

{kind=link}
AWS provides three ways to create highly available SQL Server databases. Most customers use the single-click Multi-AZ Amazon Relational Database Service (Amazon RDS) for SQL Server deployment. With Amazon RDS for SQL Server, you can enable the Multi-AZ option, which replicates data synchronously across different Availability Zones without the need to set up high availability manually.
If Amazon RDS isn’t suitable for your environment, you can set up high availability using either SQL Server Always On failover cluster instances (FCIs) or Always On availability groups on Amazon Elastic Compute Cloud (Amazon EC2). We recommend setting up high availability at the SQL Server instance level using FCIs on Amazon EC2 by using Amazon FSx for Windows File Server as the Multi-AZ managed continuously available (CA) shared storage. SQL Server FCIs on Amazon EC2 with Amazon FSx costs 50–60% less compared to setting up replicas for all user databases using Always On availability groups.
However, we recognize that there could be situations where FCIs alone may not meet all your business needs. For example, you may prefer to have a dedicated instance for read-heavy reporting needs that doesn’t overload the shared storage for FCIs. In this post, we walk you through a hybrid approach involving both FCI and availability groups to meet such needs by setting up a standalone SQL Server node as a database availability group replica of a SQL Server FCI serving production.
Solution overview
The solution assumes that you have a SQL Server FCI with a primary and secondary node configured and running on Amazon EC2. We configure a third SQL Server node as an additional node in an existing Windows failover cluster and create a new availability group. Next, we configure an availability replica of one or more databases hosted on the FCI, which replicates the database to the third SQL node.
The databases configured to replicate using the availability group maintain an individual copy of database files in the storage system attached to the third node. An overview of the architecture is depicted in the following diagram.
{kind=link}
In this example, we use FSx for Windows File Server as shared storage for SQL Server FCI deployment and File Share Majority witness. Amazon FSx automatically handles failover, simplifying shared storage to host database deployments while reducing cost.
The SQL Server FCI uses Windows Server failover clustering, which requires more than half the nodes to be running to maintain high availability. It uses quorum to maintain the availability and is designed to prevent split-brain scenarios, which can happen when the nodes can’t communicate with each other. In this architecture, we have configured a cluster quorum using File Share Majority on FSx for Windows File Server as quorum witness to constitute the majority of the cluster to remain online. A File Share Majority witness works over SMB file share and doesn’t require a clustered disk, which is generally required for Disk Majority quorum. Also, a file share witness doesn’t store a copy of the cluster database, therefore you have fewer security concerns. For more details on available quorum types, see Quorum configuration choices.
If you’re unsure how to deploy a SQL Server FCI or want to automate the deployment on AWS using FSx for Window File Server, you can use the AWS Launch Wizard. AWS Launch Wizard provides a simple console-based provisioning experience to deploy a SQL Server FCI high availability environment. Alternatively, you can use AWS Quick Start.
Configure a SQL Server availability group with an FCI
Presuming you have the SQL FCI with primary and secondary nodes configured using FSx for Windows File Server, you can start by connecting to the third EC2 instance to use as the SQL availability group node. For this post, I refer to the SQL Server nodes as Node 1 (FCI), Node 2 (FCI), and Node 3 (standalone availability group). Complete the following steps to configure the SQL standalone availability group node and replicate your databases.
Configure SQL Server
Install SQL Server as standalone on Node 3, after which you can install the Windows Failover Cluster feature.
Configure Always On high availability
You must enable Always On high availability on SQL Server FCI instances as well as standalone instances. If you haven’t configured it yet, complete the following steps to enable Always On HA on Node 3 (standalone availability group) and the FCI owner node. To check which FCI node is owner or primary, complete the following:
Go to Failover Cluster Manager.
Choose the cluster name.
Note the node name under Current Host Server.
Now you can enable Always On HA:
Go to SQL Server Configuration Manager.
Choose SQL Server under SQL Server Services.
Choose Properties and on the AlwaysOn High Availability tab, select Enable.
Restart SQL Server for the changes to take effect. Restarting the standalone SQL node is straightforward. However, to restart FCI nodes, you need to follow certain steps for the changes to take effect. The inactive or secondary FCI node replicates the Always On HA setting from the owner or primary node. Complete the following steps to restart the FCI nodes for the Always On HA setting change to take effect:
Restart the owner or primary node.
Connect to the secondary node using a remote desktop and check if the secondary node has been marked as online node (now owner or primary) in Failover Cluster Manager.
After validating the node ownership, check if Always On HA is enabled.
On the SQL Server Configuration Manager, choose SQL Server Services.
Choose SQL Server.
Choose Properties.
Choose the AlwaysOn High Availability tab.
