

{kind=link}
In Part 1 of this series, we showed how to build a brand detection solution using Amazon SageMaker Ground Truth and Amazon Rekognition Custom Labels. The solution was built on a serverless architecture with a custom user interface to identify a company brand or logo from video content and get an in-depth view of screen time for a given company brand or logo.
In this post, we discuss how the solution architecture is designed and how to implement each step.
This is the second in a two-part series on using Amazon Machine Learning services to build a brand detection solution.
Part 1 – End-to-end solution
Part 2 – Training and analysis workflows
Solution overview
Let’s recap the overall architecture, where we have two main workflows: an AWS Step Functions training state machine that manages the dataset preparation, data labeling, and training an Amazon Rekognition Custom Labels model; and an analysis state machine that handles media file upload, frame extraction from the video file, managing the Amazon Rekognition Custom Labels model runtime, and running predictions.
{kind=link}
Training state machine
When you start a new training job by uploading media files (images or videos), the web application sends an API request to start the training workflow by running the Step Functions training state machine.
{kind=link}
Let’s explore the backend of the training state machine.
The training state machine consists several states and can be grouped into probing, frame extraction, data labeling, and model training stages.
State machine run input parameter
To start the training state machine, the input parameter contains the project name, the type of training, location of the training media files, and a set of labels you want to train. The type of training can be object or concept. The former refers to an object detection model; the latter refers to image classification model.
Stage: Probing
The Probe video (Preproc) and Probe video states read each input video file to extract the keyframe information that are used for the frame extraction later. To reduce processing time, we parallelize the probing logic by running each video file in its own branch, the Probe video state. We do this with the Step Functions Map feature.
The Probe video state invokes an AWS Lambda function that uses ffmpeg (ffprobe) to extract the keyframe (I-frame) information of the video file. It then stores the output in JSON format to an Amazon Simple Storage Service (Amazon S3) bucket such that other states can reference it.
The following code is the ffprobe command:
The following code is the JSON result:
The JSON output provides the timestamp and frame number of each keyframe in the video file, which is used to perform the actual frame extraction later.
Stage: Frame extraction
The Extract keyframes (Preproc) and Extract keyframes states perform the actual frame extraction from the video file. The image frames are used as our training and validation dataset later. Once again, it uses the Step Function Map feature to parallelize the process to reduce the processing time.
The Extract keyframes state invokes a Lambda function that uses the ffmpeg tool to extract specific frames and stores the frames in the S3 bucket:
Stage: Data labeling
The Prepare labeling job state takes the extracted frames and prepares the following files: frame sequence files, a dataset manifest, and a label configuration file that are required to start a Ground Truth labeling job. The demo solution supports two built-in task types: video frame object detection and image classification. Check out a full list of built-in task types supported by Ground Truth.
A frame sequence JSON file contains a list of image frames extracted from one video file. If you upload two video files for training, you have two frame sequence files.
The following code is the frame sequence JSON file:
A dataset manifest file then contains the location of each frame sequence JSON file:
A label configuration file contains the label definitions and instructions for the labelers:
Now that we have our dataset ready for labeling, we can create a labeling job with Ground Truth and wait for the labelers to complete the labeling task. The following code snippet depicts how to create a labeling job. For more detail about the parameters, check out CreateLabelingJob API.
As this point, a labeling job is created and the state machine needs to wait for the labelers to finish the labeling job. However, you may have noticed that the training state machine doesn’t contain any state to periodically pull and check the status of the labeling job. So, how does the state machine know when the labeling job is completed?
This is achieved by using the Step Functions service integration and Amazon CloudWatch Events of the Ground Truth labeling job status, an event-driven approach that allows us to pause the state machine and resume when the labeling job is finished.
The following diagram illustrates how this asynchronous wait operation works.
{kind=link}
First of all, in the Start and wait labeling job state definition, we declare the resource as arn:aws:states:::lambda:invoke.waitForTaskToken. This tells the state machine to run the Lambda function but to not exit the state when the function returns. Instead, the state should wait for a task result from an external process. We pass in an uniquely generated task token to the function by specifying Parameters.Payload.token.$ ($$.Task.Token). See the following code:
In Step 1 and 2 denoted in the preceding diagram, the Lambda function gets the input parameters along with the task token from the event object. It then starts a new labeling job by calling the sagemaker.createLabelingJob API and stores the following information to Amazon DynamoDB:
The labeling job ID served as a primary key to look up
The task token required to send the task result back to the state machine run
The state input parameters passed back to the state machine run, serving as the output of the state
In Steps 3–6, we create a CloudWatch Events rule to listen to the SageMaker Ground Truth Labeling Job State Change event (see the following event pattern). When the labeling job is completed, Ground Truth emits a job state change event to the CloudWatch event. The event rule invokes our status updater Lambda function, which fetches the task token from the DynamoDB table and sends the task result back to state machine by calling StepFunctions.sendTaskSuccess or StepFunctions.sendTaskFailure. When the state receives the task result, it completes the asynchronous wait and moves to the next state.
The following code is the event pattern of the CloudWatch event rule:
After the labeling job is complete, the Collect annotation state consolidates the annotations and prepares the training dataset manifest file for training our Amazon Rekognition Custom Labels model.
