

{kind=link}
Many software as a service (SaaS) providers across various industries are adding machine learning (ML) and artificial intelligence (AI) capabilities to their SaaS offerings to address use cases like personalized product recommendation, fraud detection, and accurate demand protection. Some SaaS providers want to build such ML and AI capabilities themselves and deploy them in a multi-tenant environment. However, others who have more advanced customers want to allow their customers to build ML models themselves and use them to augment the SaaS with additional capabilities or override the default implementation of certain functionality.
In this post, we discuss how to enhance your SaaS offering with a data science workbench powered by Amazon SageMaker Studio.
Let’s say an independent software vendor (ISV) named XYZ has a leading CRM SaaS offering that is used by millions of customers to analyze customer purchase behavior. A marketer from the company FOO (an XYZ customer) wants to find their buyers with propensity to churn so they can optimize the ROI of their customer retention programs by targeting such buyers. They previously used simple statistical analysis in the CRM to assess such customers. Now, they want to further improve the ROI by using ML techniques. XYZ can improve their CRM for their customers by using the solution explained in this post and enable FOO’s data science team to build models themselves on top of their data.
SaaS customers interested in this use case want to have access to a data science workbench as part of the SaaS, through which they can access their data residing inside the SaaS with ease, analyze it, extract trends, and build, train, and deploy custom ML models. They want secure integration between the data science workbench and the SaaS, access to a comprehensive and broad set of data science and ML capabilities, and the ability to import additional datasets and join that with data extracted from the SaaS to derive useful insights.
The following diagram illustrates the as-is architecture of XYZ’s CRM SaaS offering.
This architecture consists of the following elements:
Front-end layer – This layer is hosted on Amazon Simple Storage Service (Amazon S3). Amazon CloudFront is used as global content delivery network, and Amazon Cognito is used for user authentication and authorization. This layer includes three web applications:
Landing and sign-up – The public-facing page that customers can find and use to sign up for the CRM solution. Signing up triggers the registration process, which involves creating a new tenant in the system for the customer.
CRM application – Used by customers to manage opportunities, manage their own customers, and more. It relies on Amazon Cognito for authenticating and authorizing users.
CRM admin – Used by the SaaS provider for managing and configuring tenants.
Backend layer – This layer is implemented as two sets of microservices running on Amazon Elastic Kubernetes Service (Amazon EKS):
SaaS services – Includes registration, tenant management, and user management services. A more complete implementation would include additional services for billing and metering.
Application services – Includes customer management, opportunity management, and product catalog services. This set might contain additional services based on the business functionalities provided by the CRM solution.
The next sections of the post discuss how to build a new version of the CRM SaaS with an embedded data science workbench.
Overview of solution
We use Amazon SageMaker to address the requirements of our solution. SageMaker is the most complete end-to-end service for ML. It’s a managed service for data scientists and developers that helps remove the undifferentiated heavy lifting associated with ML, so that you can have more time, resources, and energy to focus on your business.
The features of SageMaker include SageMaker Studio—the first fully integrated development environment (IDE) for ML. It provides a single web-based visual interface where you can perform all ML development steps required to build, train, tune, debug, deploy, and monitor models. It gives data scientists all the tools they need to take ML models from experimentation to production without leaving the IDE.
SageMaker Studio is embedded inside the SaaS as the data science workbench—you can launch it by choosing a link inside the SaaS and get access to the various capabilities of SageMaker. You can use SageMaker Studio to process and analyze your own data stored in the SaaS and extract insights. You can also use SageMaker APIs to build and deploy an ML model, then integrate SaaS processes and workflows with the deployed ML model for more accurate data processing.
This post addresses several considerations required for a solution:
Multi-tenancy approach and accounts setup – How to isolate tenants. This section also discusses a proposed accounts structure.
Provisioning and automation – How to automate the provisioning of the data science workbench.
Integration and identity management – The integration between the SaaS and SageMaker Studio, and the integration with the identity provider (IdP).
Data management – Data extraction and how to make it available to the data science workbench.
