

{kind=link}
When we analyze images, we may want to incorporate other metadata related to the image. Examples include when and where the image was taken, who took the image, as well as what is featured in the image. One way to represent this metadata is to use a JSON format, which is well-suited for a document database such as Amazon DocumentDB (with MongoDB compatibility). Example use cases include:
Photo-sharing services that want to enable image search and exploration capabilities for users
Online retailers who want to identify similar product images for product recommendation
Healthcare providers who want to query medical image scans related to specific patients or medical conditions
Environmental organizations who want to monitor wildlife conservation efforts using drone imagery
In this post, we focus on the first use case of enabling image search and exploration of a generic photo collection. We look at the JSON output of image analysis generated from Amazon Rekognition, which we ingest into Amazon DocumentDB, and then explore using Amazon SageMaker.
SageMaker is a fully managed service that provides every developer and data scientist the ability to build, train, and deploy machine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the ML process to make it easier to develop high-quality models.
Amazon Rekognition makes it easy to add image and video analysis to your applications. You just provide an image or video to the Amazon Rekognition API, and the service can identify objects, people, text, scenes, and activities. Amazon Rekognition has a simple, easy-to-use API that can quickly analyze any image or video file that’s stored in Amazon Simple Storage Service (Amazon S3). It requires no ML expertise to use.
Amazon DocumentDB is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. You can use the same MongoDB 3.6 or 4.0 application code, drivers, and tools to run, manage, and scale workloads on Amazon DocumentDB without having to worry about managing the underlying infrastructure. As a document database, Amazon DocumentDB makes it easy to store, query, and index JSON data.
Solution overview
In this post, we explore images taken from Unsplash. In the source code, we have kept image file names in their original format, <first name>-<last name>-<image ID>-unsplash.jpg, thereby retaining the photographer’s name, as well as the image ID, from which you can use to determine the image’s original URL: https://unsplash.com/photos/<image ID>.
Each image is analyzed using Amazon Rekognition. The output from the Amazon Rekognition API is a nested JSON object, which is a format well-suited for Amazon DocumentDB. For example, we can analyze the following image, Gardens by the Bay, Singapore, by Coleen Rivas.
{kind=link}
Amazon Rekognition generates the following JSON output:
This output contains the confidence score of finding a variety of types of objects, called labels, in the image.
Those types of objects include Garden, Person, and even Ferris Wheel, among others. You can download the list of supported labels from our documentation page. The output from Amazon Rekognition includes all detected labels over a specified confidence level. In addition to the confidence of the label, it outputs an array of instances in the case that multiple objects of that label have been identified. For example, in the preceding image, Amazon Rekognition identified three Person objects, along with the location in the picture for each identified object.
Amazon DocumentDB stores each JSON output as a document. Multiple documents are stored in a collection, and multiple collections are stored in a database. Borrowing terminology from relational databases, documents are analogous to rows, and collections are analogous to tables. The following table summarizes these terms.
Document Database Concepts
SQL Concepts
Document
Row
Collection
Table
Database
Database
Field
Column
We now implement the following tasks:
Connect to an Amazon DocumentDB cluster.
Upload images to Amazon S3.
Analyze images using Amazon Rekognition.
Ingest Amazon Rekognition output into Amazon DocumentDB.
Explore image labels using Amazon DocumentDB queries.
To conduct these tasks, we use a SageMaker notebook, which is a Jupyter notebook app provided by a SageMaker notebook instance. Although you can use SageMaker notebooks to train and deploy ML models, they’re also useful for code commentary and data exploration, the latter being the focus of our post.
Create resources
We have prepared an AWS CloudFormation template to create the required AWS resources for this post in our GitHub repository. For instructions on creating a CloudFormation stack, see the video Simplify your Infrastructure Management using AWS CloudFormation.
The CloudFormation stack provisions the following:
An Amazon Virtual Private Cloud (Amazon VPC) with three private subnets and one public subnet.
