

{kind=link}
This is the second part of a series that showcases the machine learning (ML) lifecycle with a data mesh design pattern for a large enterprise with multiple lines of business (LOBs) and a Center of Excellence (CoE) for analytics and ML.
In part 1, we addressed the data steward persona and showcased a data mesh setup with multiple AWS data producer and consumer accounts. For an overview of the business context and the steps to set up a data mesh with AWS Lake Formation and register a data product, refer to part 1.
In this post, we address the analytics and ML platform team as a consumer in the data mesh. The platform team sets up the ML environment for the data scientists and helps them get access to the necessary data products in the data mesh. The data scientists in this team use Amazon SageMaker to build and train a credit risk prediction model using the shared credit risk data product from the consumer banking LoB.
Build and train ML models using a data mesh architecture on AWS
Part 1: Data mesh set up and data product registration
Part 2: Data product consumption by Analytics and ML CoE
The code for this example is available on GitHub.
Analytics and ML consumer in a data mesh architecture
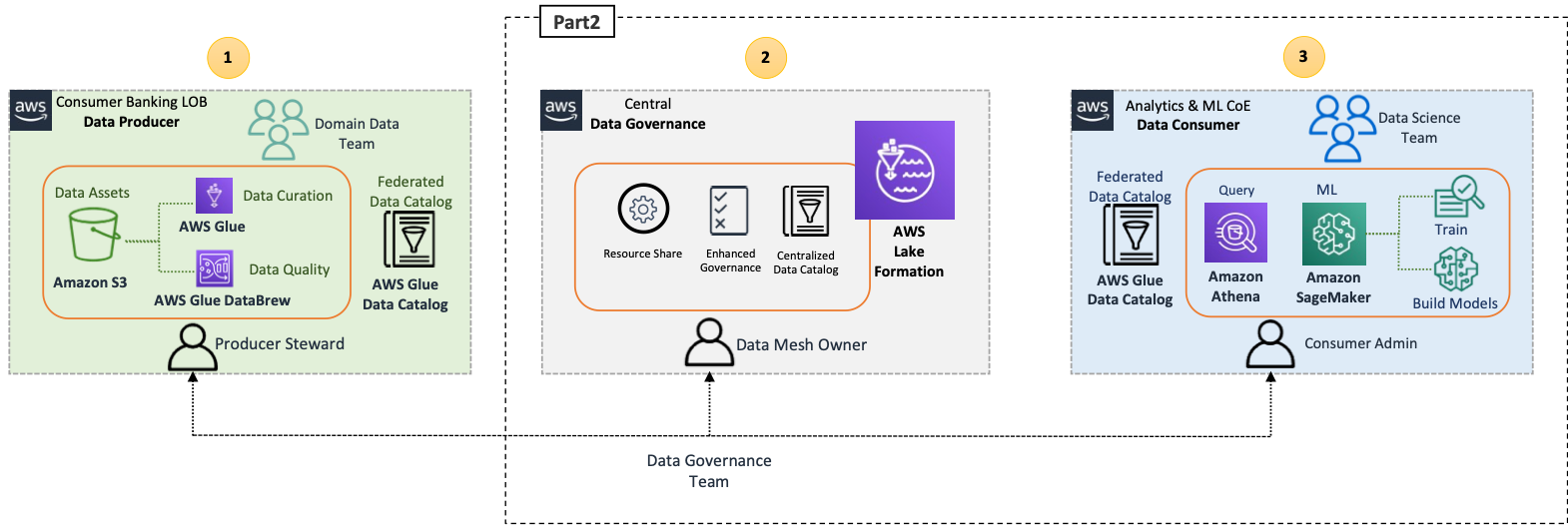
Let’s recap the high-level architecture that highlights the key components in the data mesh architecture.
{kind=link}
In the data producer block 1 (left), there is a data processing stage to ensure that shared data is well-qualified and curated. The central data governance block 2 (center) acts as a centralized data catalog with metadata of various registered data products. The data consumer block 3 (right) requests access to datasets from the central catalog and queries and processes the data to build and train ML models.
With SageMaker, data scientists and developers in the ML CoE can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. SageMaker provides easy access to your data sources for exploration and analysis, and also provides common ML algorithms and frameworks that are optimized to run efficiently against extremely large data in a distributed environment. It’s easy to get started with Amazon SageMaker Studio, a web-based integrated development environment (IDE), by completing the SageMaker domain onboarding process. For more information, refer to the Amazon SageMaker Developer Guide.
