

{kind=link}
This post is co-written by Ramdev Wudali and Kiran Mantripragada from Thomson Reuters.
In 1992, Thomson Reuters (TR) released its first AI legal research service, WIN (Westlaw Is Natural), an innovation at the time, as most search engines only supported Boolean terms and connectors. Since then, TR has achieved many more milestones as its AI products and services are continuously growing in number and variety, supporting legal, tax, accounting, compliance, and news service professionals worldwide, with billions of machine learning (ML) insights generated every year.
With this tremendous increase of AI services, the next milestone for TR was to streamline innovation, and facilitate collaboration. Standardize building and reuse of AI solutions across business functions and AI practitioners’ personas, while ensuring adherence to enterprise best practices:
Automate and standardize the repetitive undifferentiated engineering effort
Ensure the required isolation and control of sensitive data according to common governance standards
Provide easy access to scalable computing resources
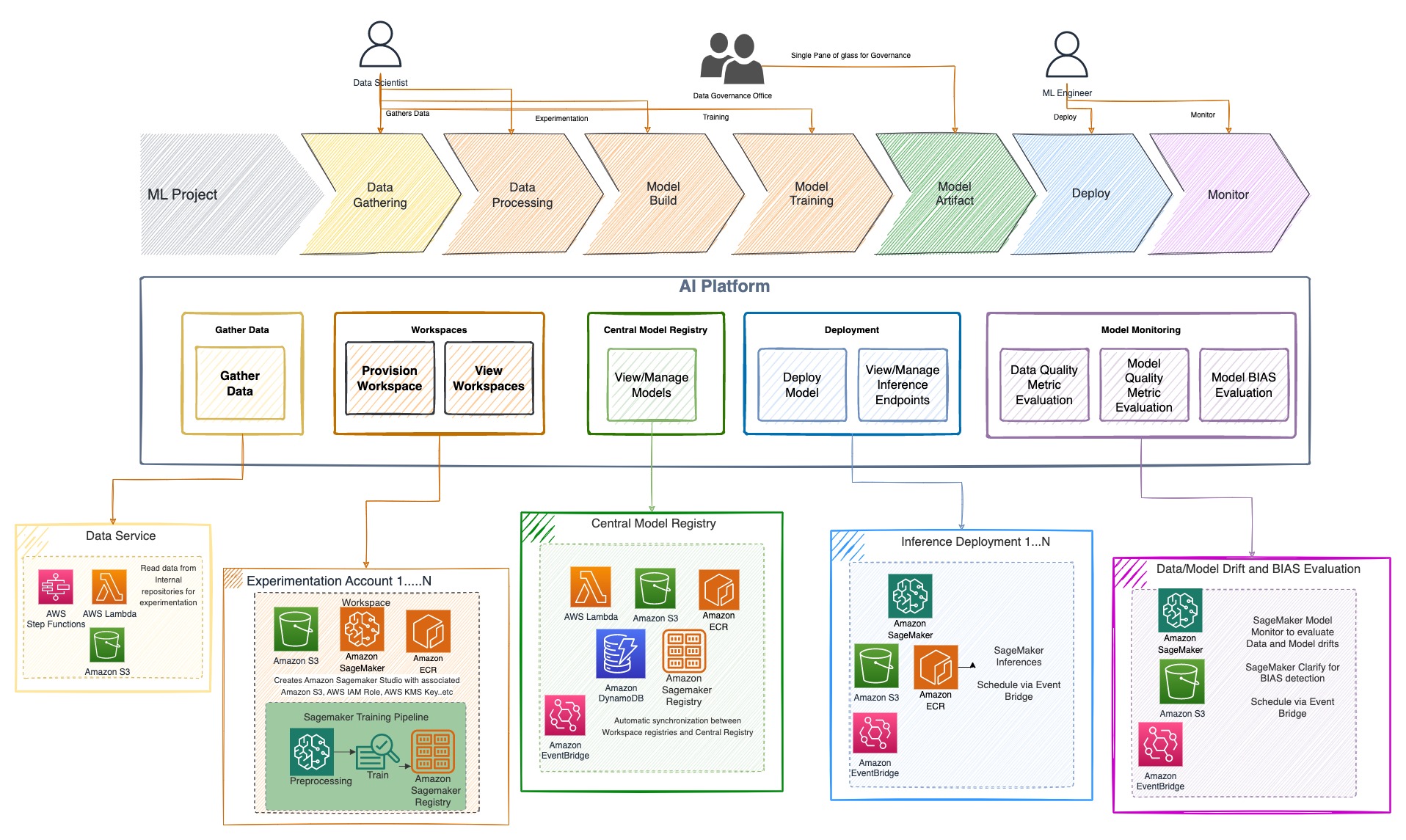
To fulfill these requirements, TR built the Enterprise AI platform around the following five pillars: a data service, experimentation workspace, central model registry, model deployment service, and model monitoring.
