

{kind=link}
This post is co-written with Sowmya Manusani, Sr. Staff Machine Learning Engineer at Zendesk
Zendesk is a SaaS company that builds support, sales, and customer engagement software for everyone, with simplicity as the foundation. It thrives on making over 170,000 companies worldwide serve their hundreds of millions of customers efficiently. The Machine Learning team at Zendcaesk is responsible for enhancing Customer Experience teams to achieve their best. By combining the power of data and people, Zendesk delivers intelligent products that make their customers more productive by automating manual work.
Zendesk has been building ML products since 2015, including Answer Bot, Satisfaction Prediction, Content Cues, Suggested Macros, and many more. In the last few years, with the growth in deep learning, especially in NLP, they saw a lot of opportunity to automate workflows and assist agents in supporting their customers with Zendesk solutions. Zendesk currently use TensorFlow and PyTorch to build deep learning models.
Customers like Zendesk have built successful, high-scale software as a service (SaaS) businesses on Amazon Web Services (AWS). A key driver for a successful SaaS business model is the ability to apply multi-tenancy in the application and infrastructure. This enables cost and operational efficiencies because the application only needs to be built once, but it can be used many times and the infrastructure can be shared. We see many customers build secure, cost-efficient, multi-tenant systems on AWS at all layers of the stack, from compute, storage, database, to networking, and now we’re seeing customers needing to apply it to machine learning (ML).
Making the difficult tradeoff between model reuse and hyper-personalization
Multi-tenancy for SaaS businesses typically means that a single application is reused between many users (SaaS customers). This creates cost efficiencies and lowers operational overhead. However, machine learning models sometimes need to be personalized to a high degree of specificity (hyper-personalized) to make accurate predictions. This means the “build once, use many times” SaaS paradigm can’t always be applied to ML if models have specificity. Take for example the use case of customer support platforms. The language that users include in a support ticket varies depending on if it’s a ride share issue (“ride took too long”) or a clothing purchase issue (“discoloration when washed”). In this use case, improving the accuracy of predicting the best remediation action may require training a natural language processing (NLP) model on a dataset specific to a business domain or an industry vertical. Zendesk face exactly this challenge when trying to leverage ML in their solutions. They needed to create thousands of highly customized ML models, each tailored for a specific customer. To solve this challenge of deploying thousands of models, cost effectively, Zendesk turned to Amazon SageMaker.
In this post, we show how to use some of the newer features of Amazon SageMaker, a fully managed machine learning service, to build a multi-tenant ML inference capability. We also share a real-world example of how Zendesk successfully achieved the same outcome by deploying a happy medium between being able to support hyper-personalization in their ML models and the cost-efficient, shared use of infrastructure using SageMaker multi-model endpoints (MME).
SageMaker multi-model endpoints
SageMaker multi-model endpoints enable you to deploy multiple models behind a single inference endpoint that may contain one or more instances. Each instance is designed to load and serve multiple models up to its memory and CPU capacity. With this architecture, a SaaS business can break the linearly increasing cost of hosting multiple models and achieve reuse of infrastructure consistent with the multi-tenancy model applied elsewhere in the application stack.
The following diagram illustrates the architecture of a SageMaker multi-model endpoint.
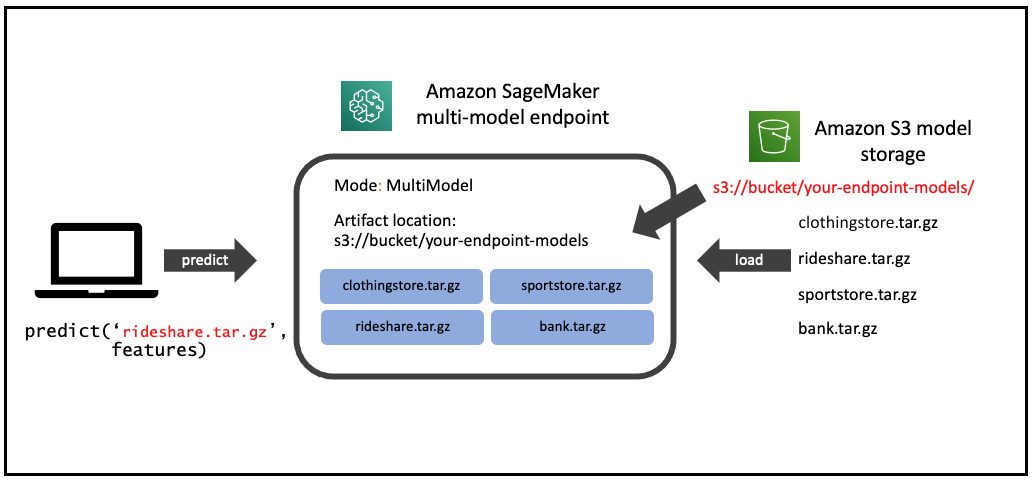{kind=link}
The SageMaker multi-model endpoint dynamically loads models from Amazon Simple Storage Service (Amazon S3) when invoked, instead of downloading all the models when the endpoint is first created. As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. If the model is already loaded on the container when invoked, then the download step is skipped and the model returns the inferences with low latency. For example, assume you have a model that is only used a few times a day. It is automatically loaded on demand, while frequently accessed models are retained in memory and invoked with consistently low latency.
