

{kind=link}
Last Updated on March 28, 2022
Data visualization is an important aspect of all AI and machine learning applications. You can gain key insights of your data through different graphical representations. In this tutorial, we’ll talk about a few options for data visualization in Python. We’ll use the MNIST dataset and the Tensorflow library for number crunching and data manipulation. To illustrate various methods for creating different types of graphs, we’ll use the Python’s graphing libraries namely matplotlib, Seaborn and Bokeh.
After completing this tutorial, you will know:
How to visualize images in matplotlib
How to make scatter plots in matplotlib, Seaborn and Bokeh
How to make multiline plots in matplotlib, Seaborn and Bokeh
Let’s get started.
{kind=link}
Data Visualization in Python With matplotlib, Seaborn and Bokeh
Photo by Mehreen Saeed, some rights reserved.
Tutorial Overview
This tutorial is divided into 7 parts; they are:
Preparation of scatter data
Figures in matplotlib
Scatter plots in matplotlib and Seaborn
Scatter plots in Bokeh
Preparation of line plot data
Line plots in matplotlib, Seaborn, and Bokeh
More on visualization
Preparation of scatter data
In this post, we will use matplotlib, seaborn, and bokeh. They are all external libraries need to be installed. To install them using pip, run the following command:
pip install matplotlib seaborn bokeh
For demonstration purposes, we will also use the MNIST handwritten digits dataset. We will load it from Tensorflow and run PCA algorithm on it. Hence we will also need to install Tensorflow and pandas:
pip install tensorflow pandas
The code afterwards will assume the following imports are executed:
# Importing from tensorflow and keras
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Reshape
from tensorflow.keras import utils
from tensorflow import dtypes, tensordot
from tensorflow import convert_to_tensor, linalg, transpose
# For math operations
import numpy as np
# For plotting with matplotlib
import matplotlib.pyplot as plt
# For plotting with seaborn
import seaborn as sns
# For plotting with bokeh
from bokeh.plotting import figure, show
from bokeh.models import Legend, LegendItem
# For pandas dataframe
import pandas as pd
We load the MNIST dataset from keras.datasets library. To keep things simple, we’ll retain only the subset of data containing the first three digits. We’ll also ignore the test set for now.
…
# load dataset
(x_train, train_labels), (_, _) = mnist.load_data()
# Choose only the digits 0, 1, 2
total_classes = 3
ind = np.where(train_labels < total_classes)
x_train, train_labels = x_train[ind], train_labels[ind]
# Shape of training data
total_examples, img_length, img_width = x_train.shape
# Print the statistics
print(‘Training data has ‘, total_examples, ‘images’)
print(‘Each image is of size ‘, img_length, ‘x’, img_width)
Training data has 18623 images
Each image is of size 28 x 28
Figures in matplotlib
Seaborn is indeed an add-on to matplotlib. Therefore you need to understand how matplotlib handles plots even if you’re using Seaborn.
Matplotlib calls its canvas the figure. You can divide the figure into several sections called subplots, so you can put two visualizations side-by-side.
As an example, let’s visualize the first 16 images of our MNIST dataset using matplotlib. We’ll create 2 rows and 8 columns using the subplots() function. The subplots() function will create the axes objects for each unit. Then we will display each image on each axes object using the imshow() method. Finally, the figure will be shown using the show() function.
img_per_row = 8
fig,ax = plt.subplots(nrows=2, ncols=img_per_row,
figsize=(18,4),
subplot_kw=dict(xticks=[], yticks=[]))
for row in [0, 1]:
for col in range(img_per_row):
ax[row, col].imshow(x_train[row*img_per_row + col].astype(‘int’))
plt.show()
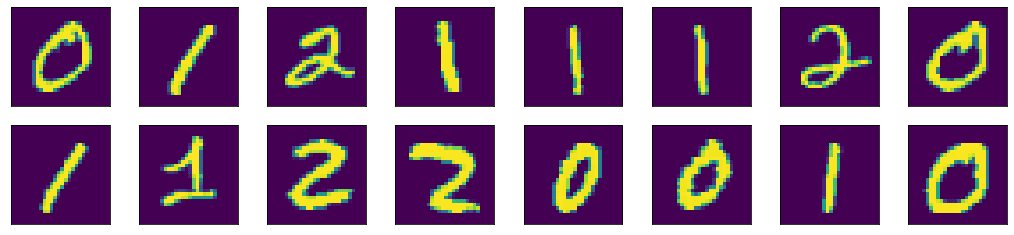{kind=link}
Here we can see a few properties of matplotlib. There is a default figure and default axes in matplotlib. There are a number of functions defined in matplotlib under the pyplot submodule for plotting on the default axes. If we want to plot on a particular axes, we can use the plotting function under the axes objects. The operations to manipulate a figure is procedural. Meaning, there is a data structure remembered internally by matplotlib and our operations will mutate it. The show() function simply display the result of a series of operations. Because of that, we can gradually fine-tune a lot of details on the figure. In the example above, we hid the “ticks” (i.e., the markers on axes) by setting xticks and yticks to empty lists.
Scatter plots in matplotlib and Seaborn
One of the common visualizations we use in machine learning projects is the scatter plot.
As an example, we apply PCA to the MNIST dataset and extract the first three components of each image. In the code below, we compute the eigenvectors and eigenvalues from the dataset, then projects the data of each image along the direction of the eigenvectors, and store the result in x_pca. For simplicity, we didn’t normalize the data to zero mean and unit variance before computing the eigenvectors. This omission does not affect our purpose of visualization.
…
# Convert the dataset into a 2D array of shape 18623 x 784
x = convert_to_tensor(np.reshape(x_train, (x_train.shape[0], -1)),
dtype=dtypes.float32)
# Eigen-decomposition from a 784 x 784 matrix
eigenvalues, eigenvectors = linalg.eigh(tensordot(transpose(x), x, axes=1))
# Print the three largest eigenvalues
print(‘3 largest eigenvalues: ‘, eigenvalues[-3:])
# Project the data to eigenvectors
x_pca = tensordot(x, eigenvectors, axes=1)
The eigenvalues printed are as follows:
3 largest eigenvalues: tf.Tensor([5.1999642e+09 1.1419439e+10 4.8231231e+10], shape=(3,), dtype=float32)
The array x_pca is in shape 18623 x 784. Let’s consider the last two columns as the x- and y-coordinates and make the point of each row in the plot. We can further color the point according to which digit it corresponds to.