The following is a screenshot of the Always On HA setting.
{kind=link}
Restart the secondary node (now owner or primary node).
When the node restarts, check if the node ownership is set to the original primary node in Failover Cluster Manager.
On Node 3, enable Always On HA as specified in the preceding steps. Restart the Node 3 server for the changes to take effect if not done already.
Configure failover cluster settings on Node 3
To configure the failover cluster settings on Node 3, complete the following steps:
Connect to Node 3 using remote desktop and open Failover Cluster Manager.
Choose Nodes to find both SQL FCI nodes listed.
To add a third node, choose Nodes (right-click) and choose Add Node.
Enter the Node 3 server name and choose Add.
Choose Next.
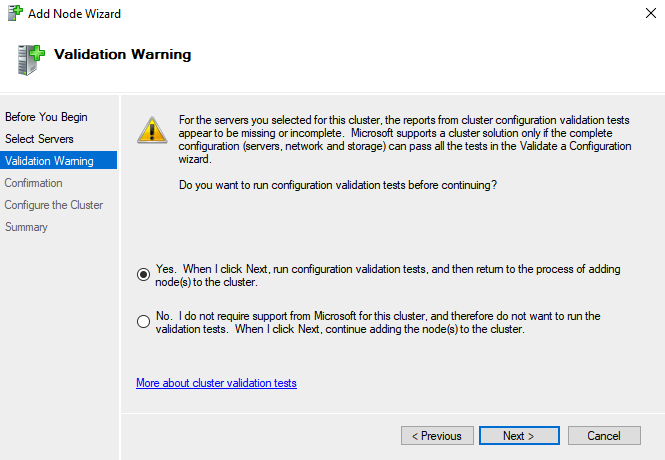
Select the option Yes to test the configuration.
Choose Next.
Select Run all tests.
Choose Next.
When the testing is done, validate if there are any errors.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
There might be some warning as shown in following screenshot with regards to a multi-subnet setup, which can be ignored.
Choose Finish.
Validate if the third node is added in Failover Cluster Manager under Nodes, as shown in the following screenshot.
{kind=link}
{kind=link}
Now that we have successfully added Node 3 in the failover cluster, we configure SQL Server services on Node 3 to replicate the database using availability groups.
Configure SQL Server services
Ensure that the SQL Server and SQL Browser services on all three nodes are using same SQL Server account. You can validate this from the SQL Server Configuration Manager, as shown in the following screenshot. In this example, I used the service account GarryoncloudAdmin across all nodes to run the SQL services.
{kind=link}
Configure the Always On availability group
You’re now ready to configure the Always On availability group.
Prerequisites
You should now have Always On HA enabled on all three nodes. Restart the nodes after enabling Always On HA before proceeding. Additionally, recycle the SQL Server role in Failover Cluster Manager by stopping and starting it.
{kind=link}
Now, let’s grant permission to the system account on Node 3 and the owner or primary FCI (either Node 1 and Node 2). The following SQL script grants the required permission. To run this script on the owner or primary FCI, connect to the cluster server object. The system account within SQL Server is a listed prerequisite to allow the cluster process (RHS.exe), which hosts the SQL DLL file, to bring the Always On availability group online as part of the setup process. It also allows the process to periodically perform health detection on SQL Server by connecting to the SQL instance to monitor health and perform a failover when necessary. This is the minimal permission required by the cluster service. For more information about system account permissions for SQL Server instances, see Configure system account permissions.
Configure the database availability replica
To configure the database availability replica, complete the following steps:
On the primary FCI, open SQL Server Management Studio (SSMS) and connect to the FCI cluster SQL Server.
Create a new database or use an existing database that you want to be part of the availability group.
Ensure the database is set to full recovery mode.
Take a full backup of the database.
Take a transaction log backup that is appended to full backup (same .bak file).
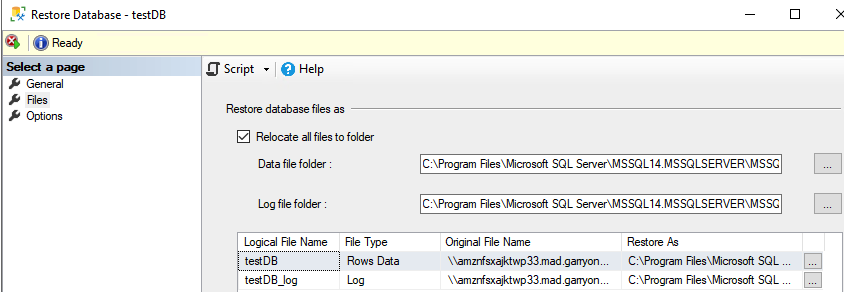
On the Files page, select Relocate all files to folder.
