

{kind=link}
Amazon Kendra is an intelligent search service powered by machine learning (ML). It indexes the documents stored in a wide range of repositories and finds the most relevant document based on the keywords or natural language questions the user has searched for. In some scenarios, you need the search results to be filtered based on the context of the user making the search. Additional refinement is needed to find the documents specific to that user or user group as the top search result.
In this blog post, we focus on retrieving custom search results that apply to a specific user or user group. For instance, faculty in an educational institution belongs to different departments, and if a professor belonging to the computer science department signs in to the application and searches with the keywords “faculty courses,” then documents relevant to the same department come up as the top results, based on data source availability.
Solution overview
To solve this problem, you can identify one or more unique metadata information that is associated with the documents being indexed and searched. When the user signs in to an Amazon Lex chatbot, user context information can be derived from Amazon Cognito. The Amazon Lex chatbot can be integrated into Amazon Kendra using a direct integration or via an AWS Lambda function. The use of the AWS Lambda function will provide you with fine-grained control of the Amazon Kendra API calls. This will allow you to pass contextual information from the Amazon Lex chatbot to Amazon Kendra to fine-tune the search queries.
In Amazon Kendra, you provide document metadata attributes using custom attributes. To customize the document metadata during the ingestion process, refer to the Amazon Kendra Developer Guide. After completing the document metadata generation and indexing steps, you need to focus on refining the search results using the metadata attributes. Based on this, for example, you can ensure that users from the computer science department will get search results ranked according to their relevance to the department. That is, if there’s a document relevant to that department, it should be on the top of the search-result list preceding any other document without department information or nonmatching department.
Let’s now explore how to build this solution in more detail.
Solution walkthrough
{kind=link}
The sample architecture used in this blog to demonstrate the use case is shown in Figure 1. You will set up an Amazon Kendra document index that consumes data from an Amazon Simple Storage Service (Amazon S3) bucket. You will set up a simple chatbot using Amazon Lex that will connect to the Amazon Kendra index via an AWS Lambda function. Users will rely on Amazon Cognito to authenticate and gain access to the Amazon Lex chatbot user interface. For the purposes of the demo, you will have two different users in Amazon Cognito belonging to two different departments. Using this setup, when you sign in using User 1 in Department A, search results will be filtered documents belonging to Department A and vice versa for Department B users.
Prerequisites
Before you can try to integrate the Amazon Lex chatbot with an Amazon Kendra index, you need to set up the basic building blocks for the solution. At a high level, you need to perform the following steps to enable this demo:
Set up an S3 bucket data source with the appropriate documents and folder structure. For instructions on creating S3 buckets, please refer to AWS Documentation – Creating a bucket. Store the required document metadata along with the documents statically in the S3 bucket. To understand how to store document metadata for your documents in the S3 bucket, please refer to AWS Documentation – Amazon S3 document metadata. A sample metadata file could look like the one below:
Set up an Amazon Kendra index by following the AWS documentation – Creating an index.
Add the S3 bucket as a data source to your index by following the AWS Documentation – Using an Amazon S3 data source. Ensure that Amazon Kendra is aware of the metadata information and allows the department information to be faceted.
You need to ensure the custom attributes in the Amazon Kendra index are set to be facetable, searchable, and displayable. You can do this in the Amazon Kendra console, by going to Data management and choosing Facet definition. To do this using the AWS command line interface (AWS CLI), you can leverage the kendra update-index command.
Set up an Amazon Cognito user pool with two users. Associate a custom attribute with the user to capture their department values.
Build a simple Amazon Lex v2 chatbot with required intents, slots, and utterances to drive the use case. In this blog, we will not provide detailed guidance on setting up the basic bot as the focus of the blog is to understand how to send user context information from the front end to the Amazon Kendra index. For details on creating a simple Amazon Lex bot, refer to the Building bots documentation. For the rest of the blog, it is assumed that the Amazon Lex chatbot has the following:
Intent – SearchCourses
Utterance – “What courses are available in {subject_types}?”
Slot – elective_year (can have values – elective, nonelective)
You need to create a chatbot interface that the user will use to authenticate and interact with the chatbot. You can use the Sample Amazon Lex Web Interface (lex-web-ui) provided by AWS to get started. This will simplify the process of testing the integrations as it already integrates Amazon Cognito for user authentication and passes the required contextual information and Amazon Cognito JWT identity token to the backend Amazon Lex chatbot.
Once the basic building blocks are in place, your next step will be to create the AWS Lambda function that will tie together the Amazon Lex chatbot intent fulfillment with the Amazon Kendra index. The rest of this blog will specifically focus on this step and provide details on how to achieve this integration.
Integrating Amazon Lex with Amazon Kendra to pass user context
Now that the prerequisites are in place, you can start working on integrating your Amazon Lex chatbot with the Amazon Kendra index. As part of the integration, you will need to perform the following tasks:
Write an AWS Lambda function that will be attached to your Amazon Lex chatbot. In this Lambda function, you will parse the incoming input event to extract the user information, such as the user ID and additional attributes for the user from the Amazon Cognito identity token that is passed in as part of the session attributes in the event object.