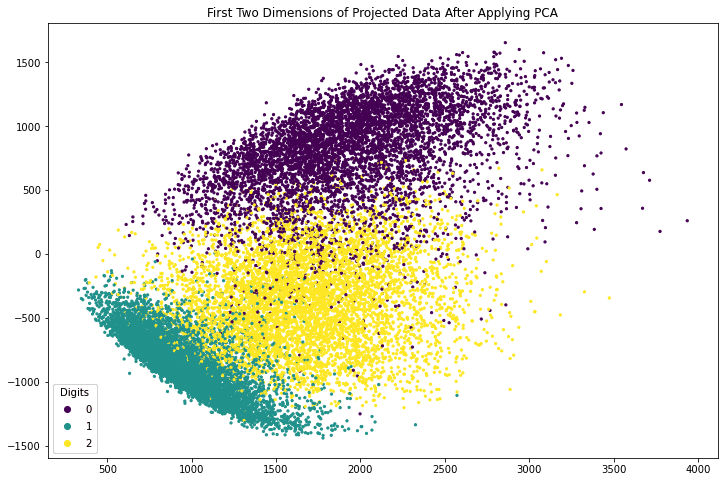
The following code generates a scatter plot using matplotlib. The plot is created using the axes object’s scatter() function, which takes the x- and y-coordinates as the first two argument. The c argument to scatter() method specifies a value that will become its color. The s argument specifies its size. The code also creates a legend and adds a title to the plot.
fig, ax = plt.subplots(figsize=(12, 8))
scatter = ax.scatter(x_pca[:, -1], x_pca[:, -2], c=train_labels, s=5)
legend_plt = ax.legend(*scatter.legend_elements(),
loc=”lower left”, title=”Digits”)
ax.add_artist(legend_plt)
plt.title(‘First Two Dimensions of Projected Data After Applying PCA’)
plt.show()
{kind=link}
Putting the above altogether, the following is the complete code to generate the 2D scatter plot using matplotlib:
from tensorflow.keras.datasets import mnist
from tensorflow import dtypes, tensordot
from tensorflow import convert_to_tensor, linalg, transpose
import numpy as np
import matplotlib.pyplot as plt
# Load dataset
(x_train, train_labels), (_, _) = mnist.load_data()
# Choose only the digits 0, 1, 2
total_classes = 3
ind = np.where(train_labels < total_classes)
x_train, train_labels = x_train[ind], train_labels[ind]
# Verify the shape of training data
total_examples, img_length, img_width = x_train.shape
print(‘Training data has ‘, total_examples, ‘images’)
print(‘Each image is of size ‘, img_length, ‘x’, img_width)
# Convert the dataset into a 2D array of shape 18623 x 784
x = convert_to_tensor(np.reshape(x_train, (x_train.shape[0], -1)),
dtype=dtypes.float32)
# Eigen-decomposition from a 784 x 784 matrix
eigenvalues, eigenvectors = linalg.eigh(tensordot(transpose(x), x, axes=1))
# Print the three largest eigenvalues
print(‘3 largest eigenvalues: ‘, eigenvalues[-3:])
# Project the data to eigenvectors
x_pca = tensordot(x, eigenvectors, axes=1)
# Create the plot
fig, ax = plt.subplots(figsize=(12, 8))
scatter = ax.scatter(x_pca[:, -1], x_pca[:, -2], c=train_labels, s=5)
legend_plt = ax.legend(*scatter.legend_elements(),
loc=”lower left”, title=”Digits”)
ax.add_artist(legend_plt)
plt.title(‘First Two Dimensions of Projected Data After Applying PCA’)
plt.show()
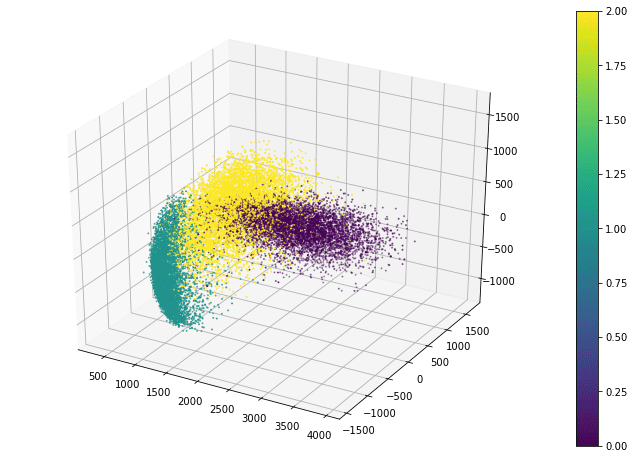
Matplotlib also allows a 3D scatter plot to be produced. To do so, you need to create an axes object with 3D projection first. Then the 3D scatter plot is created with the scatter3D() function, with the x-, y-, and z-coordinates as the first three arguments. The code below uses the data projected along the eigenvectors corresponding to the three largest eigenvalues. Instead of creating a legend, this code creates a colorbar.
fig = plt.figure(figsize=(12, 8))
ax = plt.axes(projection=’3d’)
plt_3d = ax.scatter3D(x_pca[:, -1], x_pca[:, -2], x_pca[:, -3], c=train_labels, s=1)
plt.colorbar(plt_3d)
plt.show()
{kind=link}
The scatter3D() function just puts the points onto the 3D space. Afterwards, we can still modify how the figure displays such as the label of each axis and the background color. But in 3D plots, one common tweak is the viewport, namely, the angle we look at the 3D space. Viewport is controlled by the view_init() function in the axes object:
ax.view_init(elev=30, azim=-60)
The viewport is controlled by the elevation angle (i.e., angle to the horizon plane) and the azimuthal angle (i.e., rotation on the horizon plane). By default, matplotlib uses 30 degree elevation and -60 degree azimuthal, as shown above.
