

{kind=link}
In the “What type of data processing organisation” paper, we examined that you can build a data culture whether your organization consists mostly of data analysts, or data engineers, or data scientists. However, the path and technologies to become a data-driven innovator are different and success comes from implementing the right tech in a way that matches a company’s culture. In this blog we will expand the data engineering driven organizations and provide how it can be built from the first principles.
Not all organizations are alike. All companies have similar functions (sales, engineering, marketing), but not all functions have the same influence on the overall business decisions. Some companies are more engineering-driven, others are sales-driven, others are marketing-driven. In practice, all companies are a mixture of all these functions. In the same way, the data strategy can be more focused on data analysts, and others on data engineering. Culture is a combination of several factors, business requirements, organizational culture, and skills within the organization.
Traditionally organizations that focused on engineering mainly came from technology driven digital backgrounds. They built their own frameworks or used programming frameworks to build repeatable data pipelines. Some of this is due to the way the data is received, the shape the data is received and the speed of the data arrival as well. If your data allows it, your organization can be more focused on data analysis, and not so much on data engineering. If you can apply an Extract-Load-Transform approach (ELT) rather than the classic Extract-Transform-Load (ETL), then you can focus on data analysis and might not need extensive data engineering capability. For example, data that can be loaded directly into the data warehouse allows data analysts to also do data engineering work and apply transformations to the data.
This does not happen so often though. Sometimes your data is messy, inconsistent, bulky, and encoded in legacy file formats or as part of legacy databases or systems, with a little potential to be actionable by data analysts.
Or maybe you need to process data in streaming, applying complex event processing to obtain competitive insights in near real time. The value of data decays exponentially with time. Most companies can process data by the next day in batch mode. However, not so many are probably obtaining such knowledge the next second data is produced.
In these situations, you need the talent to unveil the insights hidden in that amalgam of data, either messy or fast changing (or both!). And almost as importantly, you need the right tools and systems to enable that talent too.
What are those right tools? Cloud provides the scalability and flexibility for data workloads that are required in such complex situations. Long gone are the times when data teams had to beg for the resources that were required to have an impact in the business. Data processing systems are no longer scarce, so your data strategy should not generate that scarcity artificially.
In this article, we explain how to leverage Google Cloud to enable data teams to do complex processing of data, in batch and streaming. By doing so, your data engineering and science teams can have an impact when (in seconds) after the input data is generated.
Data engineering driven organizations
When the complexity of your data transformation needs is high, data engineers have a central role in the data strategy of your company, leading to data engineering driven organization. In this type of organization, data architectures are organized in three layers: business data owners, data engineers, and data consumers.
Data engineers are at the crossroads between data owners and data consumers, with clear responsibilities:
Transporting data, enriching data whilst building integrations between analytical systems and operational systems ( as in the real time use cases)
Parsing and transforming messy data coming from business units into meaningful and clean data, with documented metadata
Applying DataOps, that is, functional knowledge of the business plus software engineering methodologies applied to the data lifecycle
Deployment of models and other artifacts analyzing or consuming data
{kind=link}
Business data owners are cross-functional domain-oriented teams. These teams know the business in detail, and are the source of data that feeds the data architecture. Sometimes these business units may also have some data-specific roles, such as data analysts, data engineers, or data scientists, to work as interfaces with the rest of the layers. For instance, these teams may design a business data owner, that is the point of contact of a business unit in everything that is related to the data produced by the unit.
At the other end of the architecture, we find the data consumers. Again, also cross-functional, but more focused on extracting insights from the different data available in the architecture. Here we typically find data science teams, data analysts, business intelligence teams, etc. These groups sometimes combine data from different business units, and produce artifacts (machine learning models, interactive dashboards, reports, and so on). For deployment, they require the help of the data engineering team so that data is consistent and trusted.
At the center of these crossroads, we find the data engineering team. Data engineers are responsible for making sure that the data generated and needed by different business units gets ingested into the architecture. This job requires two disparate skills: functional knowledge and data engineering/software development skills. This is often coined under the term DataOps (which evolved from DevOps methodologies developed within the past decades but applied to data engineering practices).
Data engineers have another responsibility too. They must help in the deployment of artifacts produced by the data consumers. Typically, the data consumers do not have the deep technical skills and knowledge to take the sole responsibility for deployment of their artifacts.This is also true for highly sophisticated data science teams. So data engineers must add other skills under their belt: machine learning and business intelligence platform knowledge. Let’s clarify this point, we don’t expect data engineers to become machine learning engineers. Data engineers need to understand ML to ensure that the data delivered to the first layer of a model ( the input ) is correct. They will also become key when delivering that first layer of data in the inference path, as here the data engineering skills around scale / HA etc really need to shine.
By taking the responsibility of parsing and transforming messy data from various business units, or for ingesting in real time, data engineers allow the data consumers to focus on creating value. Data science and other types of data consumers are abstracted away from data encodings, large files, legacy systems, complex message queue configurations for streaming. The benefits of concentrating that knowledge in a highly skilled data engineering team are clear, notwithstanding that other teams (business units and consumers) may also have their data engineers to work as interfaces with other teams. More recently, we even see squads created with members of the business units (data product owners), data engineers, data scientists, and other roles. Effectively creating complete teams with autonomy and full responsibility over a data stream, from the incoming data down to the data driven decision with impact in the business.
