

{kind=link}
In this post, you learn about Aurora Serverless v2 databases and factors to consider when replacing provisioned instances with Aurora Serverless v2 instances.
Amazon Aurora Serverless allows you to use Amazon Aurora MySQL-Compatible Edition and Amazon Aurora PostgreSQL-Compatible Edition without worrying about the management of the compute for your application database.
Many organizations today are adopting serverless architecture for building applications. With AWS serverless technologies, these organizations are able to move to market faster, lower their infrastructure costs, and take advantage of inherent scaling. AWS offers serverless services for each of the tiers in a multi-tier application. Depending on your needs, you may select an appropriate data tier serverless service.
Aurora Serverless v2 DB instances
An Aurora Serverless v2 instance is an auto scaling configuration of Aurora. Amazon Aurora provisioned database instance has static capacity, whereas capacity of the Aurora Serverless v2 database instance varies between the minimum and maximum capacity range that is controlled by the user.
The provisioned instance’s static capacity is determined by its class. For example, db.r6g.4xlarge has 128 GB of memory, 16 vCPUs, and up to 10 Gbps of network bandwidth. The capacity allocated to a serverless instance is measured in terms of Aurora Capacity Units (ACUs). 1 ACU is equal to roughly 2 GB of memory, and equivalent CPU and network bandwidth. The allowed minimum ACU is 0.5, which is roughly 1 GB of memory, and maximum ACU can be up to 128 ACU, which is equivalent to roughly 256 GB of memory.
The serverless instance capacity range (minimum ACU–maximum ACU) is specified by you at the cluster level—all Aurora Serverless v2 instances in the cluster are assigned the same capacity range. A cluster may contain a mix of serverless and provisioned instances; this is referred to as mixed-configuration cluster. The following figure depicts such a configuration with a provisioned writer instance and a single serverless read replica.
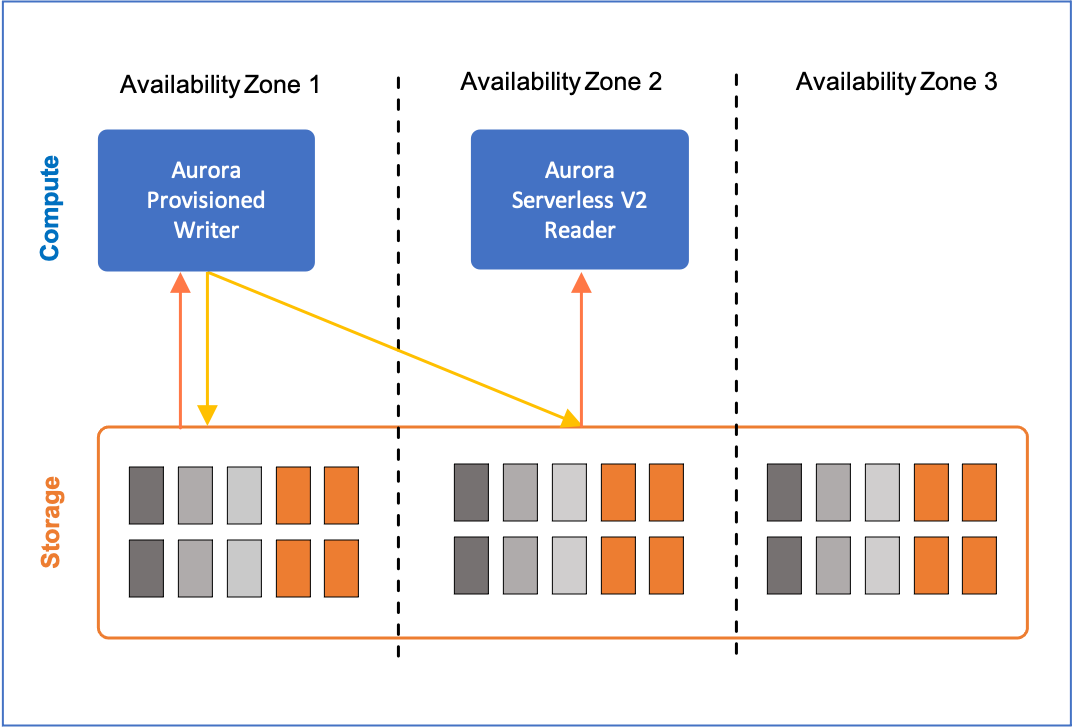{kind=link}
Aurora Serverless v2 instance scaling
Aurora continuously monitors memory, CPU, and network to adjust the database instance capacity to meet the resource demands. Aurora scales up the serverless instance if the instance memory, CPU, network bandwidth is under pressure. It scales down the instance when the pressure on the resources goes down. There are several factors that influence the Aurora Serverless v2 database instance capacity at any point.