Putting everything together, the following is the complete code to create the 3D scatter plot in matplotlib:
from tensorflow.keras.datasets import mnist
from tensorflow import dtypes, tensordot
from tensorflow import convert_to_tensor, linalg, transpose
import numpy as np
import matplotlib.pyplot as plt
# Load dataset
(x_train, train_labels), (_, _) = mnist.load_data()
# Choose only the digits 0, 1, 2
total_classes = 3
ind = np.where(train_labels < total_classes)
x_train, train_labels = x_train[ind], train_labels[ind]
# Verify the shape of training data
total_examples, img_length, img_width = x_train.shape
print(‘Training data has ‘, total_examples, ‘images’)
print(‘Each image is of size ‘, img_length, ‘x’, img_width)
# Convert the dataset into a 2D array of shape 18623 x 784
x = convert_to_tensor(np.reshape(x_train, (x_train.shape[0], -1)),
dtype=dtypes.float32)
# Eigen-decomposition from a 784 x 784 matrix
eigenvalues, eigenvectors = linalg.eigh(tensordot(transpose(x), x, axes=1))
# Print the three largest eigenvalues
print(‘3 largest eigenvalues: ‘, eigenvalues[-3:])
# Project the data to eigenvectors
x_pca = tensordot(x, eigenvectors, axes=1)
# Create the plot
fig = plt.figure(figsize=(12, 8))
ax = plt.axes(projection=’3d’)
ax.view_init(elev=30, azim=-60)
plt_3d = ax.scatter3D(x_pca[:, -1], x_pca[:, -2], x_pca[:, -3], c=train_labels, s=1)
plt.colorbar(plt_3d)
plt.show()
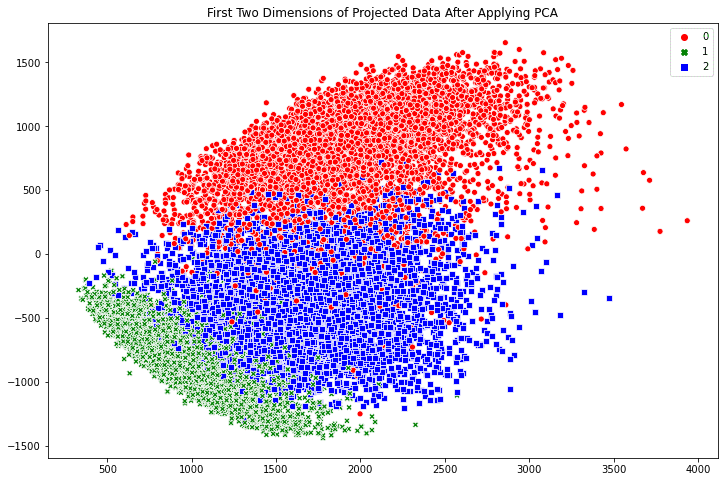
Creating scatter plots in Seaborn is similarly easy. The scatterplot() method automatically creates a legend and uses different symbols for different classes when plotting the points. By default, the plot is created on the “current axes” from matplotlib, unless the axes object is specified by the ax argument.
fig, ax = plt.subplots(figsize=(12, 8))
sns.scatterplot(x_pca[:, -1], x_pca[:, -2],
style=train_labels, hue=train_labels,
palette=[“red”, “green”, “blue”])
plt.title(‘First Two Dimensions of Projected Data After Applying PCA’)
plt.show()
{kind=link}
The benefit of Seaborn over matplotlib is two fold: First we have a polished default style. For example, if we compare the point style in the two scatter plots above, the Seaborn one has a border around the dot to prevent the many points smurged together. Indeed, if we run the following line before calling any matplotlib functions:
sns.set(style = “darkgrid”)
we can still use the matplotlib functions but get a better looking figure by using Seaborn’s style. Secondly, it is more convenient to use Seaborn if we are using pandas DataFrame to hold our data. As an example, let’s convert our MNIST data from a tensor into a pandas DataFrame:
df_mnist = pd.DataFrame(x_pca[:, -3:].numpy(), columns=[“pca3″,”pca2″,”pca1”])
df_mnist[“label”] = train_labels
print(df_mnist)
which the DataFrame looks like the following:
pca3 pca2 pca1 label
0 -537.730103 926.885254 1965.881592 0
1 167.375885 -947.360107 1070.359375 1
2 553.685425 -163.121826 1754.754272 2
3 -642.905579 -767.283020 1053.937988 1
4 -651.812988 -586.034424 662.468201 1
… … … … …
18618 415.358948 -645.245972 853.439209 1
18619 754.555786 7.873116 1897.690552 2
18620 -321.809357 665.038086 1840.480225 0
18621 643.843628 -85.524895 1113.795166 2
18622 94.964279 -549.570984 561.743042 1
[18623 rows x 4 columns]
Then, we can reproduce the Seaborn’s scatter plot with the following:
fig, ax = plt.subplots(figsize=(12, 8))
sns.scatterplot(data=df_mnist, x=”pca1″, y=”pca2″,
style=”label”, hue=”label”,
palette=[“red”, “green”, “blue”])
plt.title(‘First Two Dimensions of Projected Data After Applying PCA’)
plt.show()
which we do not pass in arrays as coordinates to the scatterplot() function, but column names to the data argument instead.
The following is the complete code to generate a scatter plot using Seaborn with the data stored in pandas:
from tensorflow.keras.datasets import mnist
from tensorflow import dtypes, tensordot
from tensorflow import convert_to_tensor, linalg, transpose
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Load dataset
(x_train, train_labels), (_, _) = mnist.load_data()
# Choose only the digits 0, 1, 2
total_classes = 3
ind = np.where(train_labels < total_classes)
x_train, train_labels = x_train[ind], train_labels[ind]
# Verify the shape of training data
total_examples, img_length, img_width = x_train.shape
print(‘Training data has ‘, total_examples, ‘images’)
print(‘Each image is of size ‘, img_length, ‘x’, img_width)
# Convert the dataset into a 2D array of shape 18623 x 784
x = convert_to_tensor(np.reshape(x_train, (x_train.shape[0], -1)),
dtype=dtypes.float32)
# Eigen-decomposition from a 784 x 784 matrix
eigenvalues, eigenvectors = linalg.eigh(tensordot(transpose(x), x, axes=1))
# Print the three largest eigenvalues
print(‘3 largest eigenvalues: ‘, eigenvalues[-3:])
# Project the data to eigenvectors
x_pca = tensordot(x, eigenvectors, axes=1)
# Making pandas DataFrame
df_mnist = pd.DataFrame(x_pca[:, -3:].numpy(), columns=[“pca3″,”pca2″,”pca1”])
df_mnist[“label”] = train_labels
# Create the plot
fig, ax = plt.subplots(figsize=(12, 8))
sns.scatterplot(data=df_mnist, x=”pca1″, y=”pca2″,
style=”label”, hue=”label”,
palette=[“red”, “green”, “blue”])
plt.title(‘First Two Dimensions of Projected Data After Applying PCA’)
plt.show()
Seaborn as a wrapper to some matplotlib functions, is not replacing matplotlib entirely. Plotting in 3D, for example, are not supported by Seaborn and we still need to resort to matplotlib functions for such purposes.