In this post, we discuss how TR and AWS collaborated to develop TR’s first ever Enterprise AI Platform, a web-based tool that would provide capabilities ranging from ML experimentation, training, a central model registry, model deployment, and model monitoring. All these capabilities are built to address TR’s ever-evolving security standards and provide simple, secure, and compliant services to end-users. We also share how TR enabled monitoring and governance for ML models created across different business units with a single pane of glass.
The challenges
Historically at TR, ML has been a capability for teams with advanced data scientists and engineers. Teams with highly skilled resources were able to implement complex ML processes as per their needs, but quickly became very siloed. Siloed approaches didn’t provide any visibility to provide governance into extremely critical decision-making predictions.
TR business teams have vast domain knowledge; however, the technical skills and heavy engineering effort required in ML makes it difficult to use their deep expertise to solve business problems with the power of ML. TR wants to democratize the skills, making it accessible to more people within the organization.
Different teams in TR follow their own practices and methodologies. TR wants to build the capabilities that span across the ML lifecycle to their users to accelerate the delivery of ML projects by enabling teams to focus on business goals and not on the repetitive undifferentiated engineering effort.
Additionally, regulations around data and ethical AI continue to evolve, mandating for common governance standards across TR’s AI solutions.
Solution overview
TR’s Enterprise AI Platform was envisioned to provide simple and standardized services to different personas, offering capabilities for every stage of the ML lifecycle. TR has identified five major categories that modularize all TR’s requirements:
Data service – To enable easy and secured access to enterprise data assets
Experimentation workspace – To provide capabilities to experiment and train ML models
Central model registry – An enterprise catalog for models built across different business units
Model deployment service – To provide various inference deployment options following TR’s enterprise CI/CD practices
Model monitoring services – To provide capabilities to monitor data and model bias and drifts
As shown in the following diagram, these microservices are built with a few key principles in mind:
Remove the undifferentiated engineering effort from users
Provide the required capabilities at the click of a button
Secure and govern all capabilities as per TR’s enterprise standards
Bring a single pane of glass for ML activities
{kind=link}
TR’s AI Platform microservices are built with Amazon SageMaker as the core engine, AWS serverless components for workflows, and AWS DevOps services for CI/CD practices. SageMaker Studio is used for experimentation and training, and the SageMaker model registry is used to register models. The central model registry is comprised of both the SageMaker model registry and an Amazon DynamoDB table. SageMaker hosting services are used to deploy models, while SageMaker Model Monitor and SageMaker Clarify are used to monitor models for drift, bias, custom metric calculators, and explainability.
The following sections describe these services in detail.
