

{kind=link}
This is Part 3 of our series where we design and implement an MLOps pipeline for visual quality inspection at the edge. In this post, we focus on how to automate the edge deployment part of the end-to-end MLOps pipeline. We show you how to use AWS IoT Greengrass to manage model inference at the edge and how to automate the process using AWS Step Functions and other AWS services.
Solution overview
In Part 1 of this series, we laid out an architecture for our end-to-end MLOps pipeline that automates the entire machine learning (ML) process, from data labeling to model training and deployment at the edge. In Part 2, we showed how to automate the labeling and model training parts of the pipeline.
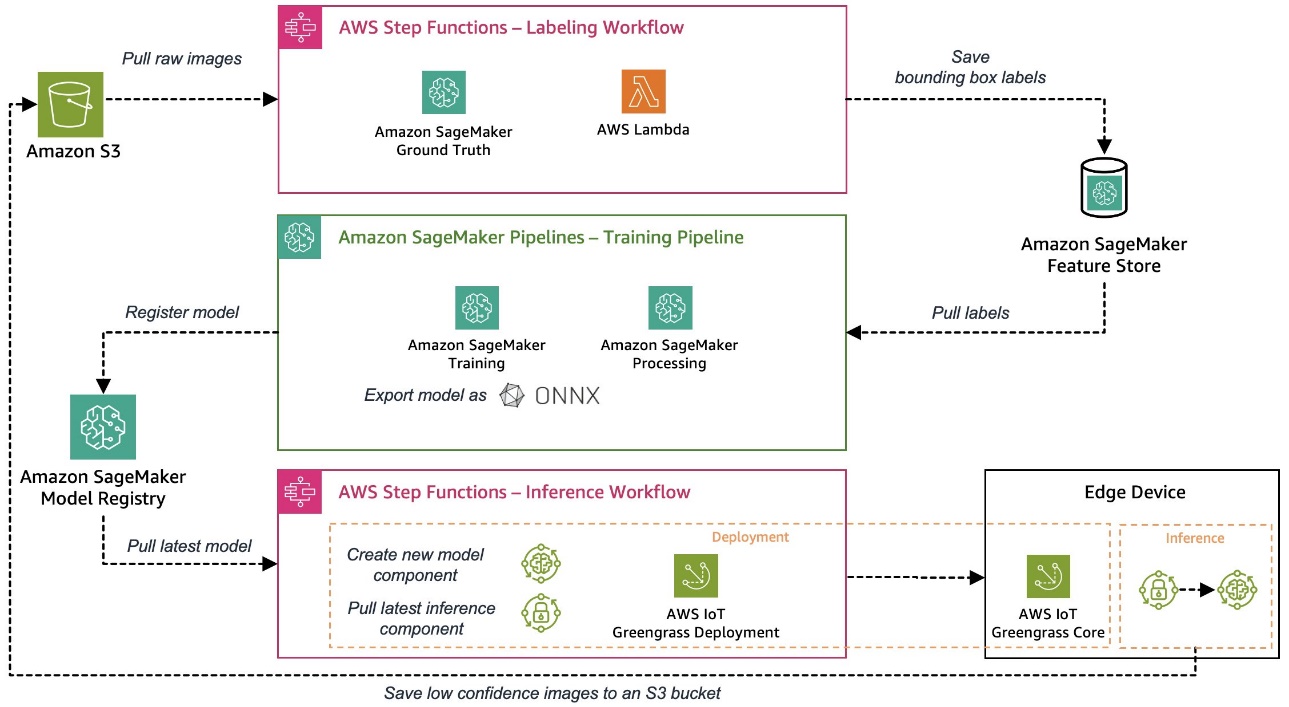
The sample use case used for this series is a visual quality inspection solution that can detect defects on metal tags, which you can deploy as part of a manufacturing process. The following diagram shows the high-level architecture of the MLOps pipeline we defined in the beginning of this series. If you haven’t read it yet, we recommend checking out Part 1.