Let’s take a closer look at how Zendesk used SageMaker MME to achieve cost-effective, hyper-scale ML deployment with their Suggested Macros ML feature.
Why Zendesk built hyper-personalized models
Zendesk’s customers are spread globally in different industry verticals with different support ticket semantics. Therefore, to serve their customers best, they often have to build personalized models that are trained on customer-specific support ticket data to correctly identify intent, macros, and more.
In October 2021, they released a new NLP ML feature, Suggested Macros, which recommends macros (predefined actions) based on thousands of customer-specific model predictions. Zendesk’s ML team built a TensorFlow-based NLP classifier model trained from the previous history of ticket content and macros per customer. With these models available, a macro prediction is recommended whenever an agent views the ticket (as shown in the following screenshot), which assists the agent in serving customers quickly. Because macros are specific to customers, Zendesk needs customer-specific models to serve accurate predictions.
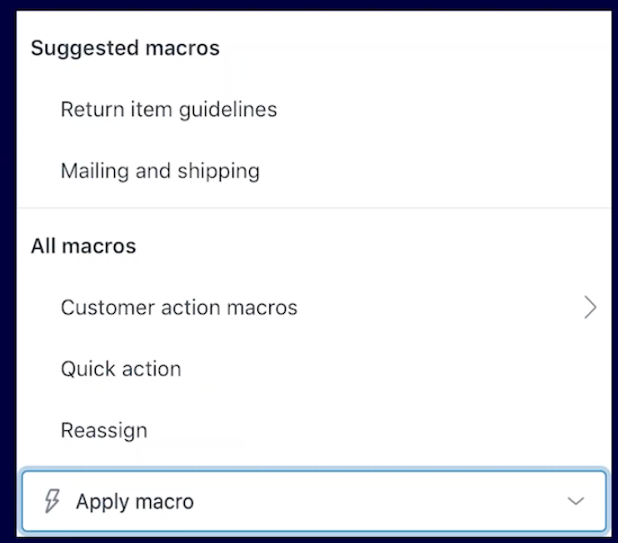{kind=link}
Under the hood of Zendesk’s Suggested Macros
Suggested Macros models are NLP-based neural nets that are around 7–15 MB in size. The main challenge is to put thousands of these models in production with cost-efficient, reliable, and scalable solutions.
Each model has different traffic patterns, with a minimum of two requests per second and a peak of hundreds of requests per second, serving millions of predictions per day with a model latency of approximately 100 milliseconds when the model is available in memory. SageMaker endpoints are deployed in multiple AWS Regions, serving thousands of requests per minute per endpoint.
With its ability to host multiple models on a single endpoint, SageMaker helped Zendesk reduce deployment overhead and create a cost-effective solution when compared to deploying a single-model endpoint per customer. The tradeoff here is less control on per-model management; however, this is an area where Zendesk is collaborating with AWS to improve multi-model endpoints.
One of the SageMaker multi-model features is lazy loading of models, that is, models are loaded into memory when invoked for the first time. This is to optimize memory utilization; however, it causes response time spikes on first load, which can be seen as a cold start problem. For Suggested Macros, this was a challenge; however, Zendesk overcame this by implementing a preloading functionality on top of the SageMaker endpoint provisioning to load the models into memory before serving production traffic. Secondly, MME unloads infrequently used models from memory, so to achieve consistent low latency on all the models and avoid “noisy neighbors” impacting other less active models, Zendesk is collaborating with AWS to add new features, discussed later in the post, to enable more explicit per-model management. Additionally, as an interim solution, Zendesk has right-sized the MME fleet to minimize too many models unloading. With this, Zendesk is able to serve predictions to all their customers with low latency, around 100 milliseconds, and still achieve 90% cost savings when compared to dedicated endpoints.
On right-sizing MME, Zendesk observed during load testing that having a higher number of smaller instances (bias on horizontal scaling) behind MME was a better choice than having fewer larger memory instances (vertical scaling). Zendesk observed that bin packing too many models (beyond 500 TensorFlow models in their case) on a single large memory instance didn’t work well because memory is not the only resource on an instance that can be a bottleneck. More specifically, they observed that TensorFlow spawned multiple threads (3 x total instance vCPUs) per model, so loading over 500 models on a single instance caused kernel level limits to be breached on the max number of threads that could be spawned on an instance. Another issue with using fewer, larger instances occurred when Zendesk experienced throttling (as a safety mechanism) on some instances behind MME because the unique model invocation per second rate exceeded what the Multi Model Server (MMS) on a single instance could safely handle without browning out the instance. This was another issue that was resolved with the use of more and smaller instances.