Once all the information to form the Amazon Kendra query is in place, you submit a query to the Amazon Kendra index, including all the custom attributes that you want to use to scope down the search results view.
Finally, once the Amazon Kendra query returns the results, you generate a proper Amazon Lex response object to send the search results response back to the user.
Associate the AWS Lambda function with the Amazon Lex chatbot so that whenever the chatbot receives a query from the user, it triggers the AWS Lambda function.
Let’s look at these steps in more detail below.
Extracting user context in AWS Lambda function
The first thing you need to do is code and set up the Lambda function that can act as a bridge between the Amazon Lex chatbot intent and the Amazon Kendra index. The input event format documentation provides the full input Javascript Object Notation (JSON) input event structure. If the authentication system provides the user ID as an HTTP POST request to Amazon Lex, then the value will be available in the “userId” key of the JSON object. When the authentication is performed using Amazon Cognito, the “sessionState”.”sessionAttributes”.”idtokenjwt” key will contain a JSON Web Token (JWT) token object. If you are programming the AWS Lambda function in Python, the two lines of code to read the attributes from the event object will be as follows:
The JWT token is encoded. Once you’ve decoded the JWT token, you will be able to read the value of the custom attribute associated with the Amazon Cognito user. Refer to How can I decode and verify the signature of an Amazon Cognito JSON Web Token to understand how to decode the JWT token, verify it, and retrieve the custom values. Once you have the claims from the token, you can extract the custom attribute, like “department” in Python, as follows:
When using a third-party identity provider (IDP) to authenticate against the chatbot, you need to ensure that the IDP sends an token with required attributes. The token should include required data for the custom attributes, such as department, group memberships, etc. This will be passed to the Amazon Lex chatbot in the session context variables. If you are using the lex-web-ui as the chatbot interface, then refer to the credential management section of the lex-web-ui readme documentation to understand how Amazon Cognito is integrated with lex-web-ui. To understand how you can integrate third-party identity providers with an Amazon Cognito identity pool, refer to the documentation on Identity pools (federated identities) external identity providers.
For the query topic from the user, you can extract from the event object by reading the value of the slots identified by Amazon Lex. The actual value of the slot can be read from the attribute with the key “sessionState”.”intent”.”slots”.”slot name”.”value”.”interpretedValue” based on the identified data type. In the example in this blog, using Python, you could use the following lines of code to read the query values:
As described in the documentation for input event format, the slots value is an object that can have multiple entries of different data types. The data type for any given value will be indicated by “’sessionState”.”intent”.”slots”.”slot name”.”shape”. If the attribute is empty or missing, then the datatype is a string. In the example in this blog, using Python, you could use the following lines of code to read the query values:
Once you know the data format for the slot, you can interpret the value of ‘slotValue’ based on the data type identified in ‘slotType’.
Query Amazon Kendra index from AWS Lambda
Now that you’ve managed to extract all the relevant information from the input event object, you need to construct an Amazon Kendra query within the Lambda. Amazon Kendra lets you filter queries via specific attributes. When you submit a query to Amazon Kendra using the Query API, you can provide a document attribute as an attribute filter so that your users’ search results will be based on values matching that filter. Filters can be logically combined when you need to query on a hierarchy of attributes. A sample-filtered query will look as follows:
To understand filtering queries in Amazon Kendra in more detail, you can refer to AWS documentation – Filtering queries. Based on the above query, search results from Amazon Kendra will be scoped to include documents where the metadata attribute for “document” matches the value for the filter provided. In Python, this will look as follows:
As highlighted earlier, please refer to Amazon Kendra Query API documentation to understand all the various attributes that can be provided into the query, including complex filter conditions for filtering the user search.
Handle Amazon Kendra response in AWS Lambda function
Upon a successful query within the Amazon Kendra index, you will receive a JSON object back as a response from the Query API. The full structure of the response object, including all its attributes details, are listed in the Amazon Kendra Query API documentation. You can read the “TotalNumberOfResults” to check the total number of results returned for the query you submitted. Do note that the SDK will only let you retrieve up to a maximum of 100 items. The query results are returned in the “ResultItems” attribute as an array of “QueryResultItem” objects. From the “QueryResultItem”, the attributes of immediate interest are “DocumentTitle”, “DocumentExcerpt”, and “DocumentURI”. In Python, you can use the below code to extract these values from the first “ResultItems” in the Amazon Kendra response:
Ideally, you should check the value of “TotalNumberOfResults” and iterate through the “ResultItems” array to retrieve all the results of interest. You need to then pack it properly into a valid AWS Lambda response object to be sent to the Amazon Lex chatbot. The structure of the expected Amazon Lex v2 chatbot response is documented in the Response format section. At a minimum, you need to populate the following attributes in the response object before returning it to the chatbot:
sessionState object – The mandatory attribute in this object is “dialogAction”. This will be used to define what state/action the chatbot should transition to next. If this is the end of the conversation because you’ve retrieved all the required results and are ready to present, then you will set it to close. You need to indicate which intent in the chatbot your response is related to and what the fulfillment state is that the chatbot needs to transition into. This can be done as follows:
messages object – You need to submit your search results back into the chatbot by populating the messages object in the response based on the values you’ve extracted from the Amazon Kendra query. You can use the following code as an example to accomplish this:
Hooking up the AWS Lambda function with Amazon Lex chatbot
At this point, you have a complete AWS Lambda function in place that can extract the user context from the incoming event, perform a filtered query against Amazon Kendra based on user context, and respond back to the Amazon Lex chatbot. The next step is to configure the Amazon Lex chatbot to use this AWS Lambda function as part of the intent fulfillment process. You can accomplish this by following the documented steps at Attaching a Lambda function to a bot alias. At this point, you now have a fully functioning Amazon Lex chatbot integrated with the Amazon Kendra index that can perform contextual queries based on the user interacting with the chatbot.
