

{kind=link}
In this blog series, a companion to our paper, we’re exploring different types of data-driven organizations. In the last blog, we discussed main principles for building a data engineering driven organisation. In this second part of the series focus is on how to build a data science driven organization.
The emergence of big data, advances in machine learning and the rise of cloud services has been changing the technological landscape dramatically over the last decade and have pushed the boundaries in industries such as retail, chemistry, or healthcare. In order to create a sustainable competitive advantage from this paradigmatic shift companies need to become ‘data science driven organizations’.1 In the course of this article we discuss the socio-technical challenges those companies are facing and provide a conceptual framework built on first principles to help them on their journey. Finally, we will show how those principles can be implemented on Google Cloud.
Challenges of data science driven organizations
A data science driven organization can be described as an entity that maximizes the value from the data available while using machine learning and analytics to create a sustainable competitive advantage. Becoming such an organization is more of a sociotechnical challenge rather than a purely technical one. In this context, we identified four main challenges:
Inflexibility: Many organizations have not built an infrastructure flexible enough to quickly adapt to a fast changing technical landscape. This inflexibility comes with the cost of lock-in effects, outdated technology stacks, and a bad signaling for potential candidates. While those effects might be less pronounced in more mature areas like data warehouses, they are paramount for data science and machine learning.
Disorder: Most organizations grow in an organic way. This often results in a non-standardized technological infrastructure. While standardization and flexibility are often seen as diametrically opposed to each other, a certain level of standardization is needed to establish a technical ‘lingua franca’ across the organization. A lack of the same harms collaborations and knowledge sharing between teams and hampers modular approaches as seen in classical software engineering.
Opaqueness: Data science and machine learning are fundamentally data driven (engineering) disciplines. As data is in a constant flux, accountability and explainability are pivotal for any data science driven organization.2 As a result data science and machine learning workflows need to be defined in the same rigour as classical software engineering. Otherwise, such workflows will turn into unpredictable black boxes.
Data Culture (or lack thereof): Most organisations have a permission culture where data is managed by a team which then becomes a bottleneck on providing rapid access as they cannot scale with the requests. However, in organizations driven by data culture there are clear ways to access data while retaining governance. As a result, machine learning practitioners are not slowed down by politics and bureaucracy and they can carry out their experiments.
Personas in data science driven organizations
Data science driven organizations are heterogeneous. Nevertheless, most of them leverage four core personas: data engineers, machine learning engineers, data scientists, and analysts. It is important to mention that those roles are not static and overlap to a certain extent. An organizational structure needs to be designed in such a way that it can leverage the collaboration and full potential of all personas.
Data engineers take care of creating data pipelines and making sure that the data available fulfills the hygienic needs. For example, cleansing, joining and enriching multiple data sources to turn data into information on which downstream intelligence is based.
Machine learning engineers develop and maintain complete machine learning models. While machine learning engineers are the rarest of the four personas, they become indispensable once an organization plans to run business critical workflows in production.
Data scientists act as a nexus between data and machine learning engineers. Together with business stakeholders they translate business driven needs into testable hypotheses, make sure that value is derived from machine learning workloads and create reports to demonstrate value from the data.
Data analysts bring the business insight and make sure that data driven solutions that business is seeking are implemented. They answer adhoc questions, provide regular reports that analyze not only the historical data but also what has happened recently.
There are different arguments if a company should build centralized or decentralized data science teams. In both cases, teams face similar challenges as outlined earlier. There are also hybrid models, as a federated organization whereby data scientists are embedded from a centralized organization. Hence, it is more important to focus on how to tackle those challenges using first principles. In the following sections, we discuss those principles and show how a data science and machine learning platform needs to be designed in order to facilitate those goals.
