

{kind=link}
This is a guest post by Imperva, a solutions provider for cybersecurity.
Imperva is a cybersecurity leader, headquartered in California, USA, whose mission is to protect data and all paths to it. In the last few years, we’ve been working on integrating machine learning (ML) into our products. This includes detecting malicious activities in databases, automatically configuring security policies, and clustering security events into meaningful stories.
As we’re pushing to advance our detection capabilities, we’re investing in ML models for our solutions. For example, Imperva provides an API Security service. This service aims to protect all APIs from various attacks, including attacks that traditional WAF can’t easily stop, such as those described in the OWASP top 10. This is a significant investment area for us, so we took steps to expedite our ML development process in order to cover more ground, efficiently research API attacks, and expedite our ability to deliver value for our customers.
In this post, we share how we expedited ML development and collaboration via Amazon SageMaker notebooks.
Jupyter Notebooks: The common research ground
Data science research processes raised the attention of big tech companies and the development community to new heights. It’s now easier than ever to kick off a data-driven project using managed ML services. A great example for this is the rise of citizen data scientists, which according to Gartner are “‘power users who can perform both simple and moderately sophisticated analytical tasks that would previously have required more expertise.”
With the expected growth of ML users, sharing experiments across teams becomes a critical parameter in the development velocity. Among the many common steps, one of the most important steps for data scientists kicking off a project would be to open up a new Jupyter notebook and dive into the challenge ahead.
Jupyter notebooks are a cross between an IDE and a document. It provides the researcher with an easy and interactive way to test different approaches, plot the results, present and export them, while using a language and interface of their choice such as Python, R, Spark, Bash, or others.
Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy ML. SageMaker includes this exact capability and more as part of its SageMaker notebooks feature.
Anyone who has tried to use Jupyter Notebooks in a team has probably reached a point where they attempted to use a notebook belonging to someone else, only to find out it’s not as easy as it sounds. Often, you just don’t have access to the required notebook. On other occasions, notebooks are used locally for research, and so the code is often littered with hardcoded paths and isn’t committed to any repository. Even if the code is committed to a repository of some sorts, (hopefully) the data it requires isn’t committed. To sum things up, it ain’t easy to collaborate with Jupyter Notebooks.
In this post, we show you how we share data science research code at Imperva, and how we use SageMaker notebooks with additional features we’ve added to support our custom requirements and enhance collaboration. We also share how all these efforts have led to a significant reduction in costs and time spent on housekeeping. Although this architecture is a good fit for us, you can choose different configurations, such as complete resource isolation with a separate file system for each user.
How we expedited our ML development
Our workflow is pretty standard, we take a subset of data, load it into a Jupyter notebook, and start exploring the data. After we have a decent understanding of the data, we start experimenting and combining different algorithms until we come up with a decent initial solution. When we have a good enough proof of concept (POC), we proceed to validate the results over time, experimenting and adjusting the algorithm as we go. Eventually, when we reach a high level of confidence, we deliver the model and continue to validate the results.
{kind=link}
At first this process made perfect sense. We had small projects that didn’t require much computing power, and we had enough time to work on them solo until we reached a POC. The projects were simple enough for us to deploy, serve, and monitor the model ourselves, or in other cases, deliver the model as a Docker container. When performance and scale were important, we would pass ownership of the model to a dev team using a specification document with pseudo-code. But times are changing, and as the team and projects grew and developed, we needed a better way to do things. We had to scale our projects when massive computing resources were required, and find a better way to pass ownership without using dull and extensive specification documents.
Furthermore, when everyone is using some remote virtual machine or Amazon Elastic Compute Cloud (Amazon EC2) instance to run their Jupyter notebooks, their projects tend to lack documentation and get messy.
SageMaker notebooks
In comes SageMaker notebooks: a managed Jupyter Notebooks platform hosted on AWS, where you can easily create a notebook instance—an EC2 (virtual computer) instance that runs a Jupyter Notebooks server. Besides the notebook now being in the cloud and accessible from everywhere, you can easily rescale the notebook instance, giving it as much computing resources as you require.
Having unlimited computing resources is great, but it wasn’t why we decided to start using SageMaker notebooks. We can summarize the objectives we wanted to achieve into three main points:
Making research easier – Creating an easy, user-friendly work environment that can be quickly accessed and shared within the research team.
Organizing data and code – Cutting the mess by making it easier to access data and creating a structured way to keep code.
Delivering projects – Creating a better way to separate research playground and production, and finding a better way to share our ideas with development teams without using extensive, dull documents.
Easier research
SageMaker notebooks reside in the cloud, making it inherently accessible from almost anywhere. Starting a Jupyter notebook takes just a few minutes and all your output from the previous run is saved, making it very simple to jump right back into it. However, our research requirements included a few additional aspects that needed a solution:
Quick views – Having the notebooks available at all times in order to review results of previous runs. If the instance where you keep your code is down, you have to start it just to look at the output. This can be frustrating, especially if you’re using an expensive instance and you just want to look at your results. This cut down the time each team member had to spend waiting for the instance to start from 5–15 minutes to 0.
