

{kind=link}
The latest round of MLPerf benchmark results have been released, and Google’s TPU v4 supercomputers demonstrated record-breaking performance at scale. This is a timely milestone since large-scale machine learning training has enabled many of the recent breakthroughs in AI, with the latest models encompassing billions or even trillions of parameters (T5,Meena,GShard,Switch Transformer, andGPT-3).
Google’s TPU v4 Pod was designed, in part, to meet these expansive training needs, and TPU v4 Pods set performance records in four of the six MLPerf benchmarks Google entered using TensorFlow and JAX. These scores are a significant improvement over our winning submission from last year and demonstrate that Google once again has the world’s fastest machine learning supercomputers. These TPU v4 Pods are already widely deployed throughout Google data centers for our internal machine learning workloads and will be available via Google Cloud later this year.
{kind=link}
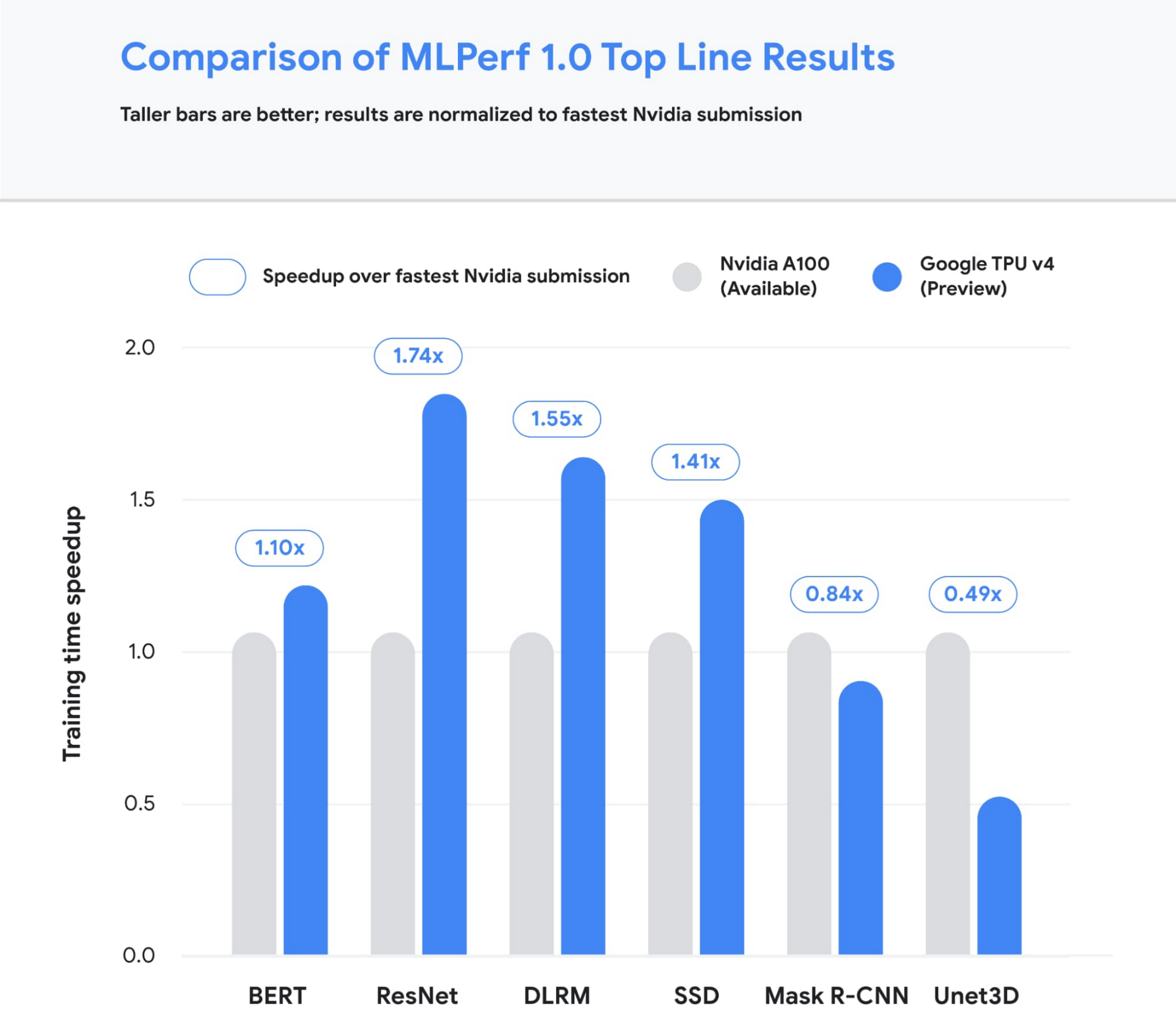
Figure 1: Speedup of Google’s best MLPerf Training v1.0 TPU v4 submission over the fastest non-Google submission in any availability category – in this case, all baseline submissions came from NVIDIA. Comparisons are normalized by overall training time regardless of system size. Taller bars are better.1
Let’s take a closer look at some of the innovations that delivered these ground-breaking results and what this means for large model training at Google and beyond.