Data product consumption by the analytics and ML CoE
The following architecture diagram describes the steps required by the analytics and ML CoE consumer to get access to the registered data product in the central data catalog and process the data to build and train an ML model.
{kind=link}
The workflow consists of the following components:
The producer data steward provides access in the central account to the database and table to the consumer account. The database is now reflected as a shared database in the consumer account.
The consumer admin creates a resource link in the consumer account to the database shared by the central account. The following screenshot shows an example in the consumer account, with rl_credit-card being the resource link of the credit-card database.
The consumer admin provides the Studio AWS Identity and Access Management (IAM) execution role access to the resource linked database and the table identified in the Lake Formation tag. In the following example, the consumer admin provided to the SageMaker execution role has permission to access rl_credit-card and the table satisfying the Lake Formation tag expression.
Once assigned an execution role, data scientists in SageMaker can use Amazon Athena to query the table via the resource link database in Lake Formation.
For data exploration, they can use Studio notebooks to process the data with interactive querying via Athena.
For data processing and feature engineering, they can run SageMaker processing jobs with an Athena data source and output results back to Amazon Simple Storage Service (Amazon S3).
After the data is processed and available in Amazon S3 on the ML CoE account, data scientists can use SageMaker training jobs to train models and SageMaker Pipelines to automate model-building workflows.
Data scientists can also use the SageMaker model registry to register the models.
{kind=link}
{kind=link}
{kind=link}
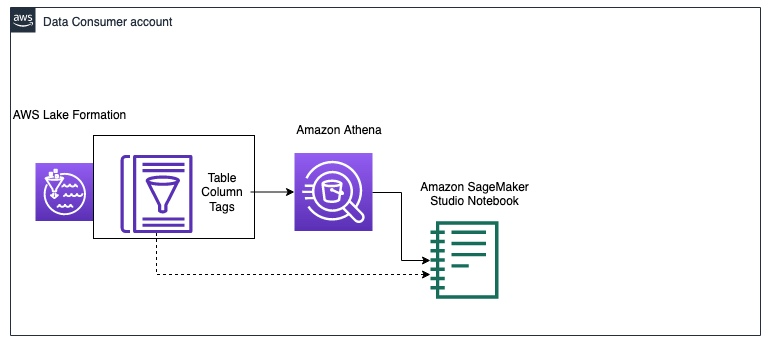
Data exploration
The following diagram illustrates the data exploration workflow in the data consumer account.
{kind=link}
The consumer starts by querying a sample of the data from the credit_risk table with Athena in a Studio notebook. When querying data via Athena, the intermediate results are also saved in Amazon S3. You can use the AWS Data Wrangler library to run a query on Athena in a Studio notebook for data exploration. The following code example shows how to query Athena to fetch the results as a dataframe for data exploration:
Now that you have a subset of the data as a dataframe, you can start exploring the data and see what feature engineering updates are needed for model training. An example of data exploration is shown in the following screenshot.
{kind=link}
When you query the database, you can see the access logs from the Lake Formation console, as shown in the following screenshot. These logs give you information about who or which service has used Lake Formation, including the IAM role and time of access. The screenshot shows a log about SageMaker accessing the table credit_risk in AWS Glue via Athena. In the log, you can see the additional audit context that contains the query ID that matches the query ID in Athena.
{kind=link}
The following screenshot shows the Athena query run ID that matches the query ID from the preceding log. This shows the data accessed with the SQL query. You can see what data has been queried by navigating to the Athena console, choosing the Recent queries tab, and then looking for the run ID that matches the query ID from the additional audit context.
{kind=link}
Data processing
After data exploration, you may want to preprocess the entire large dataset for feature engineering before training a model. The following diagram illustrates the data processing procedure.
{kind=link}
In this example, we use a SageMaker processing job, in which we define an Athena dataset definition. The processing job queries the data via Athena and uses a script to split the data into training, testing, and validation datasets. The results of the processing job are saved to Amazon S3. To learn how to configure a processing job with Athena, refer to Use Amazon Athena in a processing job with Amazon SageMaker.
In this example, you can use the Python SDK to trigger a processing job with the Scikit-learn framework. Before triggering, you can configure the inputs parameter to get the input data via the Athena dataset definition, as shown in the following code. The dataset contains the location to download the results from Athena to the processing container and the configuration for the SQL query. When the processing job is finished, the results are saved in Amazon S3.