Scatter plots in Bokeh
The plots created by matplotlib and Seaborn are static images. If you need to zoom in, pan, or toggle the display of some part of the plot, you should use Bokeh instead.
Creating scatter plots in Bokeh is also easy. The following code generates a scatter plot and adds a legend. The show() method from Bokeh library opens a new browser window to display the image. You can interact with the plot by scaling, zooming, scrolling and more options that are shown in the toolbar next to the rendered plot. You can also hide part of the scatter by clicking on the legend.
colormap = {0: “red”, 1:”green”, 2:”blue”}
my_scatter = figure(title=”First Two Dimensions of Projected Data After Applying PCA”,
x_axis_label=”Dimension 1″,
y_axis_label=”Dimension 2″)
for digit in [0, 1, 2]:
selection = x_pca[train_labels == digit]
my_scatter.scatter(selection[:,-1].numpy(), selection[:,-2].numpy(),
color=colormap[digit], size=5,
legend_label=”Digit “+str(digit))
my_scatter.legend.click_policy = “hide”
show(my_scatter)
Bokeh will produce the plot in HTML with Javascript. All your actions to control the plot are handled by some Javascript functions. Its output would looks like the following:
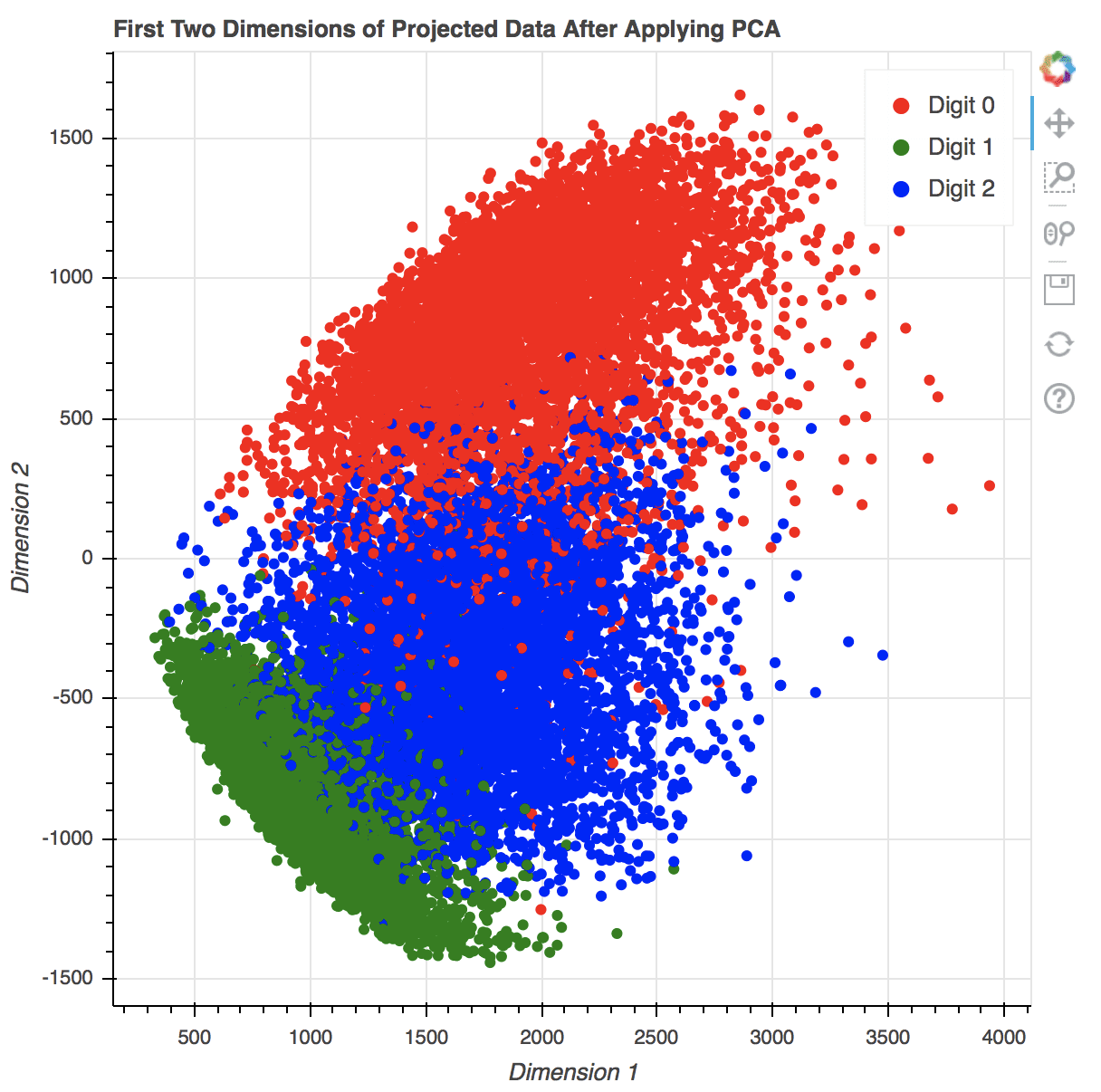{kind=link}
2D scatter plot generated using Bokeh in a new browser window. Note the various options on the right for interacting with the plot.