Database load
Usage of memory, CPU, and network bandwidth on the writer instance depends on the volume of write and read queries, whereas the usage of these resources on reader instances depends on the volume of read queries and the number of reader instances. When designing a cluster with all serverless database instances, you need to ensure that the cluster capacity range is sufficient for your workload’s read and write throughput requirements.
In addition to query load, background processes running on the database instance also use computational resources. The PostgreSQL vacuum and analyze are examples of such processes. If enabled on the instance, Amazon RDS Performance Insights uses a lightweight agent process to gather metrics. If global database is in use or if Performance Insights is enabled, it’s recommended that the minimum ACU for the cluster be set to 2 ACUs.
Failover priority
The readers in the cluster are assigned a failover priority between 0 (first) and 15 (last). In case of a failover Aurora promotes the reader with better priority to the new primary instance. Aurora ensures that serverless reader instances with priority set to 0 or 1 always have the same capacity allocated as the writer instance. It does this so that adequate capacity is available to support the workload that was running on the previous writer. In other words, the reader will be scaled up to the same level as the writer even when there is no load on it. Readers with priority 2 or above aren’t influenced by the writer’s capacity. It’s important to understand this factor thoroughly because it can affect the operational cost of your cluster.
Factors to consider
Now we discuss the factors that you need to consider for replacing your provisioned instances with Aurora Serverless v2 instances. This guidance is provided purely from a technical perspective. To evaluate if you’re getting any scaling or cost benefits with this change, we recommend that you test your target configuration with a production-like load. In addition to the factors covered in this post, we suggest that you also go through the documentation on Serverless v2 feature support.
Engine version
Aurora Serverless v2 is supported for MySQL 8.0 onwards & PostgreSQL 13 onwards. If your provisioned cluster is at a version lower than the supported version, you need to upgrade your cluster to a supported version before you can take advantage of Aurora Serverless v2 instances.
Instance size
Any database instance in an Aurora cluster with memory up to 256 GB can be replaced with a serverless instance. The minimum capacity for the instance depends on the existing provisioned instance’s resource usage. Keep in mind that if Global Database is in use or if Performance Insights is enabled, the minimum is recommended to be 2 or above. The maximum capacity for the instance may be set to the equivalent of the provisioned instance capacity if it’s able to meet your workload requirements. For example, if the CPU utilization for a db.r6g.4xlarge (128 GB) instance stays at 10% most times, then the minimum ACUs may be set at 6.5 ACUs (10% of 128 GB) and maximum may be set at 64 ACUs (64x2GB=128GB).
Scaling rate
The scaling rate of the Aurora Serverless v2 DB instance depends on its current capacity. The higher the current capacity, the faster it scales. If the workload is sensitive to performance, then it’s recommended that you test your workload with a production-like load and adjust the minimum capacity to achieve the desired performance.
Usage characteristics
Database clusters may have different usage characteristics for the reader and writer instances. By looking at the usage pattern itself, you can gauge if there would be any cost benefit by migrating to Aurora Serverless v2 instances. The following graphs depict common resource usage patterns for the database instances.