Shared views – Having the ability to explore cross-instance notebooks. SageMaker notebook instances are provided with dedicated storage by default. We wanted to break this wall and enable the team to work together.
Persistent libraries – Libraries are stored temporarily in SageMaker notebook instances. We wanted to change that to cut down the time it takes to fully install all the required libraries and shorten it by 100%, from approximately 5 minutes down to 0.
Cost-effective service – Optimizing costs while minimizing researchers’ involvement. By default, turning an instance on and off is done manually. This could lead to unnecessary charges caused by human error.
To bridge the gap between the default SageMaker configuration and what we were looking for, we used just two main ingredients: Amazon Elastic File System (Amazon EFS) and lifecycle configuration in SageMaker. The first, as the name implies, is a file system, and the second is basically a piece of code that runs when the notebook is started or first created.
Shared and quick views
We connected this file system to all our notebook instances so that they all have a shared file system. This way we can save our code in Amazon EFS, instead of using the notebook instance’s file system, and access it from any notebook instance.
This made things easier because we can now create a read-only, small, super cheap notebook instance (for this post, let’s call it the viewer instance) that always stays on, and use it to easily access code and results without needing to start the notebook instance that ran the code. Furthermore, we can now easily share code between ourselves because it’s stored in a shared location instead of being kept in multiple different notebook instances.
{kind=link}
So, how do you actually connect a file system to a notebook instance?
We created a lifecycle configuration that connects an EFS to a notebook instance, and attached this configuration to every notebook instance we wanted to be part of the shared environment.
In this section, we walk you through the lifecycle configuration script we wrote, or to be more accurate, stole shamelessly from the examples provided by AWS and mashed them together.
The following script prefix is standard boilerplate:
Now we connect the notebook to an EFS make sure you know the EFS instance’s name:
Persistent and cost-effective service
After we connected the file system, we started thinking about working with notebooks. Because AWS charges for every hour the instance is running, we decided it would be good practice to automatically shut down the SageMaker notebook if it’s idle for a while. We started with a default value of 1 hour, but by using the instance’s tags, users could set any value that suits them from the SageMaker GUI. Applying the default 1-hour configuration could be defined as global lifecycle configuration, and overriding it can be defined as local lifecycle configuration. This policy effectively prevented researchers from accidentally leaving on unused instances, reducing the cost of SageMaker instances by 25%.
{kind=link}
So now the notebook is connected to Amazon EFS and automatically shuts down when idle. But this raised another issue—by default, Python libraries in SageMaker notebook instances are installed in the ephemeral storage, meaning they get deleted when the instance is stopped and have to be reinstalled the next time the instance is started. This means we have to reinstall libraries at least once a day, which isn’t the best experience and can take anywhere between a few seconds to a few minutes per package. We decided to add a script that changes this behavior and causes all library installations to be persistent by changing the Python library installation path to the notebook instance’s storage (Amazon Elastic Block Store), effectively eliminated any time wasted on reinstalling packages.
{kind=link}
This script runs every time the notebook instance starts, installs miniconda and some basic Python libraries in the persistent storage, and activates miniconda:
Quick restart and we’re done!
Data and code organization
Remember the EFS that we just talked about? It’s here for more.
After storing all our code in the same location, we thought it might be better to organize it a bit.
We decided that each team member should create their own notebook instance that only they use. However, instead of using the instance’s file system, we use Amazon EFS and implement the following hierarchy:
——–Team member
—————-Project
————————code
——————————–resources
This way we can all easily access each other’s code, but we still know what belongs to whom.
But what about completed projects? We decided to add an additional branch for projects that have been fully documented and delivered:
——–Team member
—————-Project
————————code
——————————–resources
——–Completed projects
—————-Project
————————code
——————————–resources
So now that our code is organized neatly, how do we access our data?
We keep our data in Amazon Simple Storage Service (Amazon S3) and access it via Amazon Athena. This made it very easy to set a role for our notebook instances with permissions to access Athena and Amazon S3. This way, by simply using a few lines of code, and without messing around with credentials, we can easily query Athena and pull data to work on.
On top of that, we created a dedicated network using Amazon Virtual Private Cloud (Amazon VPC), which gave the notebook instances access to our internal Git repository and private PyPI repository. This made it easy to access useful internal code and packages. The following diagram shows how it all looks in our notebooks platform.