Reference architecture – Serverless
The number of skills required for the data engineering team is vast and diverse. We should not make it harder by expecting the team to maintain the infrastructure where they run data pipelines. They should be focusing on how to cleanse, transform, enrich, and prepare the data rather than how much memory or how many cores their solution may require.
The reference architectures presented here are based on the following principles:
Serverless no-ops technologies
Streaming-enabled for low time-to-insight
We present different alternatives, based on different products available in Google Cloud:
Dataflow, the built-in streaming analytics platform in Google Cloud
Dataproc, the Google Cloud’s managed platform for Hadoop and Spark.
Data Fusion, a codeless environment for creating and running data pipelines
Let’s dig into these principles.
By using serverless technology we eliminate the maintenance burden from the data engineering team, and we provide the necessary flexibility and scalability for executing complex and/or large jobs. For example, scalability is essential when planning for traffic spikes during mega Friday for retailers. Using serverless solutions allows retailers to look into how they are performing during the day. They no longer need to worry about resources needed to process massive data generated during the day.
The team needs to have full control and write their own code for the data pipelines because of the type of pipelines that the team develops. This is true either for batch or streaming pipelines. In batch, the parsing requirements can be complex and no off the shelf solution works. In streaming, if the team wants to fully leverage the capabilities of the platform, they should implement all the complex business logic that is required, without artificially simplifying the complexity in exchange for some better latency. They can develop a pipeline that achieves a low latency with highly complex business logic. This again requires the team to start writing code from first principles.
However, that the team needs to write code should not imply that they need to rewrite any existing piece of code. For many input/output systems, we can probably reuse code from patterns, snippets, and similar examples. Moreover, a logical pipeline developed by a data engineering team does not necessarily need to map to a physical pipeline. Some parts of the logic can be easily reused by using technologies like Dataflow templates, and use those templates in orchestration with other custom developed pipelines. This brings the best of both worlds (reuse and rewrite), while saving precious time that can be dedicated to higher impact code rather than common I/O tasks. The reference architecture presented has another important feature: the possibility to transform existing batch pipelines to streaming.
{kind=link}
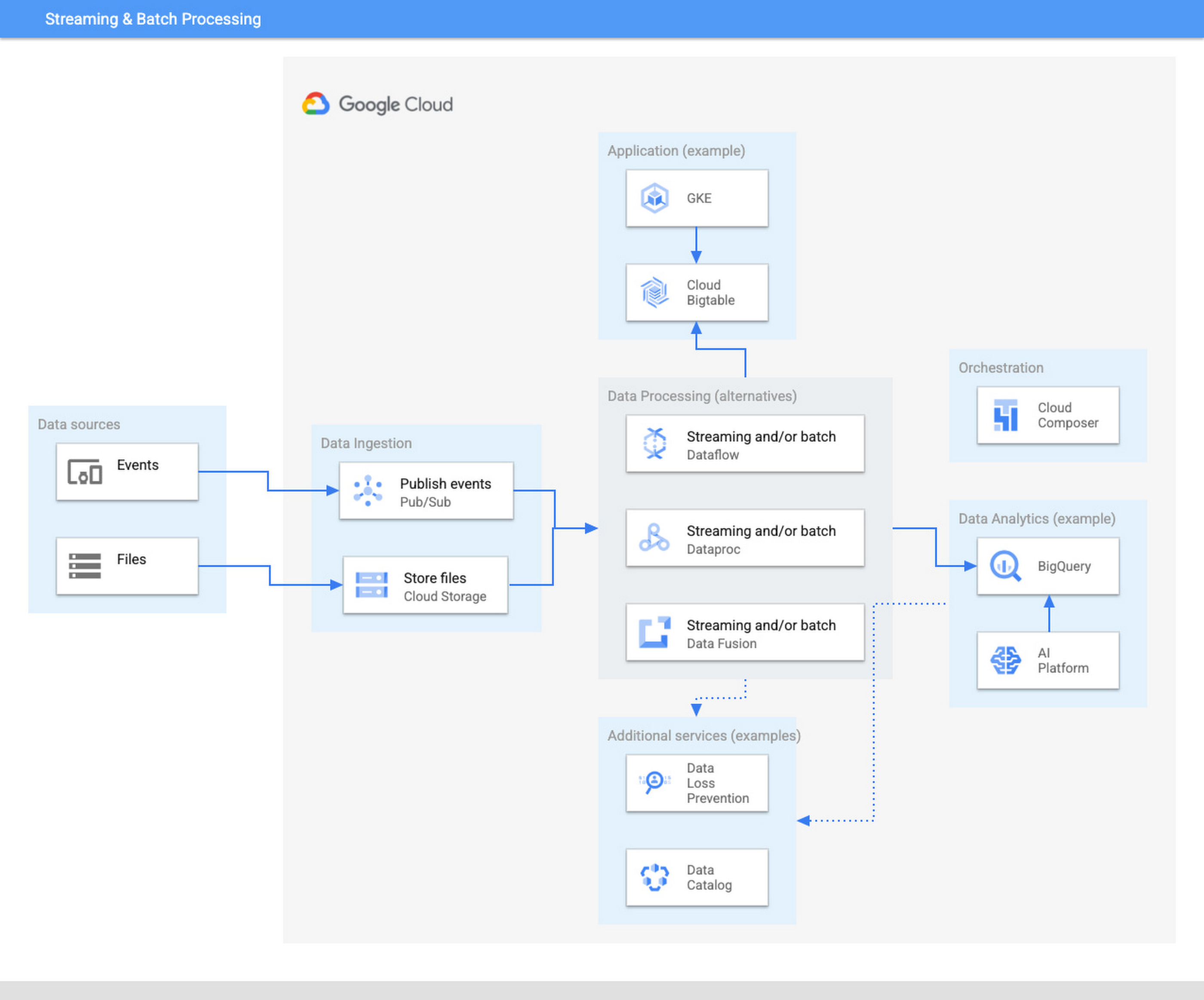
The ingestion layer consists of Pub/Sub for real time and Cloud Storage for batch and does not require any preallocated infrastructure. Both Pub/Sub and Cloud Storage can be used for a range of cases as it can automatically scale up with the input workload.