{kind=link}
Automating the edge deployment of an ML model
After an ML model has been trained and evaluated, it needs to be deployed to a production system to generate business value by making predictions on incoming data. This process can quickly become complex in an edge setting where models need to be deployed and run on devices that are often located far away from the cloud environment in which the models have been trained. The following are some of the challenges unique to machine learning at the edge:
ML models often need to be optimized due to resource constraints on edge devices
Edge devices can’t be redeployed or even replaced like a server in the cloud, so you need a robust model deployment and device management process
Communication between devices and the cloud needs to be efficient and secure because it often traverses untrusted low-bandwidth networks
Let’s see how we can tackle these challenges with AWS services in addition to exporting the model in the ONNX format, which allows us to, for example, apply optimizations like quantization to reduce the model size for constraint devices. ONNX also provides optimized runtimes for the most common edge hardware platforms.
Breaking the edge deployment process down, we require two components:
A deployment mechanism for the model delivery, which includes the model itself and some business logic to manage and interact with the model
A workflow engine that can orchestrate the whole process to make this robust and repeatable
In this example, we use different AWS services to build our automated edge deployment mechanism, which integrates all the required components we discussed.
Firstly, we simulate an edge device. To make it straightforward for you to go through the end-to-end workflow, we use an Amazon Elastic Compute Cloud (Amazon EC2) instance to simulate an edge device by installing the AWS IoT Greengrass Core software on the instance. You can also use EC2 instances to validate the different components in a QA process before deploying to an actual edge production device. AWS IoT Greengrass is an Internet of Things (IoT) open-source edge runtime and cloud service that helps you build, deploy, and manage edge device software. AWS IoT Greengrass reduces the effort to build, deploy, and manage edge device software in a secure and scalable way. After you install the AWS IoT Greengrass Core software on your device, you can add or remove features and components, and manage your IoT device applications using AWS IoT Greengrass. It offers a lot of built-in components to make your life easier, such as the StreamManager and MQTT broker components, which you can use to securely communicate with the cloud, supporting end-to-end encryption. You can use those features to upload inference results and images efficiently.
In a production environment, you would typically have an industrial camera delivering images for which the ML model should produce predictions. For our setup, we simulate this image input by uploading a preset of images into a specific directory on the edge device. We then use these images as inference input for the model.
We divided the overall deployment and inference process into three consecutive steps to deploy a cloud-trained ML model to an edge environment and use it for predictions:
Prepare – Package the trained model for edge deployment.
Deploy – Transfer of model and inference components from the cloud to the edge device.
Inference – Load the model and run inference code for image predictions.
The following architecture diagram shows the details of this three-step process and how we implemented it with AWS services.
{kind=link}
In the following sections, we discuss the details for each step and show how to embed this process into an automated and repeatable orchestration and CI/CD workflow for both the ML models and corresponding inference code.
Prepare
Edge devices often come with limited compute and memory compared to a cloud environment where powerful CPUs and GPUs can run ML models easily. Different model-optimization techniques allow you to tailor a model for a specific software or hardware platform to increase prediction speed without losing accuracy.
In this example, we exported the trained model in the training pipeline to the ONNX format for portability, possible optimizations, as well as optimized edge runtimes, and registered the model within Amazon SageMaker Model Registry. In this step, we create a new Greengrass model component including the latest registered model for subsequent deployment.
Deploy
A secure and reliable deployment mechanism is key when deploying a model from the cloud to an edge device. Because AWS IoT Greengrass already incorporates a robust and secure edge deployment system, we’re using this for our deployment purposes. Before we look at our deployment process in detail, let’s do a quick recap on how AWS IoT Greengrass deployments work. At the core of the AWS IoT Greengrass deployment system are components, which define the software modules deployed to an edge device running AWS IoT Greengrass Core. These can either be private components that you build or public components that are provided either by AWS or the broader Greengrass community. Multiple components can be bundled together as part of a deployment. A deployment configuration defines the components included in a deployment and the deployment’s target devices. It can either be defined in a deployment configuration file (JSON) or via the AWS IoT Greengrass console when creating a new deployment.
We create the following two Greengrass components, which are then deployed to the edge device via the deployment process:
Packaged model (private component) – This component contains the trained and ML model in ONNX format.