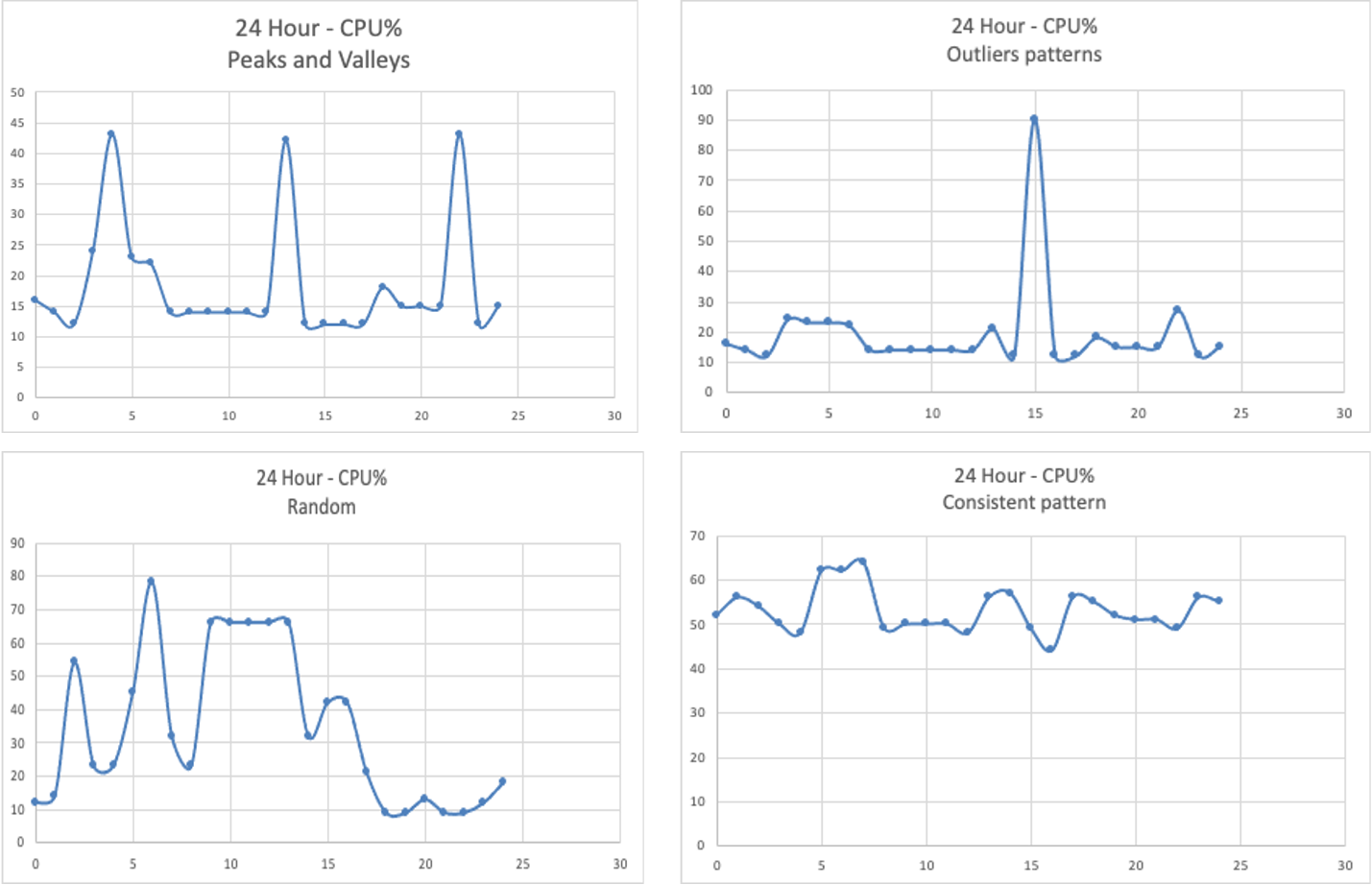{kind=link}
In the peaks and valleys pattern, the usage fluctuates between low and high CPU usage. An example of such an application is an HR application that is mostly used during business hours. With serverless instance you will not need to pay for the peak capacity as the instance will be scaled automatically to accommodate the capacity needs of the workload.
