

{kind=link}
When using databases, you may need to move data into different systems, including other databases or other tools, to perform different analysis. One method to do this is through flat files, such as comma-separated value lists (CSVs), as these let you transfer data in a common format that can be loaded into other systems. PostgreSQL provides the “COPY” command to assist with the generation of flat files.
Some data extraction use cases may require additional steps. For example, Microsoft Excel, which is often used to perform additional analysis or charting on database data, has a feature that lets you keep data in multiple worksheets for other formatting. Data that is exported using the CSV format does not contain the additional info that simplifies visualizing data in Excel.
In this post, we walk you through a solution that provides a mechanism to generate Excel workbooks from Amazon Relational Database Service (Amazon RDS) for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition databases. The solution comprises custom procedures and functions in the database, an AWS Lambda function built using Python, and an Amazon Simple Storage Service (Amazon S3) bucket to store the files. Note that the solution works for both Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL-compatible databases. We are demonstrating the solution for Amazon RDS for PostgreSQL database in this post.
Solution overview
The solution consists of the following components:
Amazon RDS for PostgreSQL
Amazon S3
AWS Lambda
The following diagram illustrates the architecture used in this post.
{kind=link}
The high-level steps for the solution are as follows:
Database or application users run database procedures or functions to process the required data from a table or multiple tables based on the reporting data, and invoke the aws_s3 function to export the data as flat files to an S3 bucket. These files are in CSV format.
The aws_s3 functions invoke the Lambda function to process the CSV files in an S3 bucket and generate the Excel file as needed.
The Lambda function stores the Excel file generated in the same S3 bucket.
Database or application users can download the Excel reports to their local machines or implement scripts to store these reports in a centralized server.
Prerequisites
The following are the prerequisites before you begin to implement the solution:
An existing AWS account or create a new AWS account
An existing Amazon RDS for PostgreSQL database or create the database if you are creating a new AWS account.
Setup Amazon RDS for instance to access Amazon S3 bucket. You can follow the instructions in Setting up access to an Amazon S3 bucket or refer to the Create IAM policies and roles and Integrate Amazon S3 and Aurora PostgreSQL sections of Work with files in Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL.
Implement the solution
This section outlines the detailed steps required to implement the solution. The implementation is based on the scripts stored in the aws-aurora-rds-postgresql-excel-generator repository, which consists of the following files:
aws-aurora-rds-postgresql-excel-generator/sql/utl_file_utility.sql – This file contains the SQL procedures and functions (UTL_FILE) that help store the data in the S3 buckets
aws-aurora-rds-postgresql-excel-generator/sql/PostgreSQL_excel_generator_pkg.sql – This file contains the SQL procedures and functions to format the data in an Excel style
aws-aurora-rds-postgresql-excel-generator/sql/sample_proc_to_format_cells.sql – This file contains a sample procedure to process the data and generate CSV files
aws-aurora-rds-postgresql-excel-generator/Python/zip_rename_to_xlsx.py – This Python script processes the CSV files and generates the Excel sheets
The following are the detailed steps for implementation:
Amazon S3 and Lambda Setup:
Login to your AWS account and execute the following steps:
Create an S3 bucket and a base folder to store the Excel reports. For this post, we create the bucket pg-reports-testing and base folder excel_reports.
Create a Lambda function using the code in zip_rename_to_xlsx.py.
{kind=link}
You can see the code after you create the Lambda function and upload the code as shown in the following screenshot.
{kind=link}
You must add the following environment variables for your Lambda function:
BUCKET_NAME – <your bucket name>
BASE_FOLDER – <your base folder>
The following screenshot is a reference. For our example, the bucket name is pg-reports-testing and the base folder is excel_reports.