The following is the complete code to generate the above scatter plot using Bokeh:
from tensorflow.keras.datasets import mnist
from tensorflow import dtypes, tensordot
from tensorflow import convert_to_tensor, linalg, transpose
import numpy as np
from bokeh.plotting import figure, show
# Load dataset
(x_train, train_labels), (_, _) = mnist.load_data()
# Choose only the digits 0, 1, 2
total_classes = 3
ind = np.where(train_labels < total_classes)
x_train, train_labels = x_train[ind], train_labels[ind]
# Verify the shape of training data
total_examples, img_length, img_width = x_train.shape
print(‘Training data has ‘, total_examples, ‘images’)
print(‘Each image is of size ‘, img_length, ‘x’, img_width)
# Convert the dataset into a 2D array of shape 18623 x 784
x = convert_to_tensor(np.reshape(x_train, (x_train.shape[0], -1)),
dtype=dtypes.float32)
# Eigen-decomposition from a 784 x 784 matrix
eigenvalues, eigenvectors = linalg.eigh(tensordot(transpose(x), x, axes=1))
# Print the three largest eigenvalues
print(‘3 largest eigenvalues: ‘, eigenvalues[-3:])
# Project the data to eigenvectors
x_pca = tensordot(x, eigenvectors, axes=1)
# Create scatter plot in Bokeh
colormap = {0: “red”, 1:”green”, 2:”blue”}
my_scatter = figure(title=”First Two Dimensions of Projected Data After Applying PCA”,
x_axis_label=”Dimension 1″,
y_axis_label=”Dimension 2″)
for digit in [0, 1, 2]:
selection = x_pca[train_labels == digit]
my_scatter.scatter(selection[:,-1].numpy(), selection[:,-2].numpy(),
color=colormap[digit], size=5, alpha=0.5,
legend_label=”Digit “+str(digit))
my_scatter.legend.click_policy = “hide”
show(my_scatter)
If you are rendering the Bokeh plot in Jupyter notebook, you may see the plot is produced in a new browser window. To put the plot in the Jupyter notebook, you need to tell Bokeh that you are under the notebook environment by running the following before the Bokeh functions:
from bokeh.io import output_notebook
output_notebook()
Also note that we create the scatter plot of the three digit in a loop, one digit at a time. This is required to make the legend interactive, since each time scatter() is called, a new object is created. If we use create all scatter points at once, like the following, clicking on the legend will hide and show everything instead of only the points of one of the digits.
colormap = {0: “red”, 1:”green”, 2:”blue”}
colors = [colormap[i] for i in train_labels]
my_scatter = figure(title=”First Two Dimensions of Projected Data After Applying PCA”,
x_axis_label=”Dimension 1″, y_axis_label=”Dimension 2″)
scatter_obj = my_scatter.scatter(x_pca[:, -1].numpy(), x_pca[:, -2].numpy(), color=colors, size=5)
legend = Legend(items=[
LegendItem(label=”Digit 0″, renderers=[scatter_obj], index=0),
LegendItem(label=”Digit 1″, renderers=[scatter_obj], index=1),
LegendItem(label=”Digit 2″, renderers=[scatter_obj], index=2),
])
my_scatter.add_layout(legend)
my_scatter.legend.click_policy = “hide”
show(my_scatter)
Preparation of line plot data
Before we move on to show how we can visualize line plot data, let’s generate some data for illustration. Below is a simple classifier using the Keras library, which we train it to learn the handwritten digit classification. The history object returned by the fit() method is a dictionary that contains all the learning history of the training stage. For simplicity, we’ll train the model using only 10 epochs.
epochs = 10
y_train = utils.to_categorical(train_labels)
input_dim = img_length*img_width
# Create a Sequential model
model = Sequential()
# First layer for reshaping input images from 2D to 1D
model.add(Reshape((input_dim, ), input_shape=(img_length, img_width)))
# Dense layer of 8 neurons
model.add(Dense(8, activation=’relu’))
# Output layer
model.add(Dense(total_classes, activation=’softmax’))
# Compile model
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
history = model.fit(x_train, y_train, validation_split=0.33, epochs=epochs, batch_size=10, verbose=0)
print(‘Learning history: ‘, history.history)
The code above will produce a dictionary with keys loss, accuracy, val_loss, and val_accuracy, as follows:
Learning history: {‘loss’: [0.5362154245376587, 0.08184114843606949, …],
‘accuracy’: [0.9426144361495972, 0.9763565063476562, …],
‘val_loss’: [0.09874073415994644, 0.07835448533296585, …],
‘val_accuracy’: [0.9716889262199402, 0.9788480401039124, …]}
Line plots in matplotlib, Seaborn, and Bokeh
Let’s look at various options for visualizing the learning history obtained from training our classifier.
Creating a multi-line plots in matplotlib is as trivial as following. We obtain the list of values of the training and validation accuracies from the history, and by default, matplotlib will consider that as sequential data (i.e., x-coordinates are integers counting from 0 onwards).