Data service
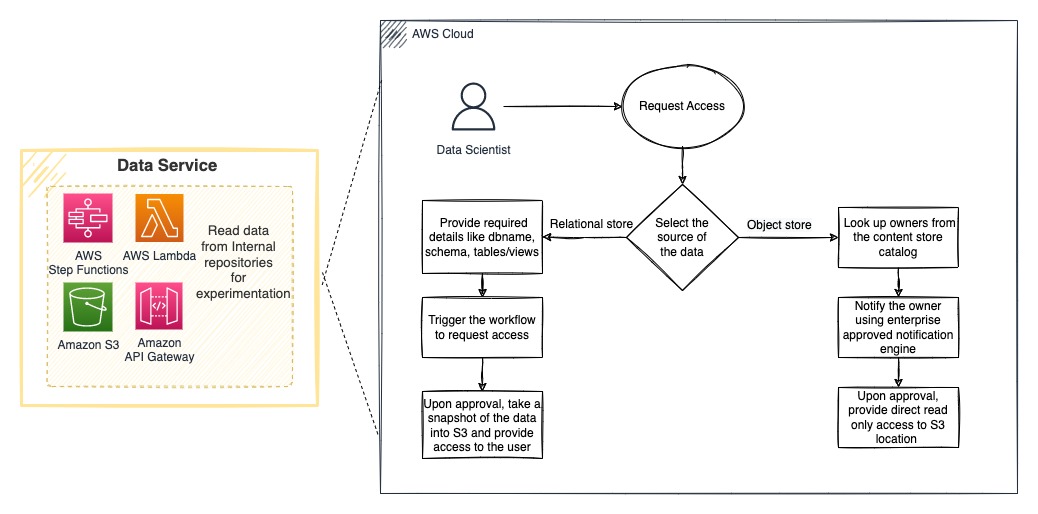
A traditional ML project lifecycle starts with finding data. In general, data scientists spend 60% or more of their time to find the right data when they need it. Just like every organization, TR has multiple data stores that serve as a single point of truth for different data domains. TR identified two key enterprise data stores that provide data for most of their ML use cases: an object store and a relational data store. TR built an AI Platform data service to seamlessly provide access to both data stores from users’ experimentation workspaces and remove the burden from users to navigate complex processes to acquire data on their own. The TR’s AI Platform follows all the compliances and best practices defined by Data and Model Governance team. This includes a mandatory Data Impact Assessment that helps ML practitioners to understand and follow the ethical and appropriate use of data, with formal approval processes to ensure appropriate access to the data. Core to this service, as well as all platform services, is the security and compliance according to the best practices determined by TR and the industry.
Amazon Simple Storage Service (Amazon S3) object storage acts as a content data lake. TR built processes to securely access data from the content data lake to users’ experimentation workspaces while maintaining required authorization and auditability. Snowflake is used as the enterprise relational primary data store. Upon user request and based on the approval from the data owner, the AI Platform data service provides a snapshot of the data to the user readily available into their experimentation workspace.
Accessing data from various sources is a technical problem that can be easily solved. But the complexity TR has solved is to build approval workflows that automate identifying the data owner, sending an access request, making sure the data owner is notified that they have a pending access request, and based on the approval status take action to provide data to the requester. All the events throughout this process are tracked and logged for auditability and compliance.
As shown in the following diagram, TR uses AWS Step Functions to orchestrate the workflow and AWS Lambda to run the functionality. Amazon API Gateway is used to expose the functionality with an API endpoint to be consumed from their web portal.
{kind=link}
Model experimentation and development
An essential capability for standardizing the ML lifecycle is an environment that allows data scientists to experiment with different ML frameworks and data sizes. Enabling such a secure, compliant environment in the cloud within minutes relieves data scientists from the burden of handling cloud infrastructure, networking requirements, and security standards measures, to focus instead on the data science problem.
TR builds an experimentation workspace that offers access to services such as AWS Glue, Amazon EMR, and SageMaker Studio to enable data processing and ML capabilities adhering to enterprise cloud security standards and required account isolation for every business unit. TR has encountered the following challenges while implementing the solution:
Orchestration early on wasn’t fully automated and involved several manual steps. Tracking down where problems were occurring wasn’t easy. TR overcame this error by orchestrating the workflows using Step Functions. With the use of Step Functions, building complex workflows, managing states, and error handling became much easier.
Proper AWS Identity and Access Management (IAM) role definition for the experimentation workspace was hard to define. To comply with TR’s internal security standards and least privilege model, originally, the workspace role was defined with inline policies. Consequentially, the inline policy grew with time and became verbose, exceeding the policy size limit allowed for the IAM role. To mitigate this, TR switched to using more customer-managed policies and referencing them in the workspace role definition.
TR occasionally reached the default resource limits applied at the AWS account level. This caused occasional failures of launching SageMaker jobs (for example, training jobs) due to the desired resource type limit reached. TR worked closely with the SageMaker service team on this issue. This problem was solved after the AWS team launched SageMaker as a supported service in Service Quotas in June 2022.