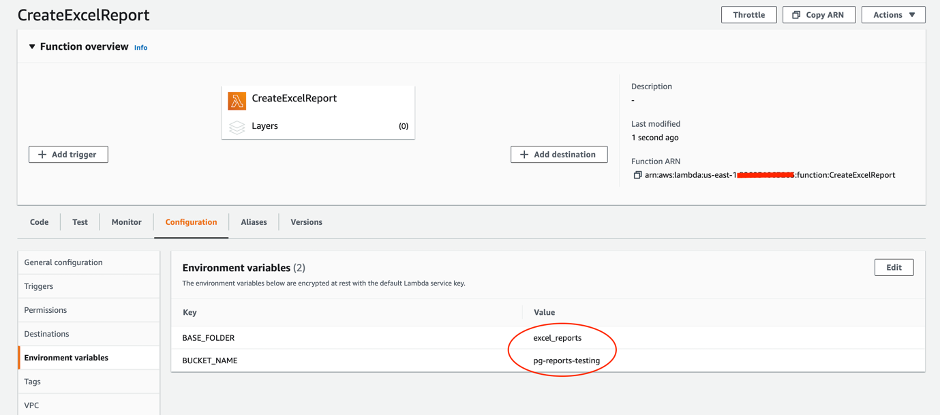{kind=link}
The next step is to provide database access to the Lambda function. For instructions, refer to Invoking an AWS Lambda function from an Aurora PostgreSQL DB cluster.
Create a policy using the code as shown in the following template updating the Resource attribute with your Lambda function’s Amazon Resource Name (ARN).
A message appears when the policy has been created successfully.
{kind=link}
Create a role for Amazon RDS for PostgreSQL or Aurora PostgreSQL by choosing RDS – Add Role to Database as the use case.
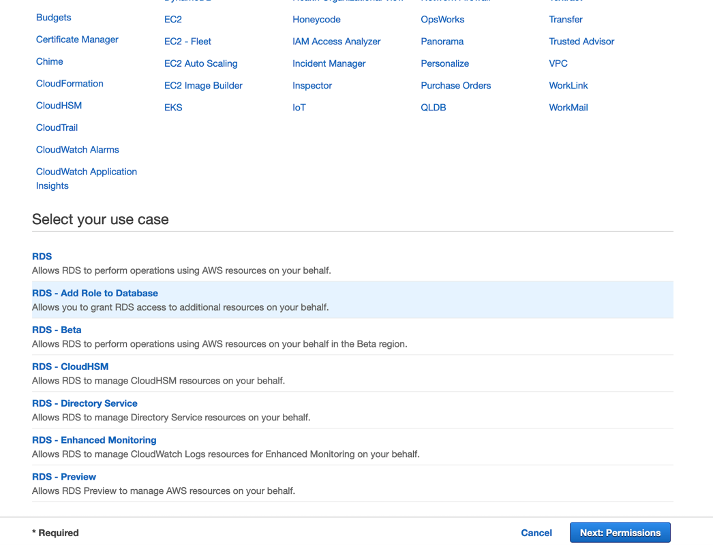{kind=link}
Attach the policy to the role as shown in the following screenshot.
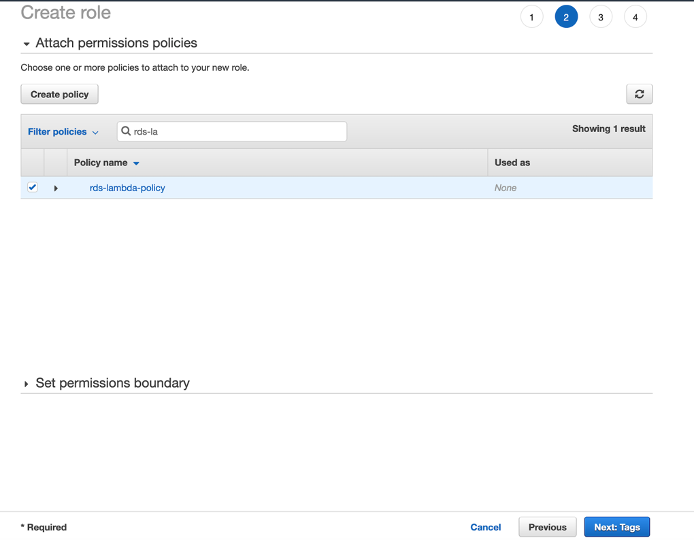{kind=link}
Attach the role to the instance as shown in the following screenshot.
{kind=link}
PostgreSQL Setup
Connect to your Amazon RDS for PostgreSQL instance and execute the following steps. You must run this command as a rds_superuser:
Connect to your database and add the aws_s3 extension.
