
{kind=link}
Figure 11: Terminal window showing the output of a cql select statement retrieving all the rows for a given account_id
Add a second profile to an account
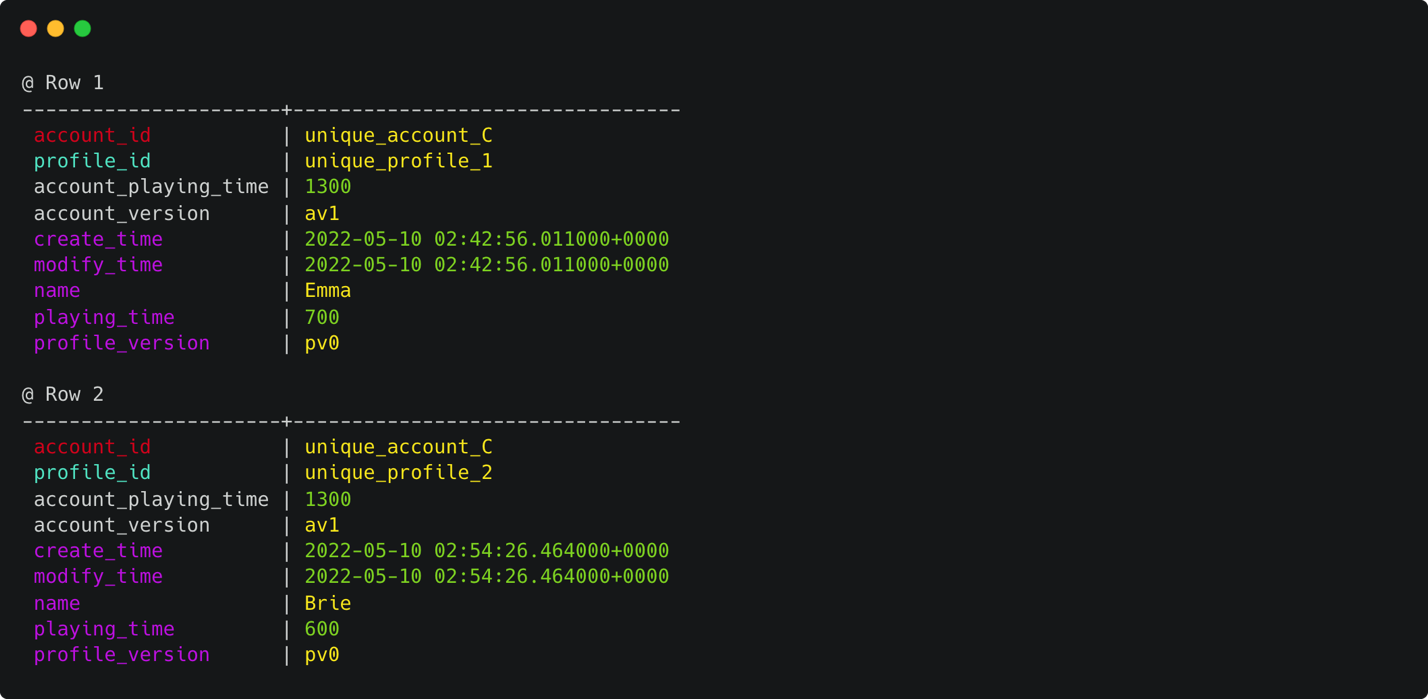
Next, modify the account by adding an additional profile. Similar to the previous step, you can perform this operation by checking the account_version static column and profile_version. The new profile has a playing time of 600, so you need to adjust the account_playing_time for a total of 1300. The following statement makes a conditional check on the account_version, modifies the account_playing_time, and inserts a new row.
Figure 12 that follows shows output that verifies the state after adding an additional profile. You can see that account_version is incremented and profile_version is initialized as version 0. The account_playing_time was updated to 1300 to represent the aggregate of both profiles’ playing_time. Again, the fields create_time and modify_time are omitted in the select statement for readability.
{kind=link}
Figure 12: Terminal window showing the output of a cql select statement retrieving all the rows for a given account_id
Modify an existing profile in an account
Finally, update the account and an existing profile. You update the account and profile only if conditional checks on profile_version and account_version succeed. The following update increments the playing_time and account_playing_time values by 500.
Figure 13 that follows shows output verifying the state after modifying an existing profile. You can see that account_version is incremented again and that profile_version of unique_profile_1 was incremented as well. The account_playing_time was updated to 1800 to represent the new aggregate of both profiles’ playing_time. Again, the fields create_time and modify_time are omitted in the select statement for readability.
{kind=link}
Figure 13: Terminal window showing the output of a cql select statement retrieving all the rows for a given account_id
Monitor conditional check failure requests
When a LWT condition equals false, the transaction is rejected and the service emits an Amazon CloudWatch metric reflecting the number of failed conditional checks. Developers and system administrators can monitor this behavior at scale with CloudWatch. In CloudWatch you will find a metric under AWS/Cassandra called ConditionalCheckFailedRequests.
{kind=link}
Figure 14: Amazon CloudWatch metric displaying the number of ConditionalCheckFailedRequests over an hour period
Estimate capacity utilization
Now that you can monitor LWTs you can better estimate capacity utilization. All writes require LOCAL_QUORUM consistency and there is no additional charge for using LWTs. The difference from non-LWTs, is that when a LWT condition check results in FALSE, it consumes capacity units. The number of write capacity units consumed depends on the size of the row. If the row size is 2 KB, the failed conditional write consumes two write capacity units. If the row doesn’t currently exist in the table, the operation consumes one write capacity unit. By monitoring ConditionalCheckFailedRequests you can determine the capacity consumed by LWT condition check failures.
Clean up Amazon Keyspaces resources
To finish, you can clean up the resources used in this blog by dropping the keyspace aws_blog. The following command will drop all tables in a given keyspace before deleting the keyspace itself. If you enabled PITR when creating the table, you can restore the aws_blog.account_user_profile for the next 35 days.
Conclusion
In this post you learned about the improved performance characteristics of Amazon Keyspaces LWT API, advanced design patterns, and operational best practices. LWTs in Keyspaces have single-digit performance and allow you to mix and match LWT and non-LWT operations without losing isolation barriers. You can use LWTs to implement advanced design patterns such as optimistic locking. You can add CloudWatch to monitor LWTs successful operations, latencies, and conditional check events.
For more information about LWTs and Amazon Keyspaces, check out the Scaling Data video resources on the official Amazon Keyspaces product page. In these videos we cover Amazon Keyspaces use cases, serverless architecture and application modernization.
About the Authors
Michael Raney is a Senior Specialist Solutions Architect based in New York and leads the field for Amazon Keyspaces. He works with customers to modernize their legacy database workloads to a serverless architecture. Michael has spent over a decade building distributed systems for high scale and low latency.
{kind=link}
Read MoreAWS Database Blog