plt.plot(history.history[‘accuracy’], label=”Training accuracy”)
plt.plot(history.history[‘val_accuracy’], label=”Validation accuracy”)
plt.title(‘Training and validation accuracy’)
plt.xlabel(‘Epochs’)
plt.ylabel(‘Accuracy’)
plt.legend()
plt.show()
{kind=link}
The complete code for creating the multi-line plot is as follows:
from tensorflow.keras.datasets import mnist
from tensorflow.keras import utils
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Reshape
import numpy as np
import matplotlib.pyplot as plt
# Load dataset
(x_train, train_labels), (_, _) = mnist.load_data()
# Choose only the digits 0, 1, 2
total_classes = 3
ind = np.where(train_labels < total_classes)
x_train, train_labels = x_train[ind], train_labels[ind]
# Verify the shape of training data
total_examples, img_length, img_width = x_train.shape
print(‘Training data has ‘, total_examples, ‘images’)
print(‘Each image is of size ‘, img_length, ‘x’, img_width)
# Prepare for classifier network
epochs = 10
y_train = utils.to_categorical(train_labels)
input_dim = img_length*img_width
# Create a Sequential model
model = Sequential()
# First layer for reshaping input images from 2D to 1D
model.add(Reshape((input_dim, ), input_shape=(img_length, img_width)))
# Dense layer of 8 neurons
model.add(Dense(8, activation=’relu’))
# Output layer
model.add(Dense(total_classes, activation=’softmax’))
# Compile model
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
history = model.fit(x_train, y_train, validation_split=0.33, epochs=epochs, batch_size=10, verbose=0)
print(‘Learning history: ‘, history.history)
# Plot accuracy in Matplotlib
plt.plot(history.history[‘accuracy’], label=”Training accuracy”)
plt.plot(history.history[‘val_accuracy’], label=”Validation accuracy”)
plt.title(‘Training and validation accuracy’)
plt.xlabel(‘Epochs’)
plt.ylabel(‘Accuracy’)
plt.legend()
plt.show()
Similarly, we can do the same in Seaborn. As we have seen in the case of scatter plot, we can pass in the data to Seaborn as a series of values explicitly, or through a pandas DataFrame. Let’s plot the training loss and validation loss in the following using a pandas DataFrame:
# Create pandas DataFrame
df_history = pd.DataFrame(history.history)
print(df_history)
# Plot using Seaborn
my_plot = sns.lineplot(data=df_history[[“loss”,”val_loss”]])
my_plot.set_xlabel(‘Epochs’)
my_plot.set_ylabel(‘Loss’)
plt.legend(labels=[“Training”, “Validation”])
plt.title(‘Training and Validation Loss’)
plt.show()
It will print the following table, which is the DataFrame we created from the history:
loss accuracy val_loss val_accuracy
0 0.536215 0.942614 0.098741 0.971689
1 0.081841 0.976357 0.078354 0.978848
2 0.064002 0.978841 0.080637 0.972991
3 0.055695 0.981726 0.064659 0.979987
4 0.054693 0.984371 0.070817 0.983729
5 0.053512 0.985173 0.069099 0.977709
6 0.053916 0.983089 0.068139 0.979662
7 0.048681 0.985093 0.064914 0.977709
8 0.052084 0.982929 0.080508 0.971363
9 0.040484 0.983890 0.111380 0.982590
And the plot it generated is as follows:
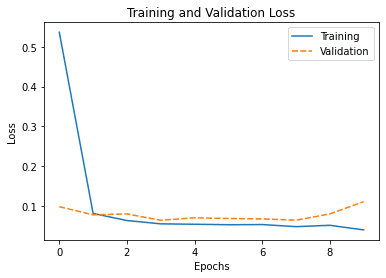{kind=link}
By default, Seaborn will understand the column labels from the DataFrame and use it as legend. In the above, we provide a new label for each plot. Moreover, the x-axis of the line plot is taken from the index of the DataFrame by default, which is integer running from 0 to 9 in our case as we can see above.
The complete code of producing the plot in Seaborn is as follows:
from tensorflow.keras.datasets import mnist
from tensorflow.keras import utils
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Reshape
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Load dataset
(x_train, train_labels), (_, _) = mnist.load_data()
# Choose only the digits 0, 1, 2
total_classes = 3
ind = np.where(train_labels < total_classes)
x_train, train_labels = x_train[ind], train_labels[ind]
# Verify the shape of training data
total_examples, img_length, img_width = x_train.shape
print(‘Training data has ‘, total_examples, ‘images’)
print(‘Each image is of size ‘, img_length, ‘x’, img_width)
# Prepare for classifier network
epochs = 10
y_train = utils.to_categorical(train_labels)
input_dim = img_length*img_width
# Create a Sequential model
model = Sequential()
# First layer for reshaping input images from 2D to 1D
model.add(Reshape((input_dim, ), input_shape=(img_length, img_width)))
# Dense layer of 8 neurons
model.add(Dense(8, activation=’relu’))
# Output layer
model.add(Dense(total_classes, activation=’softmax’))