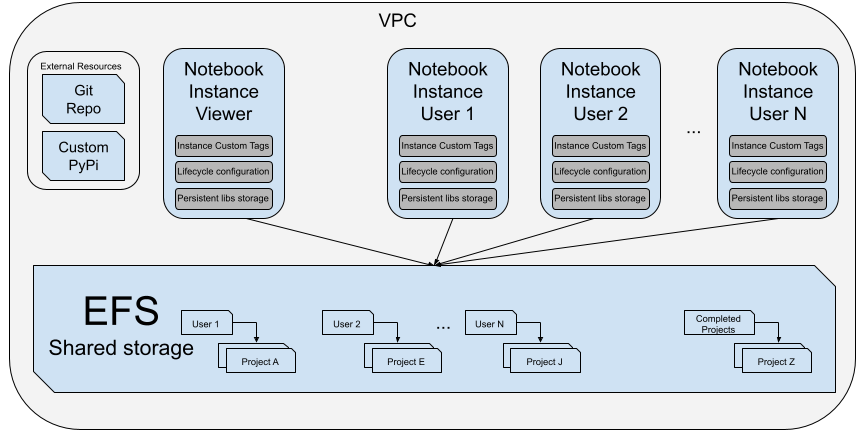{kind=link}
Delivery
Finally, how do we utilize these notebooks to easily deliver projects?
One of the great things about Jupyter notebooks is that, in addition to writing code and displaying the output, you can easily add text and headlines, thereby creating an interactive document.
In the next few lines, we describe our delivery processes when we hand over the model to a dev team, and when we deploy the model ourselves.
On projects where scale, performance, and reliability are a high priority, we hand over the model to be rewritten by a dev team. After we reach a mature POC, we share the notebook with the developers assigned to the project using the previously mentioned read-only notebook instance.
The developers can now read the document, see the input and output for each block of code, and have a better understanding of how it works and why, which makes it easier for them to implement. In the past, we had to write a specification document for these types of cases, which basically means rewriting the code as pseudo code with lots of comments and explanations. Now we could simply integrate our comments and explanation into the SageMaker notebook, which saved many days of work for each project.
On projects that don’t require a dev team to rewrite the code, we reorganize the code inside a Docker container, and deploy it in a Kubernetes cluster. Although it might seem like a hassle to transform code from a notebook into a Dockerized, standard Python project, this process has its own benefits:
Explainability and visibility – Instead of explaining what your algorithm does by diving through your messy project, you can just use the notebook you worked on during the research phase.
Purpose separation – The research code is in the notebook, and the production code is in the Python project. You can keep researching without touching the production code and only update it when you’ve had a breakthrough.
Debuggability – If your model runs into trouble, you can easily debug it in the notebook.
What’s next
Jupyter notebooks provide a great playground for data scientists. On a smaller scale, it’s very convenient to use on your local machine. However, when you start working on larger projects in larger teams, there are many advantages to moving to a managed Jupyter Notebooks server. The great thing about SageMaker notebooks is that you can customize your notebook instances, such as instance size, code sharing, and automation scripts, kernel selection, and more, which helps you save tremendous amounts of time and money
Simply put, we created a process that expedites ML development and collaboration while reducing the cost of SageMaker notebooks by at least 25%, and reducing the overhead time researchers spend on installations and waiting for instances to be ready to work.
Our current SageMaker notebooks environment contains the following:
Managed Jupyter notebook instances
Separate, customizable computing instances for each user
Shared file system used to organize projects and easily share code with peers
Lifecycle configurations that reduce costs and make it easier to start working
Connection to data sources, code repositories, and package indexes
We plan on making this environment even better by adding a few additional features:
Cost monitoring – To monitor our budget, we’ll add a special tag to each instance in order to track their cost.
Auto save state – We’ll create a lifecycle configuration that automatically saves a notebook’s state, allowing users to easily restore the notebook’s state even after it was shut down.
Restricted permissions system – We want to enable users from different groups to participate in our research and explore our data by letting them create notebook instances and access our data, but under predefined restrictions. For example, they’ll only be able to create small, inexpensive notebook instances, and access only a part of the data.
As a next step, we encourage you to try out SageMaker notebooks. For more examples, check out the SageMaker examples GitHub repo.
About the Authors
Matan Lion is Data Science team leader at Imperva’s Threat Research Group. His team is responsible for delivering data-driven solutions and cyber security innovation across the company products portfolio, including application and data security frontlines, leveraging big data and machine learning
{kind=link}
Johnathan Azaria is Data Scientist and a member of Imperva Research Labs, a premier research organization for security analysis, vulnerability discovery and compliance expertise. Prior to the data science role, Johnathan was a security researcher specialized in network and application based attacks. Johnathan holds a B.Sc and an M.Sc in Bioinformatics from Bar Ilan University.
{kind=link}
Yaniv Vaknin is a Machine Learning Specialist at Amazon Web Services. Prior to AWS, Yaniv held leadership positions with AI startups and Enterprise including co-founder and CEO of Dipsee.ai. Yaniv works with AWS customers to harness the power of Machine Learning to solve real world tasks and derive value. In his spare time, Yaniv enjoys playing soccer with his boys.
{kind=link}
Read MoreAWS Machine Learning Blog