Copy the backup file locally to Node 3 and restore the database with the Restore with norecovery option.
Choose Ok to start restoring the database.
{kind=link}
{kind=link}
In the following screenshot, testDB is in Restoring mode. It won’t change until we configure the availability group.
{kind=link}
Before you proceed, it’s important to ensure that the SQL services running on all nodes are using the service account that grants access to the SQL nodes. It’s preferable to use the same SQL service account across nodes. More information is in the earlier section on configuring SQL Server services.
Configure availability group
To configure the availability group, complete the following steps:
In SSMS, under AlwaysOn High Availability, choose (right-click) Availability Group.
Choose New Availability Group Wizard.
Choose Next.
For Availability group name, enter a name (for this post, SQL-AG1).
For Cluster type, leave as Windows Server Failover Cluster.
Select the database that you configured as the availability replica (for this post, testDB).
Choose the primary instance for your availability group. We recommend configuring the FCI as the primary.
In this example, I leave Availability Mode as Asynchronous commit, but you can change it to synchronous mode if the network latency permits.
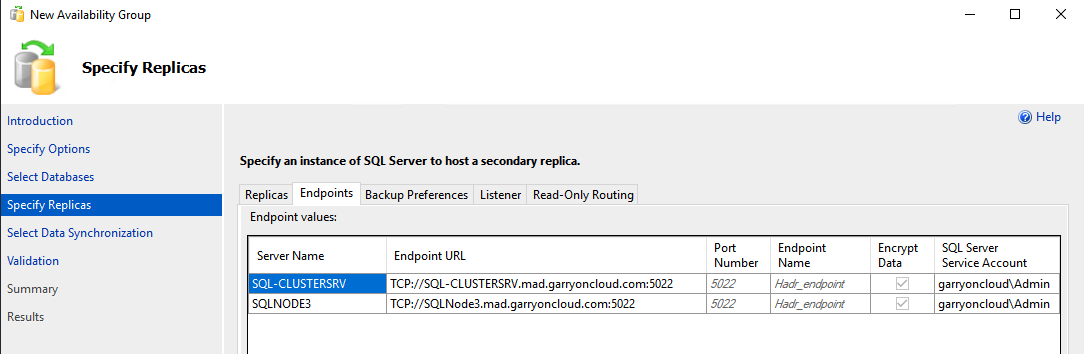
Choose Add Replica to add a secondary replica (for this post, Node 3).
On the Endpoint tab, make sure that both endpoints are using the SQL Server account (for this post, it’s GarryoncloudAdmin).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
If you don’t see the correct service account, you need to go to the SQL node and configure the SQL services to use the correct account and restart the availability group wizard.
Note that you can’t configure the secondary replica to automatic failover when the primary is the FCI.
Configure the backup preference, listener, and read-only routing as per your needs.
By default, listener is disabled.
Choose Next to continue.
Select Join only and choose Next.
Validate your configuration and finish creating your availability group.
You can see detailed progress on the next screen by choosing the arrow next to More details.
Availability group creation takes some time to complete. However, if it’s stuck, it may be because your Windows firewall is enabled or the endpoint isn’t using the SQL Server account. Also, make sure the security group has the required ports open. It’s better to check the SQL current logs at this point to troubleshoot the issue.
When node creation is complete and it’s joined to the availability group successfully, choose Close.
{kind=link}
Validate the configuration
To validate your configuration, go to SSMS and connect to FCI SQL Server.
Under Availability Groups, you now see the new availability group that we created and both the primary (FCI) and secondary node.
{kind=link}
On Node 3, you can see the status of the database joined to the availability group changes from Restoring to Synchronizing.
{kind=link}
Troubleshooting
If you see the joining is talking longer and the endpoint is using the correct SQL account, run the following script to grant the account permission on both the nodes:
Summary
In this post, we discussed three distinct ways to make your Microsoft SQL Server database highly available in AWS: Multi-AZ Amazon RDS for SQL Server, SQL Server FCIs on Amazon EC2 with Amazon FSx as continuously available Multi-AZ shared storage, and SQL Server Always On availability groups. Then we dived deep into a hybrid approach with SQL Server on Windows Server Failover Cluster on two EC2 instances and an availability group replica on a standalone EC2 instance for read-heavy, secondary workloads such as reporting.
You can read more about high availability and read replicas in Amazon RDS for SQL Server to understand the benefits of moving to this managed service.
About the Author
Garry Singh is a Solutions Architect with Amazon Web Services. He works with AWS customers to provide guidance and technical assistance to help them achieve the best outcome for Microsoft workloads on AWS.
{kind=link}
Read MoreAWS Database Blog