# Compile model
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
history = model.fit(x_train, y_train, validation_split=0.33, epochs=epochs, batch_size=10, verbose=0)
# Prepare pandas DataFrame
df_history = pd.DataFrame(history.history)
print(df_history)
# Plot loss in seaborn
my_plot = sns.lineplot(data=df_history[[“loss”,”val_loss”]])
my_plot.set_xlabel(‘Epochs’)
my_plot.set_ylabel(‘Loss’)
plt.legend(labels=[“Training”, “Validation”])
plt.title(‘Training and Validation Loss’)
plt.show()
As you can expect, we can also provide arguments x and y together with data to our call to lineplot() as in our example of Seaborn scatter plot above if we want to control the x- and y-coordinates precisely.
Bokeh can also generate multi-line plots, as illustrated in the code below. As we saw in the scatter plot example, we need to provide the x- and y-coordinates explicitly and do one line at a time. Again, the show() method opens a new browser window to display the plot and you can interact with it.
p = figure(title=”Training and validation accuracy”,
x_axis_label=”Epochs”, y_axis_label=”Accuracy”)
epochs_array = np.arange(epochs)
p.line(epochs_array, df_history[‘accuracy’], legend_label=”Training”,
color=”blue”, line_width=2)
p.line(epochs_array, df_history[‘val_accuracy’], legend_label=”Validation”,
color=”green”)
p.legend.click_policy = “hide”
p.legend.location = ‘bottom_right’
show(p)
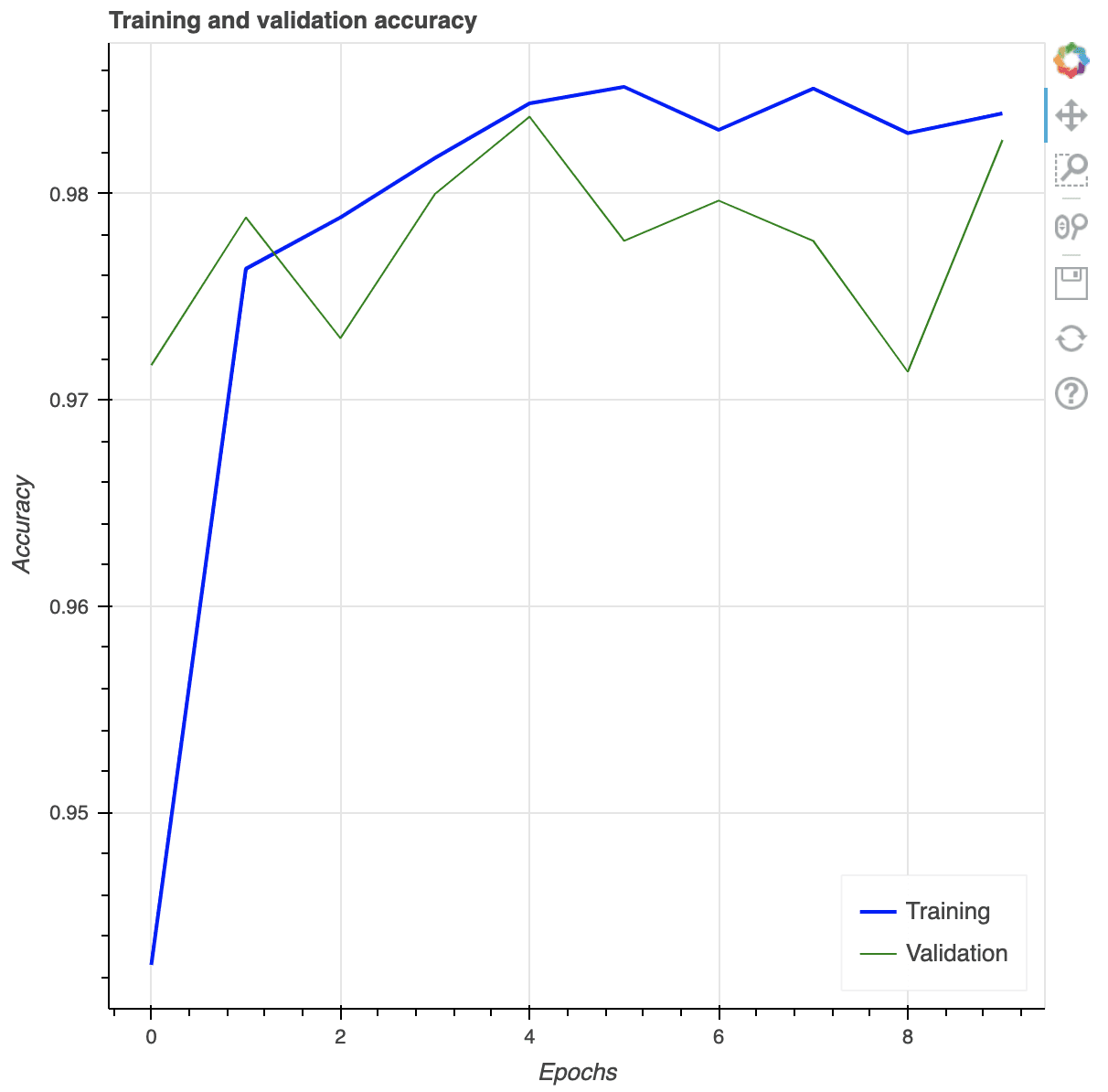{kind=link}
Multi-line plot using Bokeh. Note the options for user interaction shown on the toolbar on the right.
The complete code for making the Bokeh plot is as follows:
from tensorflow.keras.datasets import mnist
from tensorflow.keras import utils
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Reshape
import numpy as np
import pandas as pd
from bokeh.plotting import figure, show
# Load dataset
(x_train, train_labels), (_, _) = mnist.load_data()
# Choose only the digits 0, 1, 2
total_classes = 3
ind = np.where(train_labels < total_classes)
x_train, train_labels = x_train[ind], train_labels[ind]
# Verify the shape of training data
total_examples, img_length, img_width = x_train.shape
print(‘Training data has ‘, total_examples, ‘images’)
print(‘Each image is of size ‘, img_length, ‘x’, img_width)
# Prepare for classifier network
epochs = 10
y_train = utils.to_categorical(train_labels)
input_dim = img_length*img_width
# Create a Sequential model
model = Sequential()
# First layer for reshaping input images from 2D to 1D
model.add(Reshape((input_dim, ), input_shape=(img_length, img_width)))
# Dense layer of 8 neurons
model.add(Dense(8, activation=’relu’))
# Output layer
model.add(Dense(total_classes, activation=’softmax’))
# Compile model
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
history = model.fit(x_train, y_train, validation_split=0.33, epochs=epochs, batch_size=10, verbose=0)
# Prepare pandas DataFrame
df_history = pd.DataFrame(history.history)
print(df_history)
# Plot accuracy in Bokeh
p = figure(title=”Training and validation accuracy”,
x_axis_label=”Epochs”, y_axis_label=”Accuracy”)
epochs_array = np.arange(epochs)
p.line(epochs_array, df_history[‘accuracy’], legend_label=”Training”,
color=”blue”, line_width=2)
p.line(epochs_array, df_history[‘val_accuracy’], legend_label=”Validation”,
color=”green”)
p.legend.click_policy = “hide”
p.legend.location = ‘bottom_right’
show(p)
More on visualization
Each of the tools we introduced above has a lot more functions for us to control the bits and pieces of the details in the visualization. It is important to search on their respective documentation to find the ways you can polish your plots. It is equally important to check out the example code in their documentation to learn how you can possibly make your visualization better.
Without providing too much detail, here are some ideas that you may want to add to your visualization:
add auxiliary lines, such as to mark the training and validation dataset on a time series data. The axvline() function from matplotlib can make a vertical line on plots for this purpose
add annotations, such as arrows and text labels to identify key points on the plot. See the annotate() function in matplotlib axes objects.
control the transparency level in case of overlapping graphic elements. All plotting functions we introduced above allows an alpha argument to provide a value between 0 and 1 for how much we can see through the graph.
if the data is better illustrated this way, we may show some of the axes in log scale. It is usually called the log plot or semilog plot.