Today, data scientists at TR can launch an ML project by creating an independent workspace and adding required team members to collaborate. Unlimited scale offered by SageMaker is at their fingertips by providing them custom kernel images with varied sizes. SageMaker Studio quickly became a crucial component in TR’s AI Platform and has changed user behavior from using constrained desktop applications to scalable and ephemeral purpose-built engines. The following diagram illustrates this architecture.
{kind=link}
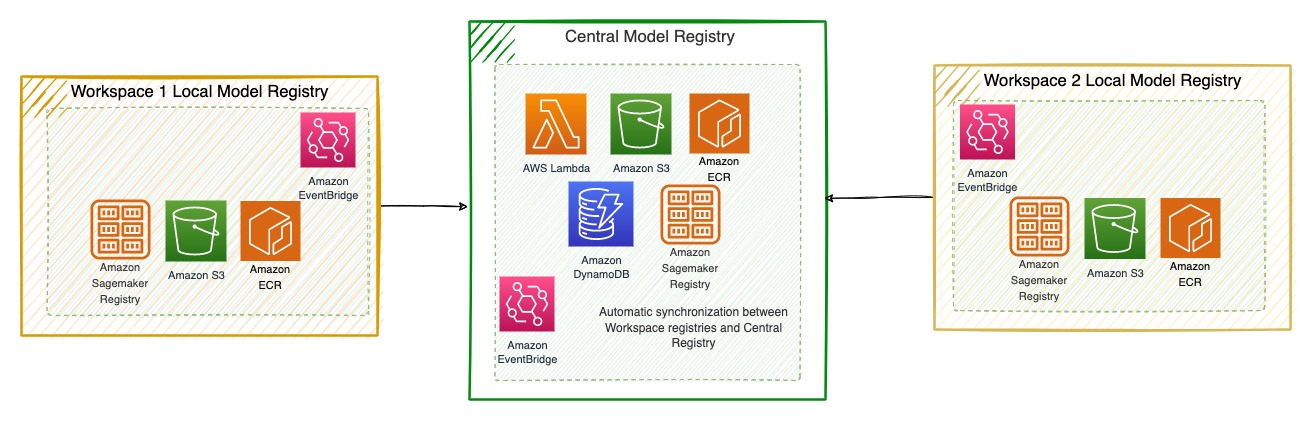
Central model registry
The model registry provides a central repository for all of TR’s machine learning models, enables risk and health management of those in a standardized manner across business functions, and streamlines potential models’ reuse. Therefore, the service needed to do the following:
Provide the capability to register both new and legacy models, whether developed within or outside SageMaker
Implement governance workflows, enabling data scientists, developers, and stakeholders to view and collectively manage the lifecycle of models
Increase transparency and collaboration by creating a centralized view of all models across TR alongside metadata and health metrics
TR started the design with just the SageMaker model registry, but one of TR’s key requirements is to provide the capability to register models created outside of SageMaker. TR evaluated different relational databases but ended up choosing DynamoDB because the metadata schema for models coming from legacy sources will be very different. TR also didn’t want to impose any additional work on the users, so they implemented a seamless automatic synchronization between the AI Platform workspace SageMaker registries to the central SageMaker registry using Amazon EventBridge rules and required IAM roles. TR enhanced the central registry with DynamoDB to extend the capabilities to register legacy models that were created on users’ desktops.
TR’s AI Platform central model registry is integrated into the AI Platform portal and provides a visual interface to search models, update model metadata, and understand model baseline metrics and periodic custom monitoring metrics. The following diagram illustrates this architecture.
{kind=link}
Model deployment
TR identified two major patterns to automate deployment:
Models developed using SageMaker through SageMaker batch transform jobs to get inferences on a preferred schedule
Models developed outside SageMaker on local desktops using open-source libraries, through the bring your own container approach using SageMaker processing jobs to run custom inference code, as an efficient way to migrate those models without refactoring the code
With the AI Platform deployment service, TR users (data scientists and ML engineers) can identify a model from the catalog and deploy an inference job into their chosen AWS account by providing the required parameters through a UI-driven workflow.