In the outliers pattern, the CPU usage mostly stays low, but then there are usage spikes that lead to higher-than-normal CPU usage. An example of such an application is a global news portal for which the usage spikes up when there is a significant world event. Database instances with these usage patterns are a good candidate for being replaced with serverless.
The random pattern, as the name suggests, is one in which the usage of the database instance is unpredictable. For workloads with unpredictable load characteristics, it’s suggested that you start with a serverless instance to understand the characteristics and then adjust the capacity to achieve optimal performance and cost.
The consistent pattern refers to when the instance resource usage stays within a narrow band most of the time. An example of such an application is an IoT application that gathers continuous sensor data from the field. Because the capacity usage fluctuations aren’t there, you don’t get much benefit from an instance scaling perspective.
Our guidance is to look at the Amazon CloudWatch CPU utilization and memory metrics for your provisioned writer and reader instances to gauge the potential benefits of moving to Aurora Serverless v2.
Failover performance
Consider a cluster in which the write load follows the consistent pattern and the read load follows the outliers pattern. Based on the earlier discussion, you may decide to go with a mixed-configuration cluster with a provisioned writer instance and serverless reader instances.
On failover, the serverless instance becomes the primary (writer), and the provisioned instance becomes the reader. If the serverless instance priority was set to 0 or 1, its capacity will be equivalent to the provisioned instance’s capacity at the time of failover. But if the serverless instance priority is 2 or above, its capacity will not follow the writer’s capacity. In effect, if all readers in the cluster are assigned a priority of 2 or above, you may observe performance degradation for a short duration after the failover. With performance-sensitive workloads, we recommend setting the reader priority for at least one reader equal to 0 or 1. This applies even to a cluster that has all serverless database instances.
The following diagram illustrates our Aurora cluster architecture.
The following diagram illustrates the architecture after failover.
{kind=link}
For faster recovery from failover, we recommend that you consider using the Amazon RDS Proxy service or AWS Aurora JDBC driver for MySQL or PostgreSQL.
Replace auto scaling with instance scaling
Aurora offers an auto scaling mechanism for dynamically adding or removing readers in the cluster. The auto scaling behavior is driven via a policy that uses metrics such as average CPU, average number of database connections, and even custom metrics to adjust the read capacity. When auto scaling is triggered, a new reader instance gets added to the cluster. When the target metric falls below the threshold, the new instance gets removed. This scale-up process may take a few minutes because it launches a new reader database instance. If you’re using the auto scaling feature, you have the option to replace it with vertical scaling offered by Aurora Serverless v2. You can replace your provisioned readers with a larger number of serverless readers with the appropriate cluster capacity range. The benefit of this setup is that vertical scaling at the instance level is extremely fast compared to instance launch, and you pay only for the capacity that you use.
Aurora Serverless v2 in action
In this section, we provide a hands-on experience with Aurora Serverless v2 instances. The steps discussed in this section show you how you can move your provisioned Aurora database cluster to a mixed-configuration cluster and then to a fully serverless cluster. The process that we use for this migration has minimal impact on the running applications during the migration. You will also observe the impact of failover priority on the serverless v2 instance.
Create an Aurora PostgreSQL or MySQL cluster
We start by creating an Aurora PostgreSQL cluster, with one provisioned writer instance and one provisioned reader instance. Let’s use instance class db.r6g.xlarge (32 GB memory) for both the instances. You may use a bastion host to connect with the database cluster. When the cluster is available, test the connectivity to your database instance using an appropriate database client, such as PostgreSQL psql.
The following diagram illustrates this architecture.
{kind=link}
Add a serverless reader
In this step, you add a serverless reader instance to the cluster. The intent is to do it in such a way so as to prevent any interruption to the applications that are using the reader endpoint. Once the reader is added, we get a cluster with a mix of provisioned and serverless instances i.e., a mixed configuration cluster.
{kind=link}
To add the reader, complete the following steps:
On the Amazon RDS console, choose Databases in the navigation pane.