First principles to build a data science driven organization
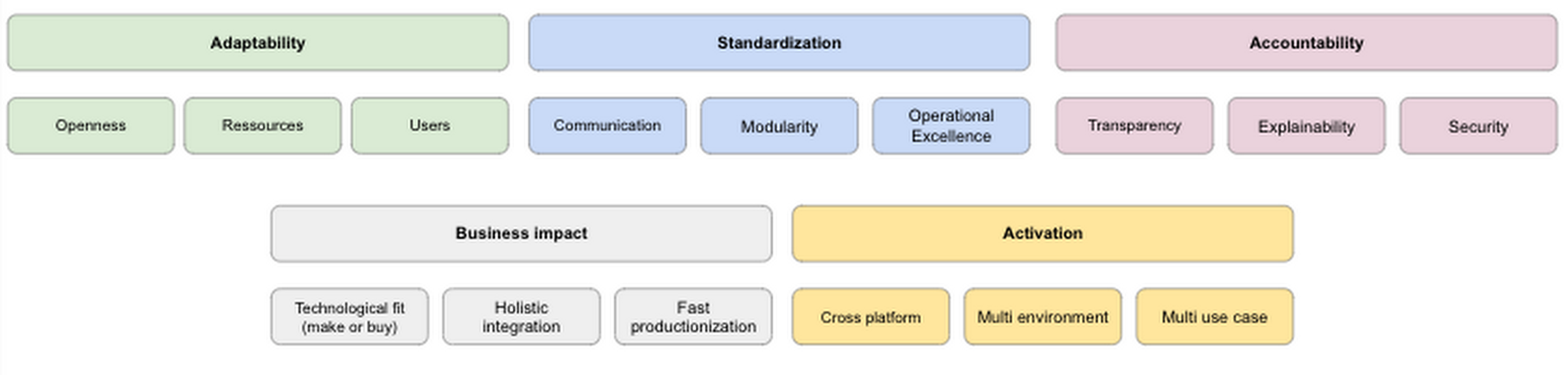
Adaptability: A platform needs to be flexible enough to enable all kinds of personas. While some data scientists/analysts, for example, are more geared toward developing custom models by themselves, others may prefer to use no-code solutions like AutoML or carry out analysis in SQL. This also includes the availability of different machine learning and data science tools like TensorFlow, R, Pytorch, Beam, or Spark. At the same time, the platform should be open enough to work in multi-cloud and on-premises environments while supporting open source technology when possible to prevent lock-in effects. Finally, resources should never become a bottleneck as the platform needs to scale quickly with an organization’s needs.
Activation: Ability to operationalize models by embedding analytics into the tools used by end users is key to achieve scaling in providing services to a broad set of users. The ability to send small batches of data to the service and it returns your predictions in the response allows developers with little data science expertise to use models. In addition, it is important to facilitate seamless deployment and monitoring of edge inferences and automated processes with flexible APIs. This allows you to distribute AI across your private and public cloud infrastructure, on-premises data centers, and edge devices.
Standardization: Having a high degree of standardization helps to increase a platform’s overall efficiency. A platform that supports standardized ways of sharing code and technical artifacts increases internal communication. Such platforms are expected to have built in repositories, feature stores and metadata stores. Furthermore, making those resources queryable and accessible boost teams’ performance and creativity. Only when such kind of communication is possible data science and machine learning teams can work in a modular fashion as it has been for classical software engineering for years. An important aspect of standardisation is enabled by using standard connectors so that you can rapidly connect to a source/target system. Products such as Datastreamand Data Fusion provide such capabilities. On top of it, a high degree of standardization avoids ‘technical debt’ (i.e. glue code) which is still prevalent in the majority of most machine learning and data science workflows.3
Accountability: Data science and machine learning use cases often deal with sensitive topics like fraud detection, medical imaging, or risk calculation. Hence, it’s paramount that a data science and machine learning platform helps to make those workflows as transparent, explainable, and secure as possible. Openness is connected to operational excellence. Collecting and monitoring metadata during all stages of the data science and machine learning workflows is crucial to create a ‘paper trail’ allowing us to ask questions such as:
Which data was used to train the model?
Which hyperparameters were used?
How is the model behaving in production?
Did any form of data drift or model skew occur during the last period?
Furthermore, a data science driven organization needs to have a clear understanding of their models. While this is less of an issue for classical statistical methods, machine learning models, like deep neural networks, are much more opaque. A platform needs to provide simple tools to analyze such models for confident usage. Finally, a mature data science platform needs to provide all the security measures to protect data and artifacts while managing resource usage on a granular level.
Business Impact: many data science projects fail to go beyond pilot or POC stages according to McKinsey.4 Therefore, the ability to anticipate/measure business impact of new efforts, and choosing ROI rather than the latest cool solution is more important. As a result it is key to identify when to buy, build, or customize ML models and connect them together in a unified, integrated stack. For example, if there is an out of the box solution which can be leveraged simply by calling an API rather than building a model after months of development would help realising higher ROI and demonstrating value.
We conclude this part with the summary of the first principles. The next section will show how those principles can be applied on Google Cloud’s unified ML platform, Vertex AI.