From the observability perspective, which is a crucial component of any production application, Amazon CloudWatch metrics like invocations, CPU, memory utilization, and multi model-specific metrics like loaded models in memory, model loading time, model load wait time, and model cache hit are informative. Specifically, the breakdown of model latency helped Zendesk understand the cold start problem and its impact.
Under the hood of MME auto scaling
Behind each multi-model endpoint, there are model hosting instances, as depicted in the following diagram. These instances load and evict multiple models to and from memory based on the traffic patterns to the models.
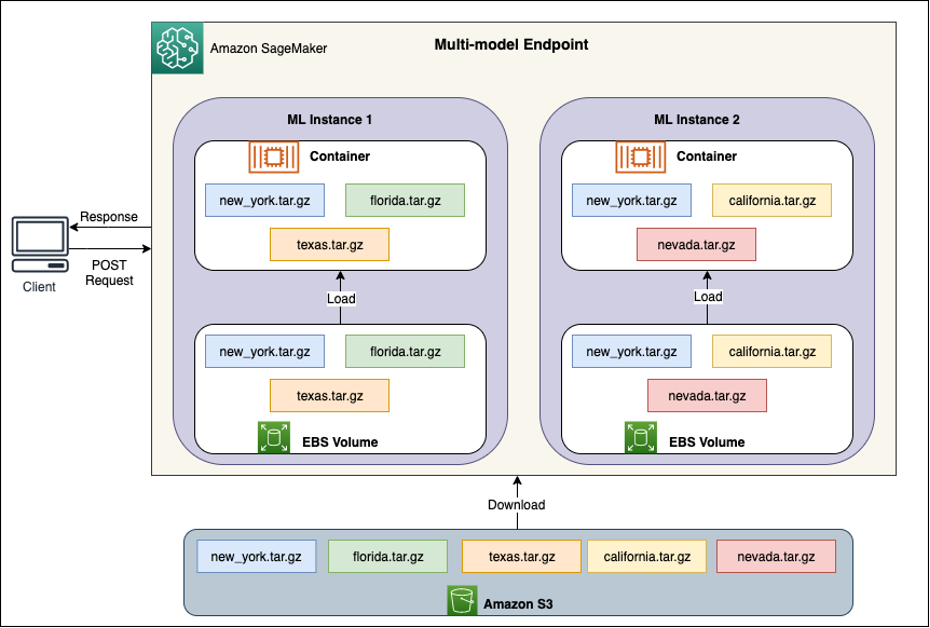{kind=link}
SageMaker continues to route inference requests for a model to the instance where the model is already loaded such that the requests are served from cached model copy (see the following diagram, which shows the request path for the first prediction request vs. the cached prediction request path). However, if the model receives many invocation requests, and there are additional instances for the multi-model endpoint, SageMaker routes some requests to another instance to accommodate the increase. To take advantage of automated model scaling in SageMaker, make sure you have instance auto scaling set up to provision additional instance capacity. Set up your endpoint-level scaling policy with either custom parameters or invocations per minute (recommended) to add more instances to the endpoint fleet.
