

{kind=link}
The built-in Amazon SageMaker XGBoost algorithm provides a managed container to run the popular XGBoost machine learning (ML) framework, with added convenience of supporting advanced training or inference features like distributed training, dataset sharding for large-scale datasets, A/B model testing, or multi-model inference endpoints. You can also extend this powerful algorithm to accommodate different requirements.
Packaging the code and dependencies in a single container is a convenient and robust approach for long-term code maintenance, reproducibility, and auditing purposes. Modifying the container directly follows the base container faithfully and avoids duplicating existing functions already supported by the base container. In this post, we review the inner workings of the SageMaker XGBoost algorithm container and provide pragmatic scripts to directly customize the container.
SageMaker XGBoost container structure
The SageMaker built-in XGBoost algorithm is packaged as a stand-alone container, available on GitHub, and can be extended under the developer-friendly Apache 2.0 open-source license. The container packages the open-source XGBoost algorithm and ancillary tools to run the algorithm in the SageMaker environment integrated with other AWS Cloud services. This allows you to train XGBoost models on a variety of data sources, make batch predictions on offline data, or host an inference endpoint in a real-time pipeline.
The container supports training and inference operations with different entry points. For inference mode, the entry can be found in the main function in the serving.py script. For real-time inference serving, the container runs a Flask-based web server that when invoked, receives an HTTP-encoded request containing the data, decodes the data into the XGBoost’s DMatrix format, loads the model, and returns an HTTP-encoded response back. These methods are encapsulated under the ScoringService class, which can also be customized through the script mode to a great extent (see the Appendix below).
The entry point for training mode (algorithm mode) is the main function in the training.py. The main function sets up the training environment and calls the training job function. It’s flexible enough to allow for distributed or single-node training, or utilities like cross validation. The heart of the training process can be found in the train_job function.
Docker files packaging the container can be found in the GitHub repo. Note that the container is built in two steps: a base container is built first, followed by the final container on top.
Solution overview
You can modify and rebuild the container through the source code. However, this involves collecting and rebuilding all dependencies and packages from scratch. In this post, we discuss a more straightforward approach that modifies the container on top of the already-built and publicly-available SageMaker XGBoost algorithm container image directly.
In this approach, we pull a copy of the public SageMaker XGBoost image, modify the scripts or add packages, and rebuild the container on top. The modified container can be stored in a private repository. This way, we avoid rebuilding intermediary dependencies and instead build directly on top of the already-built libraries packaged in the official container.
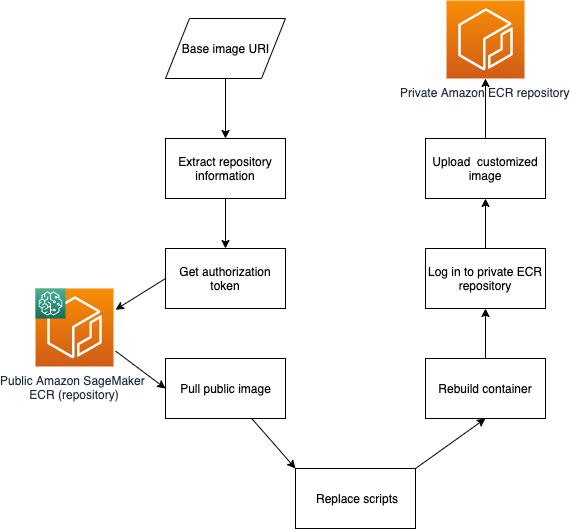
The following figure shows an overview of the script used to pull the public base image, modify and rebuild the image, and upload it to a private Amazon Elastic Container Registry (Amazon ECR) repository. The bash script in the accompanying code of this post performs all the workflow steps shown in the diagram. The accompanying notebook shows an example where the URI of a specific version of the SageMaker XGBoost algorithm is first retrieved and passed to the bash script, which replaces two of the Python scripts in the image, rebuilds it, and pushes the modified image to a private Amazon ECR repository. You can modify the accompanying code to suit your needs.
{kind=link}
Prerequisites
The GitHub repository contains the code accompanying this post. You can run the sample notebook in your AWS account, or use the provided AWS CloudFormation stack to deploy the notebook using a SageMaker notebook. You need the following prerequisites:
An AWS account.
Necessary permissions to run SageMaker batch transform and training jobs, and Amazon ECR privileges. The CloudFormation template creates sample AWS Identity and Access Management (IAM) roles.
Deploy the solution
To create your solution resources using AWS CloudFormation, choose Launch Stack:
The stack deploys a SageMaker notebook preconfigured to clone the GitHub repository. The walkthrough notebook includes the steps to pull the public SageMaker XGBoost image for a given version, modify it, and push the custom container to a private Amazon ECR repository. The notebook uses the public Abalone dataset as a sample, trains a model using the SageMaker XGBoost built-in training mode, and reuses this model in the custom image to perform batch transform jobs that produce inference together with SHAP values.
Conclusion
SageMaker built-in algorithms provide a variety of features and functionalities, and can be extended further under the Apache 2.0 open-source license. In this post, we reviewed how to extend the production built-in container for the SageMaker XGBoost algorithm to meet production requirements like backward code and API compatibility.
The sample notebook and helper scripts provide a convenient starting point to customize SageMaker XGBoost container image the way you would like it. Give it a try!
Appendix: Script mode
Script mode provides a way to modify many SageMaker built-in algorithms by providing an interface to replace the functions responsible for transforming the inputs and loading the model. Script mode isn’t as flexible as directly modifying the container, but it provides a completely Python-based route to customize the built-in algorithm with no need to work directly with Docker.
In script mode, a user-module is provided to customize data decoding, loading of the model, and making predictions. The user module can define a transformer_fn that handles all aspects of processing the request to preparing the response. Or instead of defining transformer_fn, you can provide custom methods model_fn, input_fn, predict_fn, and output_fn individually to customize loading the model and decoding and preparing the input for prediction. For a more thorough overview of script mode, see Bring Your Own Model with SageMaker Script Mode.
About the Authors
Peyman Razaghi is a Data Scientist at AWS. He holds a PhD in information theory from the University of Toronto and was a post-doctoral research scientist at the University of Southern California (USC), Los Angeles. Before joining AWS, Peyman was a staff systems engineer at Qualcomm contributing to a number of notable international telecommunication standards. He has authored several scientific research articles peer-reviewed in statistics and systems-engineering area, and enjoys parenting and road cycling outside work.
Read MoreAWS Machine Learning Blog