{kind=link}
Using first principles to build a data science platform on Google Cloud
Adaptability
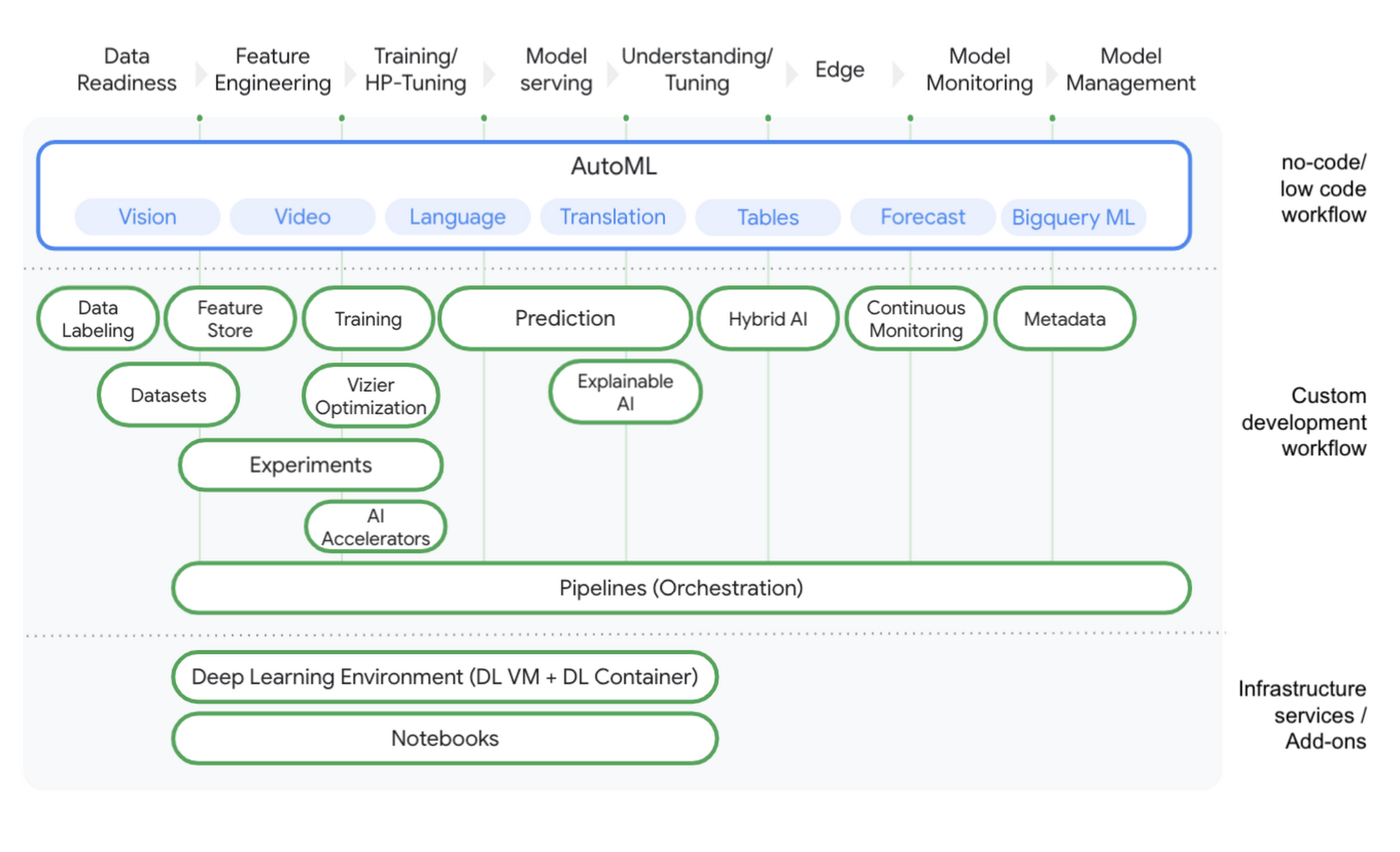
With Vertex AI, we are providing a platform built on the first principles that covers the entire data science / machine learning journey from data readiness to model management. Vertex AI opens up the usage of data science and machine learning by providing no-code, low-code, and custom code procedures for data science and machine learning workflows. For example, if a data scientist would like to build a classification model they can use AutoML Tables to build an end-to-end model within minutes. Alternatively, they can start their own notebook on Vertex AI to develop custom code in their framework of choice (for instance, TensorFlow, Pytorch, R). Reducing the entry barrier to build complete solutions is not only saving developers time but enables a wider range of personas (such as data or business analysts). This reduced barrier helps them to leverage tools enabling the whole organization to become more data science and machine learning driven.