Stage: Model training
The Start and wait for custom label state invokes a sub state machine, custom-labels-training-job, and waits for it to complete using the Step Functions nested workflow technique. To do that, we declare the state resource as arn:aws:states:::states:startExectuion.sync and provide the ARN of the sub state machine:
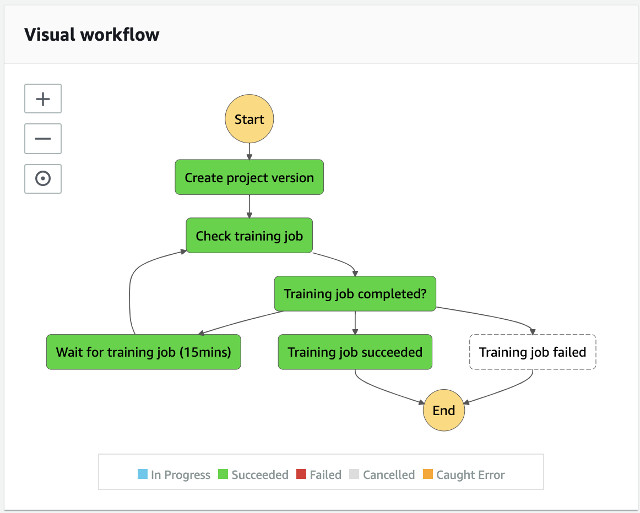
The following diagram presents the Amazon Rekognition Custom Labels model training state machine workflow.
{kind=link}
To train a model using Amazon Rekognition Custom Labels, the Create project version state first creates a project where it manages the model files. After a project is created, it creates a project version (model) to start the training process. The training dataset comes from the consolidated annotations of the Ground Truth labeling job. The Check training job and Wait for training job (15 mins) states periodically check the training status until the model is fully trained.
When this workflow is complete, the result is returned to the parent state machine such that the parent run can continue the next state.
Analysis state machine
The Amazon Rekognition Custom Labels start model state machine manages the runtime of the Amazon Rekognition Custom Labels model. It’s a nested workflow used by the video analysis state machine.
The following diagram presents the start model state machine.
{kind=link}
In this workflow, the input parameter to start an Amazon Rekognition Custom Labels model state machine is a pass through from the video analysis state machine. It starts with the checking model status if the model is started, otherwise it waits 3 minutes and checks again. When the model starts, it can now start a new project version.
Video analysis state machine
The video analysis state machine is composed of different states:
Probe video to gather frame information of a given video file.
Extract keyframes to extract frames from the video.
Start and wait the custom labels model to ensure that the model is running.
Detect custom labels to run predictions.
Create sprite images to create a sprite image for the web user interface.
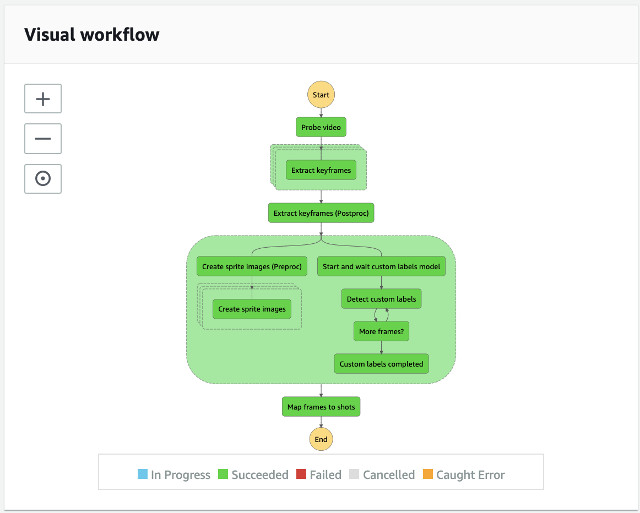
The following diagram presents the video analysis state machine.
{kind=link}
In this workflow, the Probe video state prepares a list of iterations for the next state, Extract keyframes, to achieve parallel processing using the Step Functions Map feature. It allows us to optimize for speed by parallelly extracting frames from the input video file.
In the Extract keyframe step, each iterator is given an input specifying the video file, the location of the frame information, the numbers of frames to extract from the video, and the start location of the video to extract frames. With this information, the Extract keyframe state can start processing to consolidate the results from the previous map state.
In next step, it waits for the custom labels model to start. When the model is started in the Detect custom labels state, it analyzes extracted frames from the video file and stores the JSON result to the S3 source bucket until there are no more frames to process, then it ends this parallel branch in the workflow. In another parallel branch, it creates a sprite image for every minute of the video file for the web user interface to display frames. The Create sprite images (Preproc) and Create sprite images states are used to slice and compile sprite images for the video. The Create sprite images (Preproc) state prepares a list of iterations for the next state, Create sprite images, to achieve parallel processing using the Map feature.
Conclusion
You can build an Amazon Rekognition model with little or no machine learning expertise. In the first post of this series, we demonstrated how to use Amazon Rekognition Custom Labels to detect brand logos in images and videos. In this post, we did a deep dive into data labeling from a video file using Ground Truth to prepare the data for the training phase. We also explained the technical details of how we use Amazon Rekognition Custom Labels to train the model, and demonstrated the inference phase and how you can collect a set of statistics for your brand visibility in a given video file.
For more information about the code sample in this post, see the GitHub repo.
About the Authors
Ken Shek is a Global Vertical Solutions Architect, Media and Entertainment in the EMEA region. He helps media customers design, develop, and deploy workloads onto the AWS Cloud using AWS Cloud best practices. Ken graduated from University of California, Berkeley, and received his master’s degree in Computer Science at Northwestern Polytechnical University.
{kind=link}
Amit Mukherjee is a Sr. Partner Solutions Architect with a focus on Data Analytics and AI/ML. He works with AWS Partners and customers to provide them with architectural guidance for building highly secure scalable data analytics platforms and adopting machine learning at a large scale.
{kind=link}
Sameer Goel is a Solutions Architect in Netherlands, who drives customer success by building prototypes on cutting-edge initiatives. Prior to joining AWS, Sameer graduated with a master’s degree from NEU Boston, with a Data Science concentration. He enjoys building and experimenting with creative projects and applications.
{kind=link}
Read MoreAWS Machine Learning Blog