

{kind=link}
AWS customers are relying on Infrastructure as Code (IaC) to design, develop, and manage their cloud infrastructure. IaC ensures that customer infrastructure and services are consistent, scalable, and reproducible, while being able to follow best practices in the area of development operations (DevOps).
One possible approach to manage AWS infrastructure and services with IaC is Terraform, which allows developers to organize their infrastructure in reusable code modules. This aspect is increasingly gaining importance in the area of machine learning (ML). Developing and managing ML pipelines, including training and inference with Terraform as IaC, lets you easily scale for multiple ML use cases or Regions without having to develop the infrastructure from scratch. Furthermore, it provides consistency for the infrastructure (for example, instance type and size) for training and inference across different implementations of the ML pipeline. This lets you route requests and incoming traffic to different Amazon SageMaker endpoints.
In this post, we show you how to deploy and manage ML pipelines using Terraform and Amazon SageMaker.
Solution overview
This post provides code and walks you through the steps necessary to deploy AWS infrastructure for ML pipelines with Terraform for model training and inference using Amazon SageMaker. The ML pipeline is managed via AWS Step Functions to orchestrate the different steps implemented in the ML pipeline, as illustrated in the following figure.
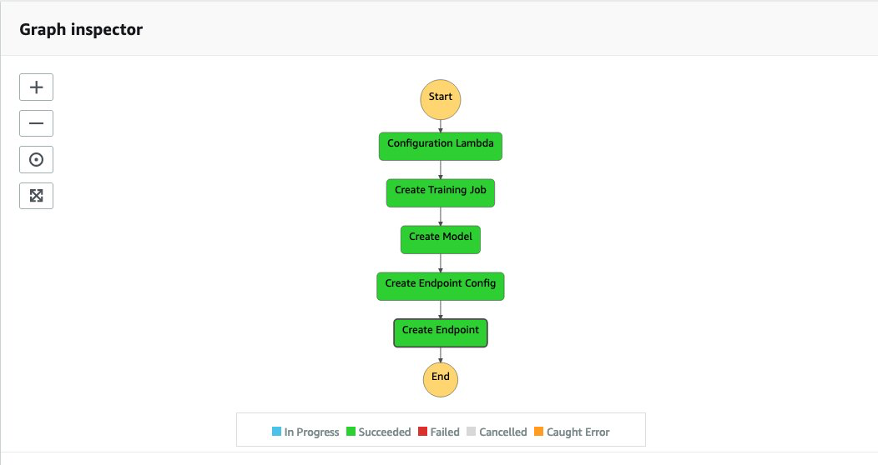{kind=link}
Step Functions starts an AWS Lambda function, generating a unique job ID, which is then used when starting a SageMaker training job. Step Functions also creates a model, endpoint configuration, and endpoint used for inference. Additional resources include the following:
AWS Identity and Access Management (IAM) roles and policies attached to the resources in order to enable interaction with other resources
Amazon Simple Storage Service (Amazon S3) buckets for training data and model output
An Amazon Elastic Container Registry (Amazon ECR) repository for the Docker image containing the training and inference logic
The ML-related code for training and inference with a Docker image relies mainly on existing work in the following GitHub repository.
The following diagram illustrates the solution architecture:
{kind=link}
We walk you through the following high-level steps:
Deploy your AWS infrastructure with Terraform.
Push your Docker image to Amazon ECR.
Run the ML pipeline.
Invoke your endpoint.
Repository structure
You can find the repository containing the code and data used for this post in the following GitHub repository.
The repository includes the following directories:
/terraform – Consists of the following subfolders:
./infrastructure – Contains the main.tf file calling the ML pipeline module, in addition to variable declarations that we use to deploy the infrastructure
./ml-pipeline-module – Contains the Terraform ML pipeline module, which we can reuse
/src – Consists of the following subfolders:
./container – Contains example code for training and inference with the definitions for the Docker image
./lambda_function – Contains the Python code for the Lambda function generating configurations, such as a unique job ID for the SageMaker training job
/data – Contains the following file:
./iris.csv – Contains data for training the ML model
Prerequisites
For this walkthrough, you should have the following prerequisites:
An AWS account
Terraform version 0.13.5 or greater
AWS Command Line Interface (AWS CLI) v2
Python 3.7 or greater
Docker
Deploy your AWS infrastructure with Terraform
To deploy the ML pipeline, you need to adjust a few variables and names according to your needs. The code for this step is in the /terraform directory.
