

{kind=link}
Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. You can use the same MongoDB 3.6 and 4.0 application code, drivers, and tools to run, manage, and scale workloads on Amazon DocumentDB without worrying about managing the underlying infrastructure. As a document database, Amazon DocumentDB makes it easy to store, query, and index JSON data.
Hackolade is the pioneer for data modeling of NoSQL databases and design of REST APIs. The Hackolade Studio application is the one-of-a-kind schema design tool for all the leading technologies of data at rest and data in motion. Hackolade also applies its easy and visual design to Avro, JSON Schema, Parquet, Protobuf, Swagger, and OpenAPI, and is rapidly adding support for new targets. Amazon DocumentDB was recently added as a target to help you visualize and model JSON data with nested objects and arrays.
In this post, we discuss factors to consider when modeling JSON documents and how Hackolade can help with forward- or reverse-engineering to model documents. We also discuss how Hackolade can help with data modeling when migrating from relational databases to Amazon DocumentDB.
Document modeling
JSON is a flexible and natural format, and document databases use this format to store data with schema flexibility. In addition to storing data, document databases allow developers to index and query JSON data natively. The ability to run ad hoc queries and flexibly index data has made document databases a popular choice for application developers. Document modeling for JSON data greatly impacts the performance and efficiency of these queries and indexes. Document modeling is the process of structuring your JSON data, defining data types and relationships with other documents. Access patterns for the application dictate the schema structure of documents stored in the database. Schema flexibility offered by JSON allows you to make changes quickly, making document databases an ideal choice for agile development.
Data modeling for relational databases is performed according to the rules of normalization, so larger tables are divided into smaller ones linked together with relationships. The purpose is to eliminate redundant or duplicate data. For example, in the following order entity, multiple tables are used to store different pieces of information.
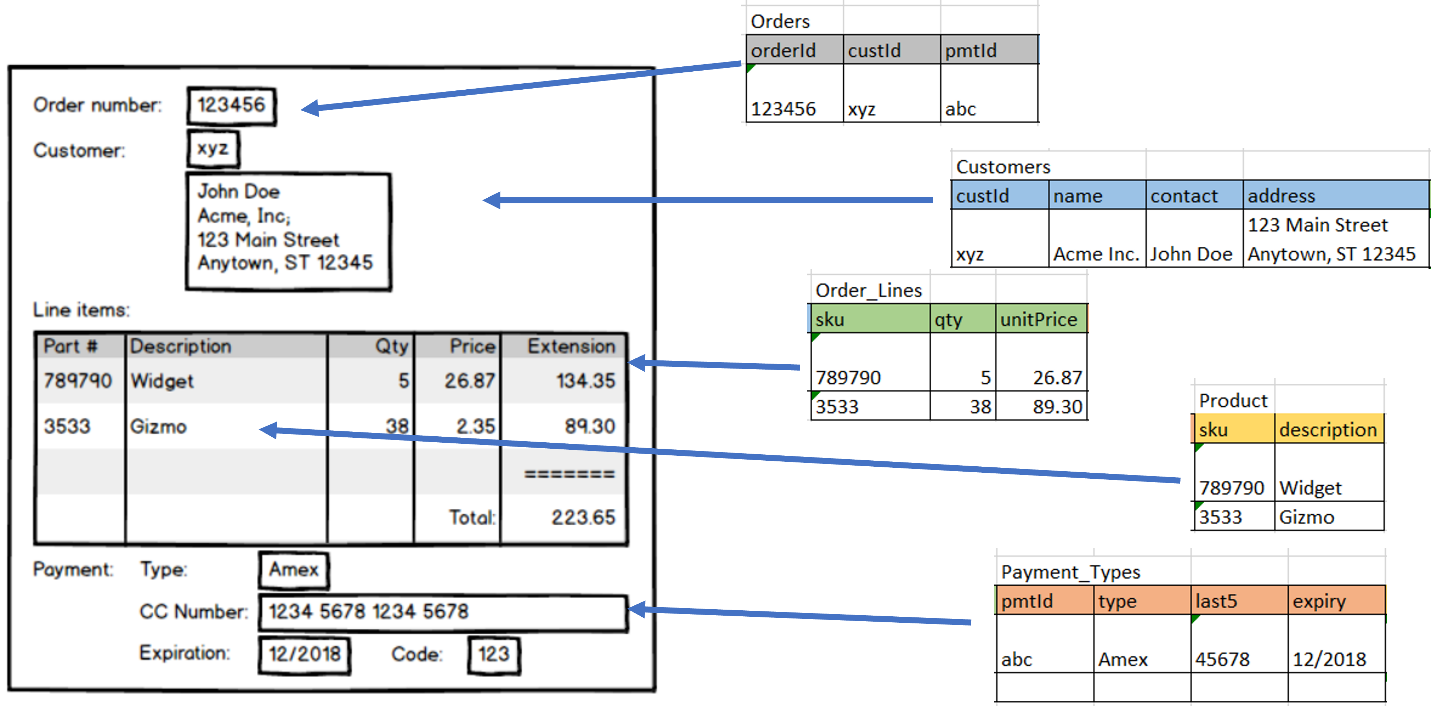{kind=link}
To take advantage of the performance of Amazon DocumentDB and the flexibility of JSON, it’s important to unlearn the rules of normalization. JSON allows developers to aggregate information that belongs together so it’s ready to be used, instead of splitting data across separate tables, as normalization rules would dictate. In other words, there’s an opportunity to join the data on write, instead of the traditional joins on read of relational databases, which negatively impact performance. This difference is decisively important nowadays when real-time web applications and big data require high scalability and high availability.