An Amazon DocumentDB cluster with three nodes, one in each private subnet. When creating an Amazon DocumentDB cluster in a VPC, its subnet group should have subnets in at least three Availability Zones in a given Region.
A security group granting access to the Amazon DocumentDB cluster to resources inside the Amazon VPC. This security group is how the SageMaker notebook instance is granted access to the Amazon DocumentDB cluster.
An AWS Secrets Manager secret to store login credentials for Amazon DocumentDB. This allows us to avoid storing plaintext credentials in our SageMaker notebook instance.
A SageMaker role to retrieve the Amazon DocumentDB login credentials, allowing connections to the Amazon DocumentDB cluster from a SageMaker notebook.
A SageMaker notebook instance to run queries and analysis.
A SageMaker instance lifecycle configuration to run a bash script every time the instance boots up and downloads a certificate bundle to create TLS connections to Amazon DocumentDB, as well as a Jupyter notebook containing the code for this tutorial. The script also installs required Python libraries (such as pymongo for database methods and ipyplot for displaying images), so that we don’t need to install these libraries from the notebook. Finally, we download 15 sample images onto the SageMaker instance. See the following code:
Prior to creating the CloudFormation stack, you need to create a bucket in Amazon S3 to store the image files for analysis. For instructions, see Creating a bucket.
When creating the CloudFormation stack, you need to specify the following:
Name for your CloudFormation stack
Amazon DocumentDB username and password (to be stored in Secrets Manager)
Amazon DocumentDB instance type (default db.r5.large)
SageMaker instance type (default ml.t3.xlarge)
Name of your existing S3 bucket where you store your images for analysis
It should take about 15 minutes to create the CloudFormation stack. The following diagram shows the resource architecture.
{kind=link}
This CloudFormation template incurs costs, and you should consult the relevant pricing pages before launching it.
Connect to an Amazon DocumentDB cluster
All the subsequent code in this tutorial is in the Jupyter notebook in the SageMaker instance created in your CloudFormation stack.
To connect to your Amazon DocumentDB cluster from a SageMaker notebook, you have to first specify the following code:
The stack_name refers to the name you specified for your CloudFormation stack upon its creation.
Use this parameter in the following method to get your Amazon DocumentDB credentials stored in Secrets Manager:
Next, we extract the login parameters from the stored secret:
With the extracted parameters, we create a MongoClient from the pymongo library to establish a connection to the Amazon DocumentDB cluster.
We can use the following command to view details of our Amazon DocumentDB cluster, which verifies that the connection has been established:
After we establish the connection to our Amazon DocumentDB cluster, we create a database and collection to store our image analysis data generated from Amazon Rekognition. For this post, we name our database db and our collection coll:
Preview images
We use the ipyplot library to preview the images that were downloaded onto our SageMaker instance using the following code:
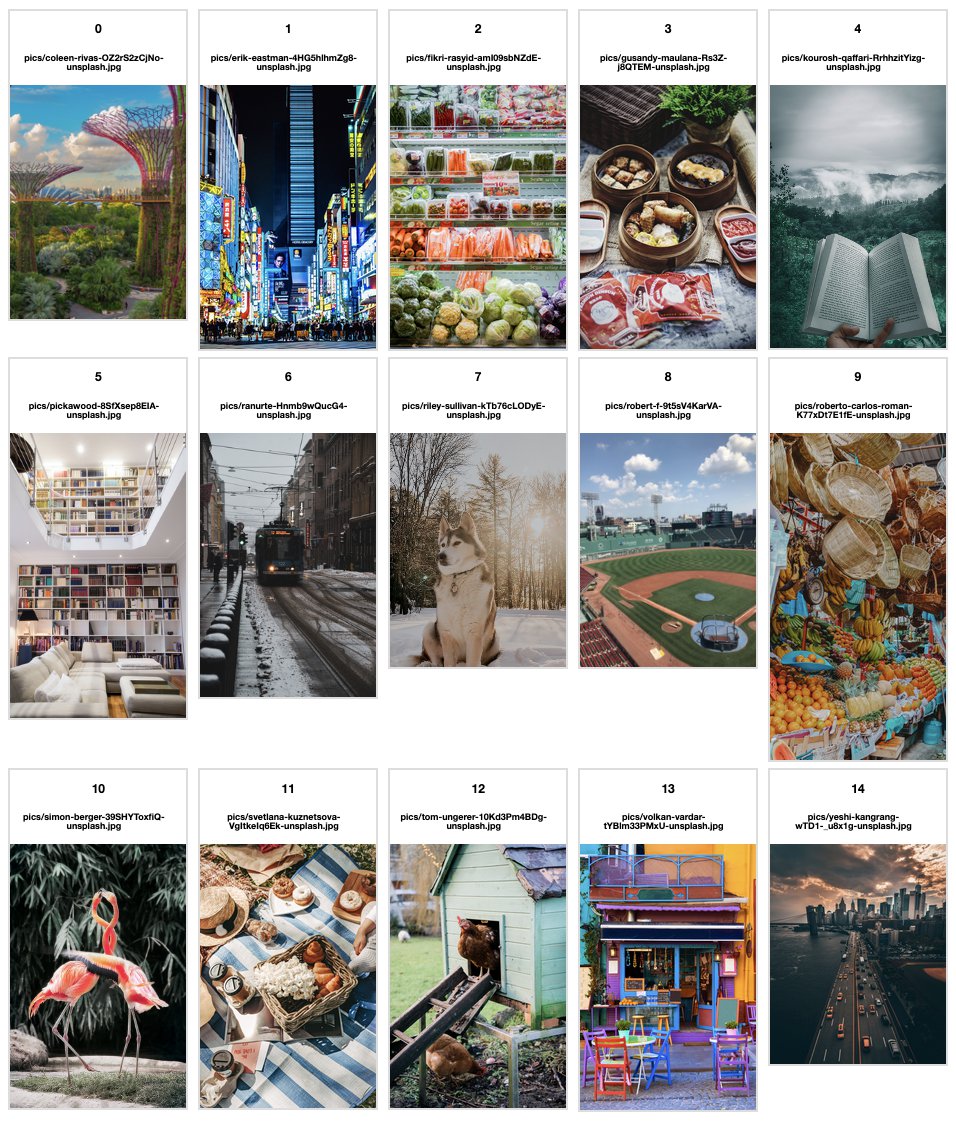{kind=link}
Upload images to Amazon S3
After you verify the images, upload the images to your S3 bucket for Amazon Rekognition to access and analyze:
Then we get the Amazon S3 keys for the images, to tell the Amazon Rekognition API where the images are for analysis:
Ingest analysis results from Amazon Rekognition into Amazon DocumentDB
Next, we loop over every image, analyzing each one using the Amazon Rekognition API, and ingesting the analysis output into Amazon DocumentDB. The results of each image analysis are stored as a document, and all these documents are stored within a collection. Apart from ingesting the analysis results from Amazon Rekognition, we also store each image’s Amazon S3 key, which is used as a unique identifier. See the following code:
Explore image labels using Amazon DocumentDB queries
We can now explore the image labels using Amazon DocumentDB queries.
Frequency counts
As is a common first step in data science, we want to explore the data to get some general descriptive statistics. We can use database operations to calculate some of these basic descriptive statistics.
To get a count of the number of images we ingested, we use the count_documents() command:
The count_documents() command gets the number of documents in a collection. The output from Amazon Rekognition for each image is recorded as a document, and coll is the name of the collection.
Across the 15 images, Amazon Rekognition detected multiple entities. To see the frequency of each entity label, we query the database using the aggregate command. The following query counts the number of times each label appears with a confidence score greater than 90% and then sorts the results in descending order of counts:
We wrap the output of the preceding query in pd.DataFrame() to convert the results to a DataFrame. This allows us to generate visualizations such as the following.
{kind=link}
Based on the plot, Person and Human labels were the most common, with six counts each.