When initializing for the first time, open the file terraform/infrastructure/terraform.tfvars and adjust the variable project_name to the name of your project, in addition to the variable region if you want to deploy in another Region. You can also change additional variables such as instance types for training and inference.
Then use the following commands to deploy the infrastructure with Terraform:
Check the output and make sure that the planned resources appear correctly, and confirm with yes in the apply stage if everything is correct. Then go to the Amazon ECR console (or check the output of Terraform in the terminal) and get the URL for your ECR repository that you created via Terraform.
The output should look similar to the following displayed output, including the ECR repository URL:
Push your Docker image to Amazon ECR
For the ML pipeline and SageMaker to train and provision a SageMaker endpoint for inference, you need to provide a Docker image and store it in Amazon ECR. You can find an example in the directory src/container. If you have already applied the AWS infrastructure from the earlier step, you can push the Docker image as described. After your Docker image is developed, you can take the following actions and push it to Amazon ECR (adjust the Amazon ECR URL according to your needs):
If you have already applied the AWS infrastructure with Terraform, you can push the changes of your code and Docker image directly to Amazon ECR without deploying via Terraform again.
Run the ML pipeline
To train and run the ML pipeline, go to the Step Functions console and start the implementation. You can check the progress of each step in the visualization of the state machine. You can also check the SageMaker training job progress and the status of your SageMaker endpoint.
{kind=link}
After you successfully run the state machine in Step Functions, you can see that the SageMaker endpoint has been created. On the SageMaker console, choose Inference in the navigation pane, then Endpoints. Make sure to wait for the status to change to InService.
{kind=link}
Invoke your endpoint
To invoke your endpoint (in this example, for the iris dataset), you can use the following Python script with the AWS SDK for Python (Boto3). You can do this from a SageMaker notebook, or embed the following code snippet in a Lambda function:
Clean up
You can destroy the infrastructure created by Terraform with the command terraform destroy, but you need to delete the data and files in the S3 buckets first. Furthermore, the SageMaker endpoint (or multiple SageMaker endpoints if run multiple times) is created via Step Functions and not managed via Terraform. This means that the deployment happens when running the ML pipeline with Step Functions. Therefore, make sure you delete the SageMaker endpoint or endpoints created via the Step Functions ML pipeline as well to avoid unnecessary costs. Complete the following steps:
On the Amazon S3 console, delete the dataset in the S3 training bucket.
Delete all the models you trained via the ML pipeline in the S3 models bucket, either via the Amazon S3 console or the AWS CLI.
Destroy the infrastructure created via Terraform:
Delete the SageMaker endpoints, endpoint configuration, and models created via Step Functions, either on the SageMaker console or via the AWS CLI.
Conclusion
Congratulations! You’ve deployed an ML pipeline using SageMaker with Terraform. This example solution shows how you can easily deploy AWS infrastructure and services for ML pipelines in a reusable fashion. This allows you to scale for multiple use cases or Regions, and enables training and deploying ML models with one click in a consistent way. Furthermore, you can run the ML pipeline multiple times, for example, when new data is available or you want to change the algorithm code. You can also choose to route requests or traffic to different SageMaker endpoints.
I encourage you to explore adding security features and adopting security best practices according to your needs and potential company standards. Additionally, embedding this solution into your CI/CD pipelines will give you further capabilities in adopting and establishing DevOps best practices and standards according to your requirements.
About the Author
Oliver Zollikofer is a Data Scientist at Amazon Web Services. He enables global enterprise customers to build, train and deploy machine learning models, as well as managing the ML model lifecycle with MLOps. Further, he builds and architects related cloud solutions.
{kind=link}
Read MoreAWS Machine Learning Blog