The following figure illustrates an example of denormalization.
{kind=link}
Embedding vs. referencing
It’s important to follow a query-driven data modeling approach for NoSQL databases. With a query-driven design, the application retrieves all the necessary data with a single access to the database, without having to join with data coming from multiple sources. This approach is called embedding, whereby the data, which would be in separate tables if normalized, is assembled and stored in a single document, so it can be easily retrieved. In contrast, referencing is an approach that uses foreign key relationships to retrieve the data stored elsewhere. Although referencing is more efficient in terms of storage costs, embedding provides much higher access performance and is easier for developers to manipulate.
You should consider the following additional factors when designing a document schema:
Size – Embedding documents into a single atomic unit helps with speed and simplicity with respect to data retrieval and persistence. But it could result in the document growing in size relatively quickly depending on the cardinality of the embedded documents. It is ideal to limit per-document size to 8 KB or less for optimal performance because larger document sizes require additional processing and system resources such as I/O.
Access patterns – Storing infrequently accessed fields in a separate document helps reduce I/O utilization and improve performance. When mutable and immutable parts of the documents are separated, performance and I/O optimization is optimized because updates modify smaller mutable documents.
Speed – When referencing documents, the data model contains separate documents for each entity, and data retrieval might be slower due to the need to perform joins. Therefore, consider your application latency requirements while modeling documents. On the other hand, embedding documents can result in better read latency because you don’t have to perform joins to retrieve documents.
Atomicity – Create, read, update, and delete (CRUD) operations are atomic at the document level. When referencing data across different documents, determine if the application will be impacted if some documents are not committed. If the application will be impacted, consider embedding related entities in the same document for faster access, simplicity, and to avoid the need for ACID transactions.
Denormalization – Use selective denormalization to logically model your entity. In document databases, it’s a common practice to duplicate data. But ensure that you don’t increase the document size significantly by excessive denormalization. If the document model contains separate documents for each entity, the application is responsible for updating fields that are duplicated across all documents. Therefore, the decision to model documents should consider application access patterns and complexity.
Tooling for document modeling
Schema design for JSON documents is a balancing act considering the aforementioned factors; using a data modeling tool helps simplify the process. While schemas in JSON can quickly evolve, development costs can skyrocket if application code has to be constantly reworked to accommodate changes in the schema. A design-first approach enables us to think through the different factors impacting the schema, and to discuss it among the stakeholders of the application.
Hackolade provides a graphical entity-relationship diagram (see the following screenshot), extended to represent the nested structure of embedded documents. It makes it easy for non-developers to understand the meaning and context of the data stored in JSON. It enables a conversation around the design of the database to evaluate different ways to denormalize data to meet the objectives of the application.
{kind=link}
The advantages include lower Total Cost of Ownership (TCO), higher quality, easier evolution, and quicker delivery of projects. Although it may seem slower at the beginning, a design-first approach saves time overall because it reduces risks of rework.
Use cases
One use case for such a tool is to let teams start from a blank page, elaborate the different schemas, discuss, and evolve them. The team can then generate, or forward-engineer, artifacts to be used during development. The following screenshot shows an example of forward-engineering scripts in Amazon DocumentDB. For more information, refer to Export or forward-engineer.
{kind=link}
Another use case is to reverse-engineer an existing instance to draw the entity-relationship diagram and enrich the model with descriptions and constraints. This reverse-engineering process is useful for data governance, to compare the structures in production with the baseline design, and to share the meaning and context of the data with the data community on the business side of organizations. The following screenshot shows the selection dialog for the reverse-engineering process. For more information, refer to Import or reverse-engineer.
{kind=link}
The aforementioned functions are available through the Hackolade GUI and also through a command-line interface to be integrated in DevOps CI/CD pipelines or scheduled jobs.
Another use case is when migrating a normalized SQL data model to a denormalized schema with embedding. Hackolade has a function to help data modelers through this exercise. The following screenshot shows an example dialog to select tables to be combined in denormalization. For more information, refer to Suggest denormalization of a SQL schema.
{kind=link}
Summary
In this post, we reviewed the best practices when data modeling for Amazon DocumentDB:
When appropriate, use an embedding pattern to join data on write, instead of the traditional joins on read of relational databases
Balance this approach with other important factors, such as the size of documents, the cardinality of relationships, access patterns, speed, and atomicity
Use a data modeling tool to iterate your designs, collaborate and communicate, and achieve higher quality and lower cost of ownership
To get started, you can go to the AWS Management Console to spin up a new Amazon DocumentDB cluster, and download a free trial of Hackolade.
About the Authors
Karthik Vijayraghavan is a Senior DocumentDB Specialist Solutions Architect at AWS. He has been helping customers modernize their applications using NoSQL databases. He enjoys solving customer problems and is passionate about providing cost effective solutions that performs at scale. Karthik started his career as a developer building web and REST services with strong focus on integration with relational databases and hence can relate to customers that are in the process of migration to NoSQL.
Pascal Desmarets is the Founder and CEO of Hackolade. He leads the company and all efforts involving business strategy, product innovation, and customer relations, as it focuses on producing user-friendly, powerful visual tools to smooth the onboarding of NoSQL technology in enterprise IT landscapes.
{kind=link}
Read MoreAWS Database Blog