Before we conclude this post, the following is an example that we can create a side-by-side visualization in matplotlib, which one of them is created using Seaborn:
from tensorflow.keras.datasets import mnist
from tensorflow.keras import utils
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Reshape
from tensorflow import dtypes, tensordot
from tensorflow import convert_to_tensor, linalg, transpose
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Load dataset
(x_train, train_labels), (_, _) = mnist.load_data()
# Choose only the digits 0, 1, 2
total_classes = 3
ind = np.where(train_labels < total_classes)
x_train, train_labels = x_train[ind], train_labels[ind]
# Verify the shape of training data
total_examples, img_length, img_width = x_train.shape
print(‘Training data has ‘, total_examples, ‘images’)
print(‘Each image is of size ‘, img_length, ‘x’, img_width)
# Convert the dataset into a 2D array of shape 18623 x 784
x = convert_to_tensor(np.reshape(x_train, (x_train.shape[0], -1)),
dtype=dtypes.float32)
# Eigen-decomposition from a 784 x 784 matrix
eigenvalues, eigenvectors = linalg.eigh(tensordot(transpose(x), x, axes=1))
# Print the three largest eigenvalues
print(‘3 largest eigenvalues: ‘, eigenvalues[-3:])
# Project the data to eigenvectors
x_pca = tensordot(x, eigenvectors, axes=1)
# Prepare for classifier network
epochs = 10
y_train = utils.to_categorical(train_labels)
input_dim = img_length*img_width
# Create a Sequential model
model = Sequential()
# First layer for reshaping input images from 2D to 1D
model.add(Reshape((input_dim, ), input_shape=(img_length, img_width)))
# Dense layer of 8 neurons
model.add(Dense(8, activation=’relu’))
# Output layer
model.add(Dense(total_classes, activation=’softmax’))
# Compile model
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
history = model.fit(x_train, y_train, validation_split=0.33, epochs=epochs, batch_size=10, verbose=0)
# Prepare pandas DataFrame
df_history = pd.DataFrame(history.history)
print(df_history)
# Plot side-by-side
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(15,6))
# left plot
scatter = ax[0].scatter(x_pca[:, -1], x_pca[:, -2], c=train_labels, s=5)
legend_plt = ax[0].legend(*scatter.legend_elements(),
loc=”lower left”, title=”Digits”)
ax[0].add_artist(legend_plt)
ax[0].set_title(‘First Two Dimensions of Projected Data After Applying PCA’)
# right plot
my_plot = sns.lineplot(data=df_history[[“loss”,”val_loss”]], ax=ax[1])
my_plot.set_xlabel(‘Epochs’)
my_plot.set_ylabel(‘Loss’)
ax[1].legend(labels=[“Training”, “Validation”])
ax[1].set_title(‘Training and Validation Loss’)
plt.show()
Side-by-side visualization created using matplotlib and Seaborn
The equivalent in Bokeh is to create each subplot separately and then specify the layout when we show it:
from tensorflow.keras.datasets import mnist
from tensorflow.keras import utils
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Reshape
from tensorflow import dtypes, tensordot
from tensorflow import convert_to_tensor, linalg, transpose
import numpy as np
import pandas as pd
from bokeh.plotting import figure, show
from bokeh.layouts import row
# Load dataset
(x_train, train_labels), (_, _) = mnist.load_data()
# Choose only the digits 0, 1, 2
total_classes = 3
ind = np.where(train_labels < total_classes)
x_train, train_labels = x_train[ind], train_labels[ind]
# Verify the shape of training data
total_examples, img_length, img_width = x_train.shape
print(‘Training data has ‘, total_examples, ‘images’)
print(‘Each image is of size ‘, img_length, ‘x’, img_width)
# Convert the dataset into a 2D array of shape 18623 x 784
x = convert_to_tensor(np.reshape(x_train, (x_train.shape[0], -1)),
dtype=dtypes.float32)
# Eigen-decomposition from a 784 x 784 matrix
eigenvalues, eigenvectors = linalg.eigh(tensordot(transpose(x), x, axes=1))
# Print the three largest eigenvalues
print(‘3 largest eigenvalues: ‘, eigenvalues[-3:])
# Project the data to eigenvectors
x_pca = tensordot(x, eigenvectors, axes=1)
# Prepare for classifier network
epochs = 10
y_train = utils.to_categorical(train_labels)
input_dim = img_length*img_width
# Create a Sequential model
model = Sequential()
# First layer for reshaping input images from 2D to 1D
model.add(Reshape((input_dim, ), input_shape=(img_length, img_width)))
# Dense layer of 8 neurons
model.add(Dense(8, activation=’relu’))
# Output layer
model.add(Dense(total_classes, activation=’softmax’))
# Compile model
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
history = model.fit(x_train, y_train, validation_split=0.33, epochs=epochs, batch_size=10, verbose=0)
# Prepare pandas DataFrame
df_history = pd.DataFrame(history.history)
print(df_history)
# Create scatter plot in Bokeh
colormap = {0: “red”, 1:”green”, 2:”blue”}
my_scatter = figure(title=”First Two Dimensions of Projected Data After Applying PCA”,
x_axis_label=”Dimension 1″,
y_axis_label=”Dimension 2″,
width=500, height=400)
for digit in [0, 1, 2]:
selection = x_pca[train_labels == digit]
my_scatter.scatter(selection[:,-1].numpy(), selection[:,-2].numpy(),
color=colormap[digit], size=5, alpha=0.5,
legend_label=”Digit “+str(digit))
my_scatter.legend.click_policy = “hide”
# Plot accuracy in Bokeh
p = figure(title=”Training and validation accuracy”,
x_axis_label=”Epochs”, y_axis_label=”Accuracy”,
width=500, height=400)
epochs_array = np.arange(epochs)
p.line(epochs_array, df_history[‘accuracy’], legend_label=”Training”,
color=”blue”, line_width=2)
p.line(epochs_array, df_history[‘val_accuracy’], legend_label=”Validation”,
color=”green”)
p.legend.click_policy = “hide”
p.legend.location = ‘bottom_right’
show(row(my_scatter, p))
Side-by-side plot created in Bokeh
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
Think Python: How to Think Like a Computer Scientist by Allen B. Downey
Programming in Python 3: A Complete Introduction to the Python Language by Mark Summerfield
Python Programming: An Introduction to Computer Science by John Zelle
Python for Data Analysis, 2nd edition, by Wes McKinney
Articles
A Gentle Introduction to Data Visualization Methods in Python
How to use Seaborn Data Visualization for Machine Learning
API Reference
matplotlib.pyplot.scatter
matplotlib.pyplot.plot
seaborn.scatterplot
seaborn.lineplot
Bokeh plotting with basic glyphs
Bokeh scatter plots
Bokeh line charts
Summary
In this tutorial, you discovered various options for data visualization in Python.
Specifically, you learned:
How to create subplots in different rows and columns
How to render images using Matplotlib
How to generate 2D and 3D scatter plots using Matplotlib
How to create 2D plots using seaborn and Bokeh
How to create multi-line plots using Matplotlib, Seaborn and Bokeh
Do you have any questions about data visualization options discussed in this post? Ask your questions in the comments below and I will do my best to answer.
The post Data Visualization in Python with matplotlib, Seaborn and Bokeh appeared first on Machine Learning Mastery.
Read MoreMachine Learning Mastery