We discuss these concepts in the context of the CRM SaaS solution explained at the beginning of the post. The following diagram provides a high-level view of the solution architecture.
As depicted in the preceding diagram, the key change in the architecture is the introduction of the following components:
Data management service – Responsible for extracting the SaaS customer’s data from the SaaS data store and pushing it to the data science workbench.
Data science workbench management service – Responsible for provisioning the data science workbench for SaaS customers and launching it within the SaaS.
Data science workbench – Based on SageMaker Studio, and runs in a separate AWS account. It also includes an S3 bucket that stores the data extracted from the SaaS data store.
The benefits of this solution include the following:
SaaS customers can perform the various data science and ML tasks by launching SageMaker Studio from the SaaS in a separate tab, and use that as the data science workbench, without having to reauthenticate themselves. They don’t have to build and manage a separate data science platform.
SaaS customers can easily extract data residing in the SaaS data store and make it available to the embedded data science workbench without having to have data engineering skills. Also, it’s easier to integrate the ML model they built with the SaaS.
SaaS customers can access the broadest and most complete set of ML capabilities provided by SageMaker.
Multi-tenancy approach and account setup
This section covers how to provision SageMaker Studio for different tenants or SaaS customers (tenant and SaaS customers are used interchangeably because they’re closely related—each SaaS customer has a tenant). The following diagram depicts a multi-account setup that supports provisioning a secured and isolated SageMaker environment for each tenant. The proposed structure is in alignment with AWS best practices for a multi-account setup. For more information, refer to Organizing Your AWS Environment Using Multiple Accounts.
We use AWS Control Tower to implement the proposed multi-account setup. AWS Control Tower provides a framework to set up and extend a well-architected, multi-account AWS environment based on security and compliance best practices. AWS Control Tower uses multiple other AWS services, including AWS Organizations, AWS Service Catalog, and AWS CloudFormation, to build out its account structure and apply guardrails. The guardrails can be AWS Organizations service control policies or AWS Config rules. Account Factory, a feature of AWS Control Tower that enables the standardization of new account provisioning with the proper baselines for centralized logging and auditing, is used to automate the provisioning of new accounts for customers’ SageMaker environments as part of the onboarding process. Refer to AWS Control Tower – Set up & Govern a Multi-Account AWS Environment for more details about AWS Control Tower and how it uses other AWS services under the hood to set up and govern a multi-account setup.
All the accounts hosting customers’ SageMaker environments are under a common organizational unit (OU) to allow for applying common guardrails and automation, including a baseline configuration that creates a SageMaker Studio domain, S3 bucket in which the datasets extracted from SaaS data store reside, cross-account AWS Identity and Access Management (IAM) roles that allows for accessing SageMaker components from within the SaaS, and more.
Tenant isolation
In the context of the SaaS, you can consider various tenant isolation strategies:
Silo model – Each tenant is running a fully siloed stack of resources
Pool model – The same infrastructure and resources are shared across tenants
Bridge model – A solution that involves a mix of the silo and pool models
Refer to the SaaS Tenant Isolation Strategies whitepaper for more details about SaaS tenant isolation strategies.
The silo model is used for SageMaker—a separate or independent SageMaker Studio domain is provisioned for each customer in a separate account as their instance of the data science workbench. The silo model simplifies security setup and isolation. It also provides other benefits like simplifying the calculation of costs associated with the tenant’s consumption of the various SageMaker capabilities.
While the silo isolation strategy is used for the SageMaker environment, the pool model is used for other components (such as the data science workbench management service). Establishing isolation in the silo model, where each tenant operates in its own infrastructure (an AWS account in this case) is much simpler compared to the pool model, where infrastructure is shared. The whitepaper referenced earlier provides guidance on how to establish isolation with a pool model. In this post, we use the following approach:
The user is redirected to the IdP (Amazon Cognito in this case) for authentication. The user enters their user name and password, and upon successful authentication, the IdP returns a token that contains the user information and the tenant identifier. The front end includes the returned token in the subsequent HTTP requests sent by the front end to the microservices.