In our example, we have 2 users, User1 and User 2. User 1 is from the computer science department and User 2 is from the civil engineering department. Based on their contextual information related to department, Figure 2 will depict how the same conversation can result in different results in a side-by-side screenshot of two chatbot interactions:
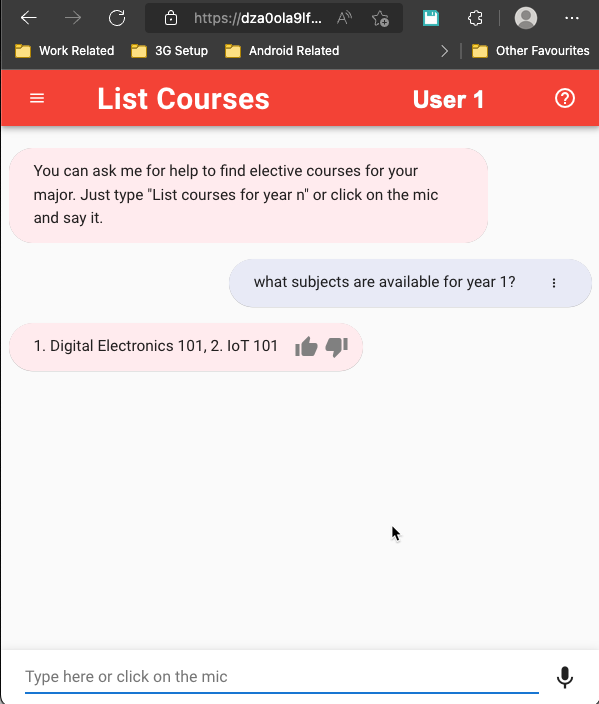{kind=link}
{kind=link}
Figure 2: Side-by-side comparison of multiple user chat sessions
Cleanup
If you followed along the example setup, then you should clean up any resources you created to avoid additional charges in the long run. To perform a cleanup of the resources, you need to:
Delete the Amazon Kendra index and associated Amazon S3 data source
Delete the Amazon Lex chatbot
Empty the S3 bucket
Delete the S3 bucket
Delete the Lambda function by following the Clean up section.
Delete the lex-web-ui resources by deleting the associated AWS CloudFormation stack
Delete the Amazon Cognito resources
Conclusion
Amazon Kendra is a highly accurate enterprise search service. Combining its natural language processing feature with an intelligent chatbot creates a solution that is robust for any use case needing custom outputs based on user context. Here we considered a sample use case of an organization with multiple departments, but this mechanism can be applied to any other relevant use cases with minimal changes.
Ready to get started? The Accenture AWS Business Group (AABG) helps customers accelerate their pace of digital innovation and realize incremental business value from cloud adoption and transformation. Connect with our team at [email protected] to learn how to build intelligent chatbot solutions for your customers.
About the Author
Rohit Satyanarayana is a Partner Solutions Architect at AWS in Singapore and is part of the AWS GSI team working with Accenture globally. His hobbies are reading fantasy and science fiction, watching movies and listening to music.
{kind=link}
Leo An is a Senior Solutions Architect who has demonstrated the ability to design and deliver cost-effective, high-performance infrastructure solutions in a private and public cloud. He enjoys helping customers in using cloud technologies to address their business challenges and is specialized in machine learning and is focused on helping customers leverage AI/ML for their business outcomes.
{kind=link}
Hemalatha Katari is a Solution Architect at Accenture. She is part of rapid prototyping team within the Accenture AWS Business Group (AABG). She helps organizations migrate and run their businesses in AWS cloud. She enjoys growing ornamental indoor plants and loves going for long nature trail walks.
{kind=link}
Sruthi Mamidipalli is an AWS solutions architect at Accenture, where she is helping clients with successful adoption of cloud native architecture. Outside of work, she loves gardening, cooking, and spending time with her toddler.
{kind=link}
Read MoreAWS Machine Learning Blog