Select images with minimum confidence threshold
Besides labels, Amazon Rekognition also outputs the confidence level with which those labels were applied. The following query identifies the images with a Book label applied with 90% or more confidence:
{kind=link}
We can also search for images containing multiple labels. The following query identifies images that contain the Book and Person labels, both with the minimum confidence level of 90%:
{kind=link}
We can use the explain() method in the MongoDB API to determine what query plan the Amazon DocumentDB query planner used to conduct these queries:
The winningPlan field shows the plan that the Amazon DocumentDB query planner used to run this query. It chose a COLLSCAN, which is a full collection scan, namely to scan each document and apply the predicate on each one.
Similarly, we can see the Amazon DocumentDB query planner also chose a full collection scan for the second query:
Select images with minimum confidence threshold (with index)
As with many database management systems, we can make queries perform better in Amazon DocumentDB by creating an index on commonly queried fields. In this case, we create an index on the label name and label confidence, because these are two fields we’re using in our predicate. After we create the index, we can modify our queries to use it.
To create the index, run the following:
With the index created, we can use the following code block to implement the query to identify images containing books. We add some extra predicates that only find records that have the label Book and a label with a confidence level greater than or equal to 90.0, though not necessarily for the Book label. The query planner uses the index to filter the documents based on these first predicates and then apply the predicate asking for the Book label to have a confidence level greater than or equal to 90.0.
Similarly, we can modify the query looking for both Book and Person labels as follows:
To validate that the Amazon DocumentDB query planner is, in fact, using the index we created, we can again use the explain() method. When we add this method to the query, we can observe the plan that Amazon DocumentDB chose, namely the winningPlan field. It used an IXSCAN stage, indicating that it used the index for this query. This is more efficient than scanning all documents in the collection and applying the predicates to each one.
Select images with specified number instances of a label (array queries)
Besides identifying images with a particular label, you can also specify the number of detected instances of that label. To find all images with at least four instances of Person, each with 90% or more confidence, use the following query:
The query checks if the fourth instance, Instances.3, exists, with instance count starting from zero.
{kind=link}
You can also set a maximum limit for the number of instances. The following query selects all images with at least two but fewer than four instances of a Person label with 90% or more confidence:
{kind=link}
Looking closer, we can see that the first image actually contains many people. Possibly due to how small they appear, fewer than four were detected.
To perform the preceding analysis with your own album, you can replace the sample pictures in Amazon S3 with your own pictures.
Clean up resources
To save cost, delete the CloudFormation stack you created. This removes all the resources you provisioned using the CloudFormation template, including the Amazon VPC, Amazon DocumentDB cluster, and SageMaker notebook instance. For instructions, see Deleting a stack on the AWS CloudFormation console. You should also delete the images in the S3 bucket that you created, along with the images it contains.
Summary
In this post, we analyzed images using Amazon Rekognition, ingested the output into Amazon DocumentDB, and explored the results using queries implemented in SageMaker. For another example of how to use SageMaker to analyze and store data in Amazon DocumentDB for an ML use case, see Analyzing data stored in Amazon DocumentDB (with MongoDB compatibility) using Amazon SageMaker.
Amazon DocumentDB provides you with several capabilities that help you back up and restore your data based on your use case. For more information, see Best Practices for Amazon DocumentDB. If you’re new to Amazon DocumentDB, see Get Started with Amazon DocumentDB. If you’re planning to migrate to Amazon DocumentDB, see Migrating to Amazon DocumentDB.
About the Authors
Annalyn Ng is a Senior Solutions Architect based in Singapore, where she designs and builds cloud solutions for public sector agencies. Annalyn graduated from the University of Cambridge, and blogs about machine learning at algobeans.com. Her book, Numsense! Data Science for the Layman, has been translated into multiple languages and is used in top universities as reference text.
{kind=link}
Brian Hess is a Senior Analytics Platform Specialist at AWS. He has been in the data and analytics space for over 20 years and has extensive experience in roles including solutions architect, product management, and director of advanced analytics.
{kind=link}
Read MoreAWS Machine Learning Blog