When the microservice receives a request, it extracts the tenant identifier from the token included in the HTTP request, and assumes an IAM role that corresponds to the tenant. The assumed IAM role permissions are limited to the resources specific to the tenant. Therefore, even if the developer of the microservice made a mistake in the code and tried to access resources that belong to another tenant, the assumed IAM role doesn’t allow that action to proceed.
The IAM role that corresponds to a tenant is created as part of the tenant registration and onboarding.
Other approaches for establishing isolation with pool mode include dynamic generation of policies and roles that are assumed by the microservice at runtime. For more information, refer to the SaaS Tenant Isolation Strategies whitepaper. Another alternative is using ABAC IAM policies—refer to How to implement SaaS tenant isolation with ABAC and AWS IAM for more details.
Provisioning and automation
As depicted earlier, we use AWS Organizations, AWS Service Catalog, and AWS CloudFormation StackSets to implement the required multi-account setup. An important aspect of that is creating a new AWS account per customer to host the SageMaker environment, and how to fully automate this process.
The StackSet for provisioning SageMaker in a customer’s account is created on the management account—the target for the StackSet is the ML OU. When a new account is created under the ML OU, a stack based on the template associated with the StackSet defined in the management account is automatically created in the new account.
Provisioning a SageMaker environment for a tenant is a multi-step process that takes a few minutes to complete. Therefore, an Amazon DynamoDB table is created to store the status of the SageMaker environment provisioning.
The following diagram depicts the flow for provisioning the data science workbench.
The data science workbench management microservice orchestrates the various activities for provisioning the data science workbench for SaaS customers. It calls the AWS Service Catalog ProvisionProduct API to initiate AWS account creation.
As mentioned earlier, the StackSet attached to the ML OU triggers the creation of a SageMaker Studio domain and other resources in a customer account as soon as the account is created under an ML OU as a result of the calling AWS Service Catalog ProvisionProduct API. Another way to achieve that is using AWS Service Catalog—you can create a product for provisioning the SageMaker Studio environment and add it to a portfolio. Then the portfolio is shared with all AWS accounts under the ML OU. The data science workbench management microservice has to make an explicit call to the AWS Service Catalog API after the completion of the AWS account creation to trigger the SageMaker Studio environment creation. AWS Service Catalog is very useful if you need to support multiple data science workbench variants—the user selects from a list of variants, and the data science workbench management microservice maps the user selection to a product defined in AWS Service Catalog. Then it invokes the ProvisionProduct API with the corresponding product ID.
After AWS account creation, a CreateManagedAccount event is published by AWS Control Tower to Amazon EventBridge. A rule is configured in EventBridge to send CreateManagedAccount events to an Amazon Simple Queue Service (Amazon SQS) queue. The data science workbench management microservice polls the SQS queue, retrieves CreateManagedAccount events, and invokes the tenant management service to add the created AWS account number (part of the event message) to the tenant metadata.
The state of the data science workbench provisioning requests is stored in a DynamoDB table so the users can inquire about it at any point of time.
Integration and identity management
This section focuses on the integration between SaaS and SageMaker Studio (which covers launching SageMaker Studio from within the SaaS) and identity management. We use Amazon Cognito as the IdP in this solution, but if the SaaS is already integrated with another IdP that supports OAuth 2.0/OpenID Connect, you can continue using that because the same design applies.
SageMaker Studio supports authentication via AWS Single Sign-On (AWS SSO) and IAM. Given that the AWS organization in this case is managed by the SaaS provider, it’s likely that AWS SSO is connected to the SaaS provider IdP, not the SaaS customer IdP. Therefore, we use IAM to authenticate users accessing SageMaker Studio.
Authenticating users accessing SageMaker Studio using IAM entails creating a user profile for each user on the SageMaker domain and mapping their identity in Amazon Cognito to the created user profile. One simple way to achieve that is by using their user name in Amazon Cognito as their user profile name in the SageMaker Studio domain. SageMaker provides the CreateUserProfile API, which can be used to programmatically creates a user profile for the user the first time they attempt to launch SageMaker Studio.