Google’s continued performance leadership
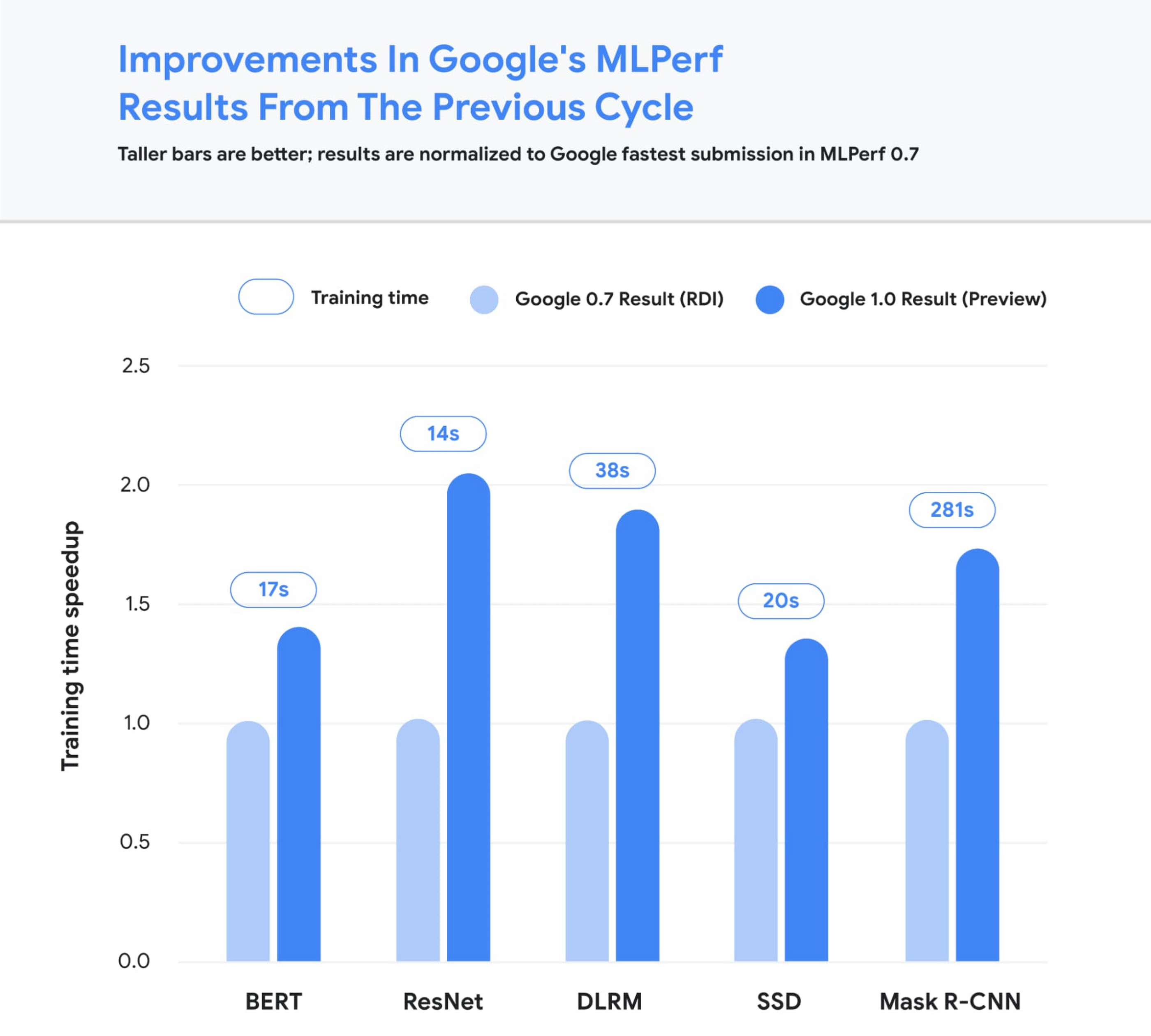
Google’s submissions for the most recent MLPerf demonstrated leading top-line performance (fastest time to reach target quality), setting new performance records in four benchmarks. We achieved this by scaling up to 3,456 of our next-gen TPU v4 ASICs with hundreds of CPU hosts for the multiple benchmarks. We achieved an average of 1.7x improvement in our top-line submissions compared to last year’s results. This means we can now train some of the most common machine learning models in a matter of seconds.
