

{kind=link}
In previous blog post, we described an end-to-end identity verification solution in a single AWS Region. The solution uses the Amazon Rekognition APIs DetectFaces for face detection and CompareFaces for face comparison. We think of those APIs as stateless APIs because they don’t depend on an Amazon Rekognition face collection. They’re also idempotent, meaning repeated calls with the same parameters will return the same result. They provide flexible options on passing images, either through an Amazon Simple Storage Service (Amazon S3) location or raw bytes.
In this post, we focus on Amazon Rekognition Image stateless APIs, and discuss two options of passing images and when to choose one over the other from a system architecture point of view. Then we discuss how to scale the stateless APIs to overcome some Regional limitations. When talking about scalability, we often refer to the maximum transactions per second (TPS) the solution can handle. For example, when hosting a large event that uses computer vision to detect faces or object labels, you may encounter a traffic spike, and you don’t want the system to throttle. That means you sometimes need to increase the TPS and even go beyond the Regional service quota Amazon Rekognition APIs have. This post proposes a solution to increase the stateless APIs’ TPS by using multiple Regions.
Amazon Rekognition stateless APIs
Of the Amazon Rekognition Image APIs available, CompareFaces, DetectFaces, DetectLabels, DetectModerationLabels, DetectProtectiveEquipment, DetectText, and RecognizeCelebrities are stateless. They provide both Amazon S3 and raw bytes options to pass images. For example, in the request syntax of the DetectFaces API, there are two options to pass to the Image field: Bytes or S3Object.
When using the S3Object option, a typical architecture is as follows.
{kind=link}
This solution has the following workflow:
The client application accesses a webpage hosted with AWS Amplify.
The client application is authenticated and authorized with Amazon Cognito.
The client application uploads an image to an S3 bucket.
Amazon S3 triggers an AWS Lambda function to call Amazon Rekognition.
The Lambda function calls Amazon Rekognition APIs with the S3Object option.
The Lambda function persists the result to an Amazon DynamoDB table.
Choose the S3Object option in the following scenarios:
The image is either a PNG or JPEG formatted file
You deploy the whole stack in the same Region where Amazon Rekognition is available
The Regional service quota of the Amazon Rekognition API meets your system requirement
When you don’t meet all these requirements, you should choose the Bytes option.
Use Amazon Rekognition Stateless APIs in a different Region
One example of using the Bytes option is when you want to deploy your use case in a Region where Amazon Rekognition is not generally available, for example, if you have customer presence in the South America (sa-east-1) Region. For data residency, the S3 bucket that you use to store users’ images has to be in sa-east-1, but you want to use Amazon Rekognition for your solution even though it’s not generally available in sa-east-1. One solution is to use the Bytes option to call Amazon Rekognition in a different Region where Amazon Rekognition is available, such as us-east-1. The following diagram illustrates this architecture.
{kind=link}
After the Lambda function is triggered (Step 4), instead of calling Amazon Rekognition directly with the image’s S3 location, the function needs to retrieve the image from the S3 bucket (Step 5), then call Amazon Rekognition with the image’s raw bytes (Step 6). The following is a code snippet of the Lambda function:
Note that the preceding code snippet works directly for JPEG or PNG formats. For other image formats, like BMP, extra image processing is needed to convert it to JPEG or PNG bytes before sending to Amazon Rekognition. The following code converts BMP to JPEG bytes:
Scale up stateless APIs’ TPS by spreading API calls into multiple Regions
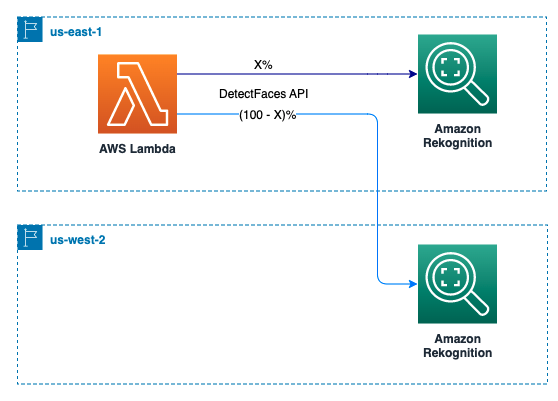
Another use case of the Bytes option is that you can scale up the stateless APIs’ TPS by spreading the API calls into multiple Regions. This way, you’re not limited by the Regional service quota of the API because you can gain additional TPS from other Regions.
In the following example, a Lambda function is created to call the Amazon Rekognition DetectLabels API with the Bytes option. To scale up the maximum TPS, you can spread the API calls into multiple Regions with weights. The maximum TPS you can achieve is calculated with: min(region_1_max_tps/region_1_weight, region_2_max_tps/region_2_weight, … region_n_max_tps/region_n_weight). The following example uses us-east-1 and us-west-2 Regions.
{kind=link}
The code snippet to call the DetectLabels API is as follows:
Because us-east-1 and us-west-2 both have maximum 50 TPS for the Amazon Rekognition DetectFaces API, you can evenly spread the API calls with 50/50 weight by setting the environment variable REGION_1_TRAFFIC_PERCENTAGE to 50. This way, you can achieve min(50/50%, 50/50%) = 100 TPS in theory.
To validate the idea, the Lambda function is exposed as a REST API with Amazon API Gateway. Then JMeter is used to load test the API.
{kind=link}
REGION_1_TRAFFIC_PERCENTAGE is first set to 100, this way all DetectFaces API calls are sent to us-east-1 only. In theory, the maximum TPS that can be achieved is limited by the service quota in us-east-1, which is 50 TPS. Load test on the custom API endpoint, starting with 50 concurrent threads, incrementally adding 5 threads until ProvisionedThroughputExceededException returned from Amazon Rekognition is observed.
REGION_1_TRAFFIC_PERCENTAGE is then set to 50, this way all DetectLabels API calls are evenly sent to us-east-1 and us-west-2. In theory, the maximum TPS that can be achieved is the service quota that the two Regions combine, which is 100 TPS. Start the load test again from 100 threads to find the maximum TPS.
The following table summarizes the results of the load testing.
Percentage of DetectLabels API Calls to us-east-1
Percentage of DetectLabels API Calls to us-west-2
Maximum TPS in Theory
Maximum Concurrent Runs without ProvisionedThroughputExceededException
100
0
50
70
50
50
100
145
Conclusion
Many customers are using Amazon Rekognition Image stateless APIs for various use cases, including identity verification, content moderation, media processing, and more. This post discussed the two options of passing images and how to use the raw bytes option for the following use cases:
Amazon Rekognition Regional availability
Customer data residency
Scaling up Amazon Rekognition stateless APIs’ TPS
Check out how Amazon Rekognition is used in different computer vision use cases and start your innovation journey.
About the Authors
Sharon Li is a solutions architect at AWS, based in the Boston, MA area. She works with enterprise customers, helping them solve difficult problems and build on AWS. Outside of work, she likes to spend time with her family and explore local restaurants.
{kind=link}
Vaibhav Shah is a Senior Solutions Architect with AWS and like to help his customers out with everything cloud and enable their cloud adoption journey. Outside of work, he loves traveling, exploring new places and restaurants, cooking, following sports like cricket and football, watching movies and series (Marvel fan), and adventurous activities like hiking, skydiving, and the list goes on.
{kind=link}
Read MoreAWS Machine Learning Blog