With regards to launching SageMaker Studio from within the SaaS, SageMaker exposes the CreatePresignedDomainUrl API, which generates the presigned URL for SageMaker Studio. The generated presigned URL is passed to the UI to launch SageMaker Studio in another browser tab.
The following diagram depicts the architecture for establishing integration between the SaaS and SageMaker Studio.
The data science workbench management microservice handles the generation of the presigned URL that is used to launch SageMaker Studio that exists in the customer account. It calls the tenant management microservice to retrieve the AWS account number that corresponds to the tenant ID included in the request, assumes an IAM role in this account with the required permissions, and calls the SageMaker CreatePresignedDomainUrl API to generate the presigned URL.
If the user is launching SageMaker Studio for the first time, a user profile needs to be created for them first. This is achieved by calling the SageMaker CreateUserProfile API.
The users can use the data science workbench to perform data processing at scale, train an ML model and using it for batch inference, and create enriched datasets. They can also use it to build and train an ML model, host this ML model on SageMaker managed hosting, and invoke it from the SaaS to realize a use case like the one mentioned at the beginning of the post (replacing a simple statistical analysis capability that predicts customer churn with an advanced ML-based capability that the customer themselves build the model for). The following diagram depicts one approach to achieve this.
{kind=link}
The SaaS customer data scientist launches the data science workbench (SageMaker Studio) and uses it to preprocess the extracted data using SageMaker Processing (alternatively, you can use SageMaker Data Wrangler). They decide which ML algorithm to use and initiate a SageMaker training job to train the model with the preprocessed data. Then, they do the necessary model evaluation in a SageMaker Studio notebook, and if they’re happy with the results, they use SageMaker managed hosting to deploy and host the produced ML model.
After the ML is deployed, the data scientist goes to the SaaS and provides the details of the SageMaker endpoint hosting the ML model. This triggers a call to the tenant management microservice to add the SageMaker endpoint details to the tenant information. Then, when a call is made to the customer management microservice, it calls the tenant management microservice to retrieve tenant information, including the AWS account number and the SageMaker endpoint details. It then assumes an IAM role in the customer account with the required permissions, calls the SageMaker endpoint to calculate customer churn probability, and includes the output in the response message.
The ML endpoint called by the customer management microservice is dynamic (retrieved from the tenant management service), but the interface is fixed, and it is pre-defined by the SaaS provider – this includes the format (e.g., application/json), the features that the SaaS sends to the ML model, their ordering, and the output as well. The SaaS customer is expected to build an ML model that aligns with the interface defined by the SaaS provider. The interface details, and a sample request/response, are going to be presented to the SaaS customer on the app page that will allow them to override the implementation with their own ML model. The SaaS microservice (customer management microservice in the diagram above) performs the required transformation and serialization to produce the features expected by the ML endpoint in the specified format, invokes the ML endpoint, performs the required deserialization and transformation, and then include the inference output in the response returned by the microservice.
It may happen that the SaaS customer wants to exclude features that are not relevant to their model, or add features on top of what the SaaS passed. This can be achieved leveraging Use Your Own Inference Code, where they have full control over inference code.