Note: An excel_test database was created for the solution in the post.
Install the UTL_FILE utility by running the script sql/utl_file_utility.sql in the RDS for PostgreSQL or Aurora PostgreSQL database.
Note that the AWS Region is in the init() function of the script. If you want a different AWS Region, you can change it in the function prior to running the script.
Update the bucket and base folder details by inserting a record in the table utl_file_utility.all_directories:
Note that:
REPORTS is a directory name that you use as an input while generating reports
pg-reports-testing is the S3 bucket name
excel_reports is a directory inside the S3 buckets to store the CSV files.
Note that REPORTS is a directory name that you use as an input while generating reports. Basically, it is categorization of the report. If you have multiple category reports which you save in different buckets or paths, you can insert multiple rows accordingly.
Install the Lambda extension using the following commands:
Install PGEXCEL_BUILDER_PKG by running the script sql/PostgreSQL_excel_generator_pkg.sql in the Amazon RDS for PostgreSQL or Aurora PostgreSQL database:
Create a sample procedure to generate an Excel report using the script sql/sample_proc_to_format_cells.sql
Create a sample table to export data to a workbook sheet:
Run the procedure sample_proc_to_format_cells:
Note that you have to use your Lambda function ARN as an input.
Verify the Excel report generated in the S3 bucket.
{kind=link}
The following screenshots show examples of the different sheets within the Excel workbook.
{kind=link}
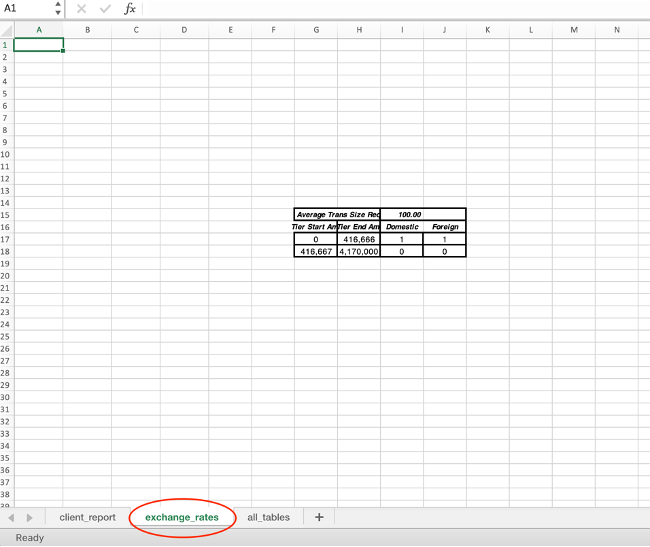{kind=link}
{kind=link}
Cleanup
Cleanup the resources created to the solution implementation once you have tested the solution.
Delete the Amazon S3 bucket
Delete the Lambda function
Remove the IAM roles attached to Amazon RDS PostgreSQL instance
Remove the Policies and IAM roles
Drop the “excel_test” database
Summary
In this post, we demonstrated how you can generate the reports using the aws-aurora-rds-postgresql-excel-generator tool. While this post provided a procedure to generate a simple report, you can use the Excel functions to have the format and the number of sheets based on your requirements.
If you have any questions or suggestions about this post, leave a comment.
About the authors
Baji Shaik is a Database Consultant with Amazon Web Services. His background spans a wide depth and breadth of expertise and experience in SQL/NoSQL database technologies. He is a Database Migration Expert and has developed many successful database solutions addressing challenging business requirements for moving databases from on-premises to Amazon RDS and Aurora PostgreSQL/MySQL. He is an eminent author, having written several books on PostgreSQL. A few of his recent works include PostgreSQL Configuration, Beginning PostgreSQL on the Cloud and PostgreSQL Development Essentials. Furthermore, he has delivered several conference and workshop sessions.
{kind=link}
Anuradha Chintha is a Lead Consultant with Amazon Web Services. She works with customers to build scalable, highly available, and secure solutions in the AWS Cloud. Her focus area is homogeneous and heterogeneous database migrations.
{kind=link}
Uma Agarwal is an Engagement Manager at Amazon Web Services.
Read MoreAWS Database Blog