Inference code (private component) – Aside from the ML model itself, we need to implement some application logic to handle tasks like data preparation, communication with the model for inference, and postprocessing of inference results. In our example, we’ve developed a Python-based private component to handle the following tasks:
Install the required runtime components like the Ultralytics YOLOv8 Python package.
Instead of taking images from a camera live stream, we simulate this by loading prepared images from a specific directory and preparing the image data according to the model input requirements.
Make inference calls against the loaded model with the prepared image data.
Check the predictions and upload inference results back to the cloud.
If you want to have a deeper look at the inference code we built, refer to the GitHub repo.
Inference
The model inference process on the edge device automatically starts after deployment of the aforementioned components is finished. The custom inference component periodically runs the ML model with images from a local directory. The inference result per image returned from the model is a tensor with the following content:
Confidence scores – How confident the model is regarding the detections
Object coordinates – The scratch object coordinates (x, y, width, height) detected by the model in the image
In our case, the inference component takes care of sending inference results to a specific MQTT topic on AWS IoT where it can be read for further processing. These messages can be viewed via the MQTT test client on the AWS IoT console for debugging. In a production setting, you can decide to automatically notify another system that takes care of removing faulty metal tags from the production line.
Orchestration
As seen in the preceding sections, multiple steps are required to prepare and deploy an ML model, the corresponding inference code, and the required runtime or agent to an edge device. Step Functions is a fully managed service that allows you to orchestrate these dedicated steps and design the workflow in the form of a state machine. The serverless nature of this service and native Step Functions capabilities like AWS service API integrations allow you to quickly set up this workflow. Built-in capabilities like retries or logging are important points to build robust orchestrations. For more details regarding the state machine definition itself, refer to the GitHub repository or check the state machine graph on the Step Functions console after you deploy this example in your account.
Infrastructure deployment and integration into CI/CD
The CI/CD pipeline to integrate and build all the required infrastructure components follows the same pattern illustrated in Part 1 of this series. We use the AWS Cloud Development Kit (AWS CDK) to deploy the required pipelines from AWS CodePipeline.
{kind=link}
Learnings
There are multiple ways to build an architecture for an automated, robust, and secure ML model edge deployment system, which are often very dependent on the use case and other requirements. However, here a few learnings we would like to share with you:
Evaluate in advance if the additional AWS IoT Greengrass compute resource requirements fit your case, especially with constrained edge devices.
Establish a deployment mechanism that integrates a verification step of the deployed artifacts before running on the edge device to ensure that no tampering happened during transmission.
It’s good practice to keep the deployment components on AWS IoT Greengrass as modular and self-contained as possible to be able to deploy them independently. For example, if you have a relatively small inference code module but a big ML model in terms of size, you don’t always want to the deploy them both if just the inference code has changed. This is especially important when you have limited bandwidth or high cost edge device connectivity.
Conclusion
This concludes our three-part series on building an end-to-end MLOps pipeline for visual quality inspection at the edge. We looked at the additional challenges that come with deploying an ML model at the edge like model packaging or complex deployment orchestration. We implemented the pipeline in a fully automated way so we can put our models into production in a robust, secure, repeatable, and traceable fashion. Feel free to use the architecture and implementation developed in this series as a starting point for your next ML-enabled project. If you have any questions how to architect and build such a system for your environment, please reach out. For other topics and use cases, refer to our Machine Learning and IoT blogs.
About the authors
Michael Roth is a Senior Solutions Architect at AWS supporting Manufacturing customers in Germany to solve their business challenges through AWS technology. Besides work and family he’s interested in sports cars and enjoys Italian coffee.
{kind=link}
Jörg Wöhrle is a Solutions Architect at AWS, working with manufacturing customers in Germany. With a passion for automation, Joerg has worked as a software developer, DevOps engineer, and Site Reliability Engineer in his pre-AWS life. Beyond cloud, he’s an ambitious runner and enjoys quality time with his family. So if you have a DevOps challenge or want to go for a run: let him know.
{kind=link}
Johannes Langer is a Senior Solutions Architect at AWS, working with enterprise customers in Germany. Johannes is passionate about applying machine learning to solve real business problems. In his personal life, Johannes enjoys working on home improvement projects and spending time outdoors with his family.
{kind=link}
Read MoreAWS Machine Learning Blog