{kind=link}
Figure 2: Speedup of Google’s MLPerf Training v1.0 TPU v4 submission over Google’s MLPerf Training v0.7 TPU v3 submission (exception: DLRM results in MLPerf v0.7 were obtained using TPU v4). Comparisons are normalized by overall training time regardless of system size. Taller bars are better. Unet3D not shown since it is a new benchmark for MLPerf v1.0.2
We achieved these performance improvements through continued investment in both our hardware and software stacks. Part of the speedup comes from using Google’s fourth-generation TPU ASIC, which offers a significant boost in raw processing power over the previous generation, TPU v3. 4,096 of these TPU v4 chips are networked together to create a TPU v4 Pod, with each pod delivering 1.1 exaflop/s of peak performance.
{kind=link}
Figure 3: A visual representation of 1 exaflop/s of computing power. If 10 million laptops were running simultaneously, then all that computing power would almost match the computing power of 1 exaflop/s.
In parallel, we introduced a number of new features into the XLA compiler to improve the performance of any ML model running on TPU v4. One of these features provides the ability to operate two (or potentially more) TPU cores as a single logical device using a shared uniform memory access system. This memory space unification allows the cores to easily share input and output data – allowing for a more performant allocation of work across cores. A second feature improves performance through a fine-grained overlap of compute and communication. Finally, we introduced a technique to automatically transform convolution operations such that space dimensions are converted into additional batch dimensions. This technique improves performance at the low batch sizes that are common at very large scales.
Enabling large model research using carbon-free energy
Though the margin of difference in topline MLPerf benchmarks can be measured in mere seconds, this can translate to many days worth of training time on the state-of-the-art models that comprise billions or trillions of parameters. To give an example, today we can train a 4 trillion parameter dense Transformer with GSPMD on 2048 TPU cores. For context, this is over 20 times larger than the GPT-3 model published by OpenAI last year. We are already using TPU v4 Pods extensively within Google to develop research breakthroughs such as MUM and LaMDA, and improve our core products such as Search, Assistant and Translate. The faster training times from TPUs result in efficiency savings and improved research and development velocity. Many of these TPU v4 Pods will be operating at or near 90% carbon free energy. Furthermore, cloud datacenters can be ~1.4-2X more energy efficient than typical datacenters, and the ML-oriented accelerators – like TPUs – running inside them can be ~2-5X more effective than off-the-shelf systems.
We are also excited to soon offer TPU v4 Pods on Google Cloud, making the world’s fastest machine learning training supercomputers available to customers around the world. Cloud TPUs support leading frameworks such as TensorFlow, PyTorch, and Jax, and we recently released an all-new Cloud TPU system architecture that provides direct access to TPU host machines, greatly improving the user experience.
Want to learn more?
Please contact your Google Cloud sales representative to request early access to Cloud TPU v4 Pods. We are excited to see how you will expand the machine learning frontier with access to exaflops of TPU computing power!
1. All results retrieved from www.mlperf.org on June 30, 2021. MLPerf name and logo are trademarks. See www.mlperf.org for more information. Chart uses results 1.0-1067, 1.0-1070, 1.0-1071, 1.0-1072, 1.0-1073, 1.0-1074, 1.0-1075, 1.0-1076, 1.0-1077, 1.0-1088, 1.0-1089, 1.0-1090, 1.0-1091, 1.0-1092.
2. All results retrieved from www.mlperf.org on June 30, 2021. MLPerf name and logo are trademarks. See www.mlperf.org for more information. Chart uses results 0.7-65, 0.7-66, 0.7-67, 1.0-1088, 1.0-1090, 1.0-1091, 1.0-1092.
Cloud BlogRead More