Select your cluster and on the Actions menu, choose Add reader.
For DB instance identifier, enter a name.
For DB instance class, select Serverless v2.
For Capacity range, set minimum ACUs to 2 and maximum to 16.
Under Additional configuration, set Failover Priority to tier-2.
Wait for some time and then check the CloudWatch ServerlessDatabaseCapacity metric for the serverless instance. As depicted in the graph below, you will observe that the capacity allocated to the reader instance is independent of the writer’s capacity and with no load it will settle at 2 ACUs. You may optionally run SQL load against the reader endpoint to see the scaling behavior.
Change the serverless reader failover priority to tier-1
In this step, we modify the priority of the serverless reader instance to tier-1. With this change, the reader capacity will start to follow the writer instance capacity.
On the Amazon RDS console, choose Databases in the navigation pane.
Select the serverless instance.
Under Additional configuration, set Failover priority to tier-1.
For When to apply modifications, choose Apply immediately.
Wait for the modifications to complete and then check the CloudWatch ServerlessDatabaseCapacity metric for the serverless instance. You will observe that the serverless instance’s capacity is fixed at 16 ACU; it’s equivalent to the writer instance’s capacity, which in this test setup is 16 ACUs.
{kind=link}
Drop the provisioned reader and failover
In this step, you will delete the provisioned reader instance and then make the serverless instance the writer by failing over.
On the Amazon RDS console, choose Databases in the navigation pane.
Select the provisioned reader instance and on the Actions menu, choose Delete.
Wait for the deletion to complete.
Now, we carry out the failover.
On the Databases page, select an instance in the cluster.
On the Actions menu, choose Failover.
Wait for the failover to complete. Once the failover has completed the serverless reader instance will become the writer and provisioned instance will be the reader.
The following diagram illustrates our updated architecture.
{kind=link}
Modify the provisioned instance to serverless
In this step, you will modify the provisioned instance class to db.serverless.
On the Amazon RDS console, choose Databases in the navigation pane.
Select the provisioned instance (Reader), choose Modify
Under Instance configuration, select Serverless v2
For When to apply modifications, choose Apply immediately.
At this time, you have converted a test cluster with two fixed capacity database instances to a cluster with two serverless database instances. The maximum capacity (16 ACUs) available for each instance in the cluster is equivalent to the fixed (32 GB) capacity of a db.r6g.xlarge instance. At any point the capacity usage for the instances will be between 2 ACUs and 16 ACUs and you will pay for the actual capacity that you use.
{kind=link}
Clean up
Ensure that all database instances and the bastion host instance are deleted after you’re done testing the serverless instances.
Delete the Aurora cluster you created.
Delete the EC2 instance for the bastion host.
Conclusion
In this post, you learned how to move from provisioned to Aurora Serverless v2 DB instances. Aurora adjusts the serverless instance capacity based on the resource pressure (memory, CPU, network bandwidth) on the instance. The capacity for readers with priority set to 0 or 1 follows the writer’s capacity. It’s important for you to understand this “readers follow writer” mechanism because it has a direct impact on cost and the failover performance of the cluster.
We suggest that you evaluate your existing Aurora databases for a move to Aurora Serverless v2, keeping in mind the factors we have discussed in this post. If you decide to move your workload to serverless, we suggest thorough testing with a production-like load before going to production. Keep in mind that moving to serverless is a low-risk change because you may move back to a provisioned instance configuration any time with minimal impact on applications.
If you have comments about this post, submit them in the comments section.
About the Authors
Rajeev Sakhuja is a Solution Architect based out of New York City. He enjoys partnering with customers to solve complex business problems using AWS services. In his free time, he likes to hike, and create video courses on application architecture & emerging technologies; check him out on Udemy.
Raj Jayakrishnan is a Senior Database Specialist Solutions Architect with Amazon Web Services helping customers reinvent their business through the use of purpose-built database cloud solutions. Over 20 years of experience in architecting commercial & open-source database solutions in financial and logistics industry.
Read MoreAWS Database Blog