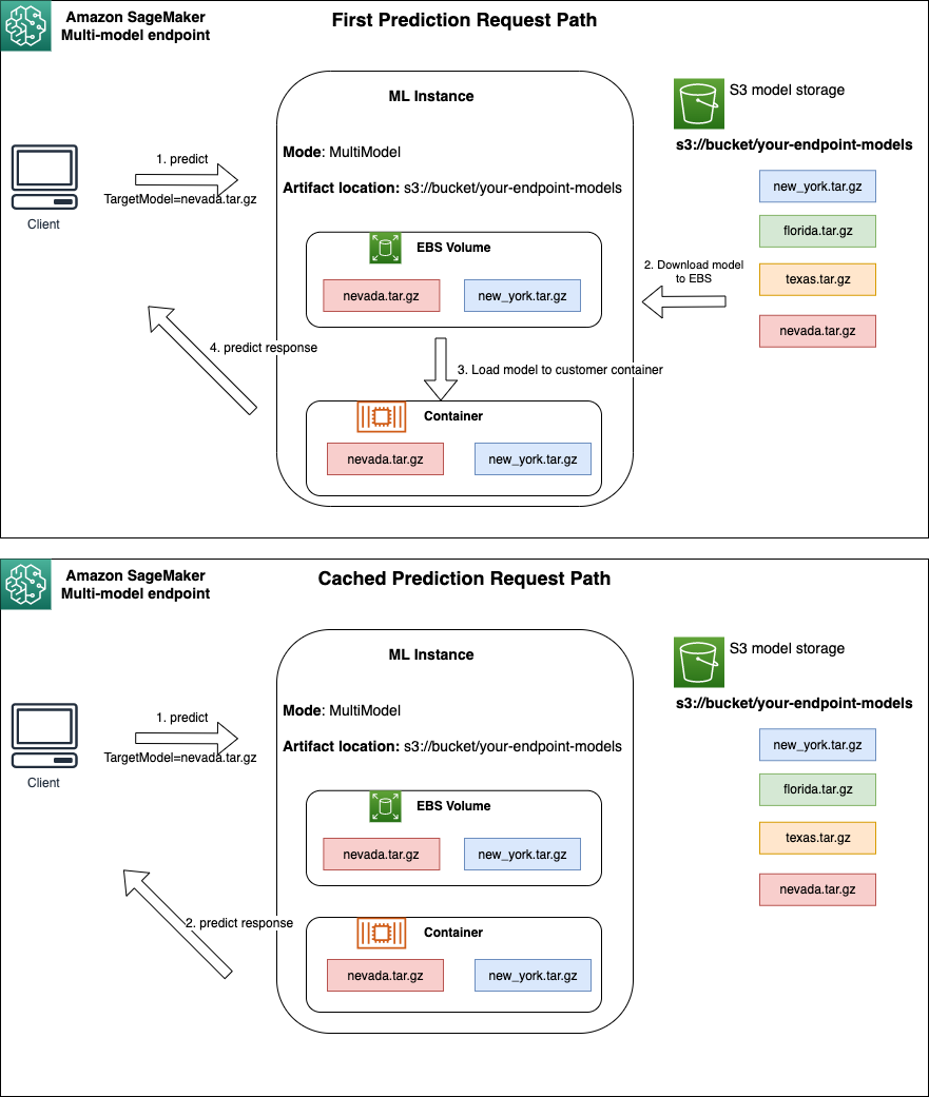{kind=link}
Use cases best suited for MME
SageMaker multi-model endpoints are well suited for hosting a large number of similar models that you can serve through a shared serving container and don’t need to access all the models at the same time. MME is best suited for models that are similar in size and invocation latencies. Some variation in model size is acceptable; for example, Zendesk’s models range from 10–50 Mb, which works fine, but variations in size that are a factor of 10, 50, or 100 times greater aren’t suitable. Larger models may cause a higher number of loads and unloads of smaller models to accommodate sufficient memory space, which can result in added latency on the endpoint. Differences in performance characteristics of larger models could also consume resources like CPU unevenly, which could impact other models on the instance.
MME is also designed for co-hosting models that use the same ML framework because they use the shared container to load multiple models. Therefore, if you have a mix of ML frameworks in your model fleet (such as PyTorch and TensorFlow), SageMaker dedicated endpoints or multi-container hosting is a better choice. Finally, MME is suited for applications that can tolerate an occasional cold start latency penalty because infrequently used models can be off-loaded in favor of frequently invoked models. If you have a long tail of infrequently accessed models, a multi-model endpoint can efficiently serve this traffic and enable significant cost savings.
Summary
In this post, you learned how SaaS and multi-tenancy relate to ML and how SageMaker multi-model endpoints enable multi-tenancy and cost-efficiency for ML inference. You learned about Zendesk’s multi-tenanted use case of per-customer ML models and how they hosted thousands of ML models in SageMaker MME for their Suggested Macros feature and achieved 90% cost savings on inference when compared to dedicated endpoints. Hyper-personalization use cases can require thousands of ML models, and MME is a cost-effective choice for this use case. We will continue to make enhancements in MME to enable you to host models with low latency and with more granular controls for each personalized model. To get started with MME, see Host multiple models in one container behind one endpoint.
About the Authors
Syed Jaffry is a Sr. Solutions Architect with AWS. He works with a range of companies from mid-sized organizations to large enterprises, financial services to ISVs, in helping them build and operate secure, resilient, scalable, and high performance applications in the cloud.
{kind=link}
Sowmya Manusani is a Senior Staff Machine Learning Engineer at Zendesk. She works on productionalizing NLP-based Machine Learning features that focus on improving Agent productivity for thousands of Zendesk Enterprise customers. She has experience with building automated training pipelines for thousands of personalized models and serving them using secure, resilient, scalable, and high-performance applications. In her free time, she likes to solve puzzles and try painting.
{kind=link}
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and making machine learning more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch and spending time with his family.
{kind=link}
Deepti Ragha is a Software Development Engineer in the Amazon SageMaker team. Her current work focuses on building features to host machine.
{kind=link}
Read MoreAWS Machine Learning Blog