Model training and model registration
After preprocessing the data, you can train the model with the preprocessed data saved in Amazon S3. The following diagram illustrates the model training and registration process.
{kind=link}
For data exploration and SageMaker processing jobs, you can retrieve the data in the data mesh via Athena. Although the SageMaker Training API doesn’t include a parameter to configure an Athena data source, you can query data via Athena in the training script itself.
In this example, the preprocessed data is now available in Amazon S3 and can be used directly to train an XGBoost model with SageMaker Script Mode. You can provide the script, hyperparameters, instance type, and all the additional parameters needed to successfully train the model. You can trigger the SageMaker estimator with the training and validation data in Amazon S3. When the model training is complete, you can register the model in the SageMaker model registry for experiment tracking and deployment to a production account.
Next steps
You can make incremental updates to the solution to address requirements around data updates and model retraining, automatic deletion of intermediate data in Amazon S3, and integrating a feature store. We discuss each of these in more detail in the following sections.
Data updates and model retraining triggers
The following diagram illustrates the process to update the training data and trigger model retraining.
{kind=link}
The process includes the following steps:
The data producer updates the data product with either a new schema or additional data at a regular frequency.
After the data product is re-registered in the central data catalog, this generates an Amazon CloudWatch event from Lake Formation.
The CloudWatch event triggers an AWS Lambda function to synchronize the updated data product with the consumer account. You can use this trigger to reflect the data changes by doing the following:
Rerun the AWS Glue crawler.
Trigger model retraining if the data drifts beyond a given threshold.
For more details about setting up an SageMaker MLOps deployment pipeline for drift detection, refer to the Amazon SageMaker Drift Detection GitHub repo.
Auto-deletion of intermediate data in Amazon S3
You can automatically delete intermediate data that is generated by Athena queries and stored in Amazon S3 in the consumer account at regular intervals with S3 object lifecycle rules. For more information, refer to Managing your storage lifecycle.
SageMaker Feature Store integration
SageMaker Feature Store is purpose-built for ML and can store, discover, and share curated features used in training and prediction workflows. A feature store can work as a centralized interface between different data producer teams and LoBs, enabling feature discoverability and reusability to multiple consumers. The feature store can act as an alternative to the central data catalog in the data mesh architecture described earlier. For more information about cross-account architecture patterns, refer to Enable feature reuse across accounts and teams using Amazon SageMaker Feature Store.
Refer to the MLOps foundation roadmap for enterprises with Amazon SageMaker blog post to find out more about building an MLOps foundation based on the MLOps maturity model.
Conclusion
In this two-part series, we showcased how you can build and train ML models with a multi-account data mesh architecture on AWS. We described the requirements of a typical financial services organization with multiple LoBs and an ML CoE, and illustrated the solution architecture with Lake Formation and SageMaker. We used the example of a credit risk data product registered in Lake Formation by the consumer banking LoB and accessed by the ML CoE team to train a credit risk ML model with SageMaker.
Each data producer account defines data products that are curated by people who understand the data and its access control, use, and limitations. The data products and the application domains that consume them are interconnected to form the data mesh. The data mesh architecture allows the ML teams to discover and access these curated data products.
Lake Formation allows cross-account access to Data Catalog metadata and underlying data. You can use Lake Formation to create a multi-account data mesh architecture. SageMaker provides an ML platform with key capabilities around data management, data science experimentation, model training, model hosting, workflow automation, and CI/CD pipelines for productionization. You can set up one or more analytics and ML CoE environments to build and train models with data products registered across multiple accounts in a data mesh.
Try out the AWS CloudFormation templates and code from the example repository to get started.
About the authors
Karim Hammouda is a Specialist Solutions Architect for Analytics at AWS with a passion for data integration, data analysis, and BI. He works with AWS customers to design and build analytics solutions that contribute to their business growth. In his free time, he likes to watch TV documentaries and play video games with his son.
{kind=link}
Hasan Poonawala is a Senior AI/ML Specialist Solutions Architect at AWS, Hasan helps customers design and deploy machine learning applications in production on AWS. He has over 12 years of work experience as a data scientist, machine learning practitioner, and software developer. In his spare time, Hasan loves to explore nature and spend time with friends and family.
{kind=link}
Benoit de Patoul is an AI/ML Specialist Solutions Architect at AWS. He helps customers by providing guidance and technical assistance to build solutions related to AI/ML using AWS. In his free time, he likes to play piano and spend time with friends.
{kind=link}
Read MoreAWS Machine Learning Blog