Once the data has been ingested, our proposed architecture follows the classical division in three stages: Extract, Transform, and Load (ETL). For some types of files, direct ingestion into BigQuery (following an ELT approach) is also possible.
In the transform layer, we primarily recommend Dataflow as the data process component. Dataflow uses Apache Beam as SDK. The main advantage of Apache Beam is the unified model for batch and streaming processing. As mentioned before, the same code can be adapted to run in batch or streaming by adapting input and output. For instance, switching the input from files in Cloud Storage to messages published in a topic in Pub/Sub.
One of the alternatives to Dataflow in this architecture is Dataproc, Google Cloud’s solution for managed Hadoop and Spark clusters. The main use case is for those teams that are migrating to Google Cloud but have large amounts of inherited code in Spark or Hadoop. Dataproc enables a direct path to the cloud, without having to review all those pipelines.
Finally, we also present the alternative of Data Fusion, a codeless environment for creating data pipelines using a drag-and-drop interface. Data Fusion actually uses Dataproc as its Compute Engine, so everything we have mentioned earlier applies also to the case of Data Fusion. If your team prefers to create data pipelines without having to write any code, Data Fusion is the right tool.
So in summary, these are the three recommended components for the transform layer:
Dataflow, powerful and versatile with a unified model for batch and streaming processing. Straightforward path to move from batch processing to streaming
Dataproc, for those teams that want to reuse existing code from Hadoop or Spark environments.
Data Fusion, if your team does not want to write any code.
Challenges and opportunities
Data platforms are complex. Having on top of that data responsibility the duty to maintain infrastructure is a wasteful use of valuable skills and talent. Often data teams end up managing infrastructure rather than focusing on analyzing the data. The architecture presented in this article liberates the data engineering team from having to allocate infrastructure and tweak clusters but instead to focus on providing value through data processing pipelines.
For data engineers to focus on what they do best, you need to fully leverage the cloud. A lift & shift approach from any on-premise installation is not going to provide that flexibility and liberation. You need to leverage serverless technologies. As an added advantage, serverless lets you also scale your data processing capabilities with your needs, and be able to respond to peaks of activity, however large these are.
Serverless technologies sometimes face the doubts of practitioners: will I be locked in with my provider if I fully leverage serverless? This is actually a question that you should be asking when deciding whether to set up your architecture on top of a provider.
The components presented here for data processing are based on open source technologies, and fully interoperable with other open source equivalent components. Dataflow uses Apache Beam, which not only unifies batch and streaming, but also offers a widely compatible runner. You can take your code elsewhere to any other runner. For instance, Apache Flink or Apache Spark. Dataproc is a fully managed Hadoop and Spark based on the vanilla open source components of this ecosystem. Data Fusion is actually the Google Cloud version of CDAP, an open source project.
On the other hand, for the serving layer, BigQuery is based on standard Ansi SQL. Whereas in the case of Bigtable and Google Kubernetes Engine, Bigtable is compatible at API level with HBase, and Kubernetes is an open source component.
In summary, when your components are based on open source, like the ones included in this architecture, serverless does not lock you in. The skills required to encode business logic in the form of data processing pipelines are based on engineering principles that remain stable across time. The same principles apply if you are using Hadoop, Spark, or Dataflow or UI driven ETL tooling. In addition, there are now new capabilities, such as low-latency streaming, that were not available before. A team of data engineers that learn the fundamental principles of data engineering will be able to quickly leverage those additional capabilities.
Our recommended architecture separates the logical level, the code of your applications, from the infrastructure where they run. This enables data engineers to focus on what they do best and on where they provide the highest added value. Let your Dataflow and your engineers impact your business, by adopting the technologies that liberate them and allow them to focus on adding business value. To learn more about building an unified data analytics platform, take a look at our recently published Unified Data Analytics Platform paper and Converging Architectures paper.
Cloud BlogRead More