Data management
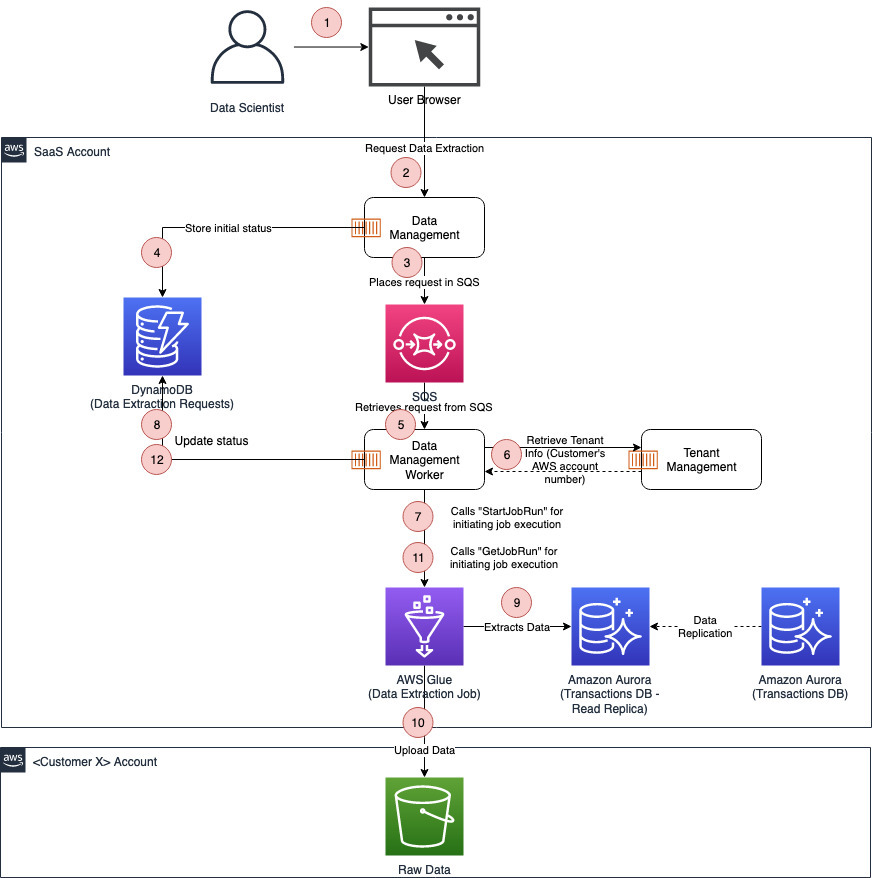
This section covers a proposed architecture for building the data management microservice, which is one of the approaches you can follow to allow SaaS customers to access the data residing in the SaaS data store. The data management microservice receives data extraction requests from data scientists, and runs these requests in a controlled way to avoid negatively impacting SaaS data store performance. The microservice is also responsible for controlling access to the SaaS data store (which data elements are included in the data extract), and data masking and anonymization, if required.
The following diagram depicts a potential design for the data management microservice.
{kind=link}
The data management microservice is split into two components:
Data management – Receives the data extraction request, places it in a queue, and sends an acknowledgment as a response
Data management worker – Retrieves the request from the queue and processes it by calling an AWS Glue job
This decoupling allows you to scale the two components independently and control the load on the SaaS data store, regardless of the volume of the data extraction requests.
The AWS Glue job extracts the data from a replica for the transactions database, rather than the primary instance of the database. This prevents data extraction requests from negatively impacting the performance of the SaaS.
The AWS Glue job uploads the extracted data to an S3 bucket in the AWS account created a specific customer. Therefore, the data management worker component needs to call the tenant management microservice to retrieve the AWS account number, which is part of the tenant information.
The state of the data extraction requests is stored in a DynamoDB table so the users can inquire about it at any point of time.
Conclusion
In this post, we showed you how to build a data science workbench within your SaaS using SageMaker Studio. We have covered aspects like AWS account structure, tenant isolation, extracting data from the SaaS data store and making it accessible to the data science workbench, launching SageMaker Studio from within the SaaS, managing identities, and finally provisioning the data science workbench in an automated way using services like AWS Control Tower, AWS Organizations, and AWS CloudFormation.
We hope this helps you expand the usage of ML in your SaaS and provide your customers with a more flexible solution that allows them to consume the ML capabilities that you provide them and also to build ML capabilities themselves.
About the Authors
Islam Mahgoub is a Solutions Architect at AWS with 15 years of experience in application, integration, and technology architecture. At AWS, he helps customers build new cloud native solutions and modernise their legacy applications leveraging AWS services. Outside of work, Islam enjoys walking, watching movies, and listening to music.
Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years software engineering an ML background, he works with customers of any size to deeply understand their business and technical needs and design AI and Machine Learning solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, Computer Vision, NLP, and involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.
Arunprasath Shankar is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
Read MoreAWS Machine Learning Blog