We strongly believe in open source technology as it provides higher flexibility, attracts talent, and reduces lock-in. With Vertex Pipelines, we are echoing the industry standards of the open source world for data science and machine learning workflow orchestration. As a result, allowing data scientists / machine learning engineers to orchestrate their workflows in a containerized fashion. With Vertex AI, we reduced the engineering overhead for resource provisioning and provided a flexible and cost-effective way to scale up and down when needed. Data scientists and machine learning practitioners can, for example, run distributed training and prediction jobs with a few lines of Python code in their notebooks on Vertex AI.
{kind=link}
Activation
It is important to operationalize your models by embedding analytics into the tools used by your end users. This allows scaling beyond traditional data science users and bringing other users into data science applications. For example, you can train BigQuery ML models and scale them using Vertex AI predictions. Let’s say business analysts running SQL queries are able to test the ability of the chosen ML models and experiment with what is the most suitable solution. This reduces the time for activation as business impact can be observed sooner. On the other hand, Vertex Edge Manager would let you deploy, manage, and run ML models on edge devices with Vertex AI.
Standardization
With all AI services living under Vertex AI, we standardized data science and machine learning workflows. Together with Vertex Pipelines every component in Vertex can be orchestrated, making any form of glue code obsolete helping to enhance operational excellence. As Vertex Pipelines are based on components (containerized steps), parts of a pipeline can be shared with other teams. For example, let’s assume the scenario where a data scientist has written an ETL pipeline for extracting data from a database. This ETL pipeline is then used to create features for downstream data science and machine learning tasks. Data Scientists can package this component, share it by using GitHub or Cloud Source Repository and make it available for other teams who can seamlessly integrate it in their own workflows. This helps teams to work in a more modular manner and fosters team collaboration across the board. Having such a standardized environment makes it easier for data scientists and machine learning engineers to rotate between teams and avoid compatibility issues between workflows. New components like Vertex Feature Store further improve collaboration by helping to share features across the organization.
Accountability
Data science and machine learning projects are complex, dynamic, and therefore require a high degree of accountability. To achieve this, data science and machine learning projects need to create a ‘paper trail’ that captures the nuances of the whole process. Vertex ML Metadata automatically tracks the metadata of models trained and workflows being run. It provides a metadata store to understand a workflow’s lineage (such as how a model was trained, which data has been used and how the model has been deployed). A new model repository provides you a quick overview of all models trained under the project. Additional services like Vertex Explainable AI help you to understand why a machine learning model made a certain prediction. Further, features like continuous monitoring including the detection of prediction drift and training-serving skew help you to take control of productionized models.
Business Impact: as discussed earlier it is key to identify when to buy, build, or customize ML models and connect them together in a unified, integrated stack. For example, if your company wants to make their services and products more accessible to their global clientele through translation, you could simply use Cloud Translation API if you are translating websites and user comments. That’s exactly what it was trained on and you probably don’t have an internet-sized dataset to train your ML model on. On the other hand, you may choose to build a custom solution on your own. Even though Google Cloud has Vision API that is trained on the same input (photos) and label, your organisation may have a much larger dataset of such images and might give better results for the particular use case. Of course, they can always compare their final model against the off-the-shelf solution to see if they made the right decision. Checking feasibility is important, so when we talk about building models, we always mention quick methods to check that you are making the right decisions.
Conclusion
Building a data science driven organization comes along with several socio-technical challenges. Often an organization’s infrastructure is not flexible enough to react to a fast changing technological landscape. A platform also needs to provide enough standardization to foster communication between teams and establish a technical ‘lingua franca’. Doing so is key to allow modularized workflows between teams and establish operational excellence. In addition, it is often too opaque to securely monitor complex data science and machine learning workflows. We argue that a data science driven organization should be built on a technical platform which is highly adaptable in terms of technological openness. Hence, enabling a wide set of personas and providing technological resources in a flexible and serverless manner. Whether to buy a solution or build a solution is one of the key drivers of realising return of investment for the organisation and this will define the business impact any AI solution would make. At the same time, enabling a broad number of users allows activating more use cases. Finally, a platform needs to provide the tools and resources to make data science and machine learning workflows open, explanatory, and secure in order to provide the maximum form of accountability. Vertex AI is built on those pillars helping you to become a data science driven organization. Visit our Vertex AI page to learn more.
1. Data science is used as an umbrella term for the interplay of big data, analytics and machine learning.
2. The Covid pandemic is a prime example as it has significantly affected our environment and therefore the data on which data-science and machine learning workflows are based.
3. Sculley et al. (2015). Hidden technical debt in machine learning.
4. https://www.mckinsey.com/business-functions/mckinsey-analytics/our-insights/global-survey-the-state-of-ai-in-2020
Cloud BlogRead More