TR automated this deployment using AWS DevOps services like AWS CodePipeline and AWS CodeBuild. TR uses Step Functions to orchestrate the workflow of reading and preprocessing data to creating SageMaker inference jobs. TR deploys the required components as code using AWS CloudFormation templates. The following diagram illustrates this architecture.
{kind=link}
Model monitoring
The ML lifecycle is not complete without being able to monitor models. TR’s enterprise governance team also mandates and encourages business teams to monitor their model performance over time to address any regulatory challenges. TR started with monitoring models and data for drift. TR used SageMaker Model Monitor to provide a data baseline and inference ground truth to periodically monitor how TR’s data and inferences are drifting. Along with SageMaker model monitoring metrics, TR enhanced the monitoring capability by developing custom metrics specific to their models. This will help TR’s data scientists understand when to retrain their model.
Along with drift monitoring, TR also wants to understand bias in the models. The out-of-the-box capabilities of SageMaker Clarify are used to build TR’s bias service. TR monitors both data and model bias and makes those metrics available for their users through the AI Platform portal.
To help all teams to adopt these enterprise standards, TR has made these services independent and readily available via the AI Platform portal. TR’s business teams can go into the portal and deploy a model monitoring job or bias monitoring job on their own and run them on their preferred schedule. They’re notified on the status of the job and the metrics for every run.
TR used AWS services for CI/CD deployment, workflow orchestration, serverless frameworks, and API endpoints to build microservices that can be triggered independently, as shown in the following architecture.
{kind=link}
Results and future improvements
TR’s AI Platform went live in Q3 2022 with all five major components: a data service, experimentation workspace, central model registry, model deployment, and model monitoring. TR conducted internal training sessions for its business units to onboard the platform and offered them self-guided training videos.
The AI Platform has provided capabilities to TR’s teams that never existed before; it has opened a wide range of possibilities for TR’s enterprise governance team to enhance compliance standards and centralize the registry, providing a single pane of glass view across all ML models within TR.
TR acknowledges that no product is at its best on initial release. All TR’s components are at different levels of maturity, and TR’s Enterprise AI Platform team is in a continuous enhancement phase to iteratively improve product features. TR’s current advancement pipeline includes adding additional SageMaker inference options like real-time, asynchronous, and multi-model endpoints. TR is also planning to add model explainability as a feature to its model monitoring service. TR plans to use the explainability capabilities of SageMaker Clarify to develop its internal explainability service.
Conclusion
TR can now process vast amounts of data securely and use advanced AWS capabilities to take an ML project from ideation to production in the span of weeks, compared to the months it took before. With the out-of-the-box capabilities of AWS services, teams within TR can register and monitor ML models for the first time ever, achieving compliance with their evolving model governance standards. TR empowered data scientists and product teams to effectively unleash their creativity to solve most complex problems.
To know more about TR’s Enterprise AI Platform on AWS, check out the AWS re:Invent 2022 session. If you’d like to learn how TR accelerated the use of machine learning using the AWS Data Lab program, refer to the case study.
About the Authors
Ramdev Wudali is a Data Architect, helping architect and build the AI/ML Platform to enable data scientists and researchers to develop machine learning solutions by focusing on the data science and not on the infrastructure needs. In his spare time, he loves to fold paper to create origami tessellations, and wearing irreverent T-shirts.
Kiran Mantripragada is the Senior Director of AI Platform at Thomson Reuters. The AI Platform team is responsible for enabling production-grade AI software applications and enabling the work of data scientists and machine learning researchers. With a passion for science, AI, and engineering, Kiran likes to bridge the gap between research and productization to bring the real innovation of AI to the final consumers.
Bhavana Chirumamilla is a Sr. Resident Architect at AWS. She is passionate about data and ML operations, and brings lots of enthusiasm to help enterprises build data and ML strategies. In her spare time, she enjoys time with her family traveling, hiking, gardening, and watching documentaries.
Srinivasa Shaik is a Solutions Architect at AWS based in Boston. He helps enterprise customers accelerate their journey to the cloud. He is passionate about containers and machine learning technologies. In his spare time, he enjoys spending time with his family, cooking, and traveling.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his PhD in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently, he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Read MoreAWS Machine Learning Blog