

{kind=link}
This is the fifth and final post in a multi-part series about the Kubernetes Resource Model. Check out parts 1, 2, 3, and 4 to learn more.
In part 2 of this series, we learned how the Kubernetes Resource Model works, and how the Kubernetes control plane takes action to ensure that your desired resource state matches the running state.
Up until now, that “running resource state” has existed inside the world of Kubernetes- Pods, for example, run on Nodes inside a cluster. The exception to this is any core Kubernetes resource that depends on your cloud provider. For instance, GKE Services of type Load Balancer depend on Google Cloud network load balancers, and GKE has a Google Cloud-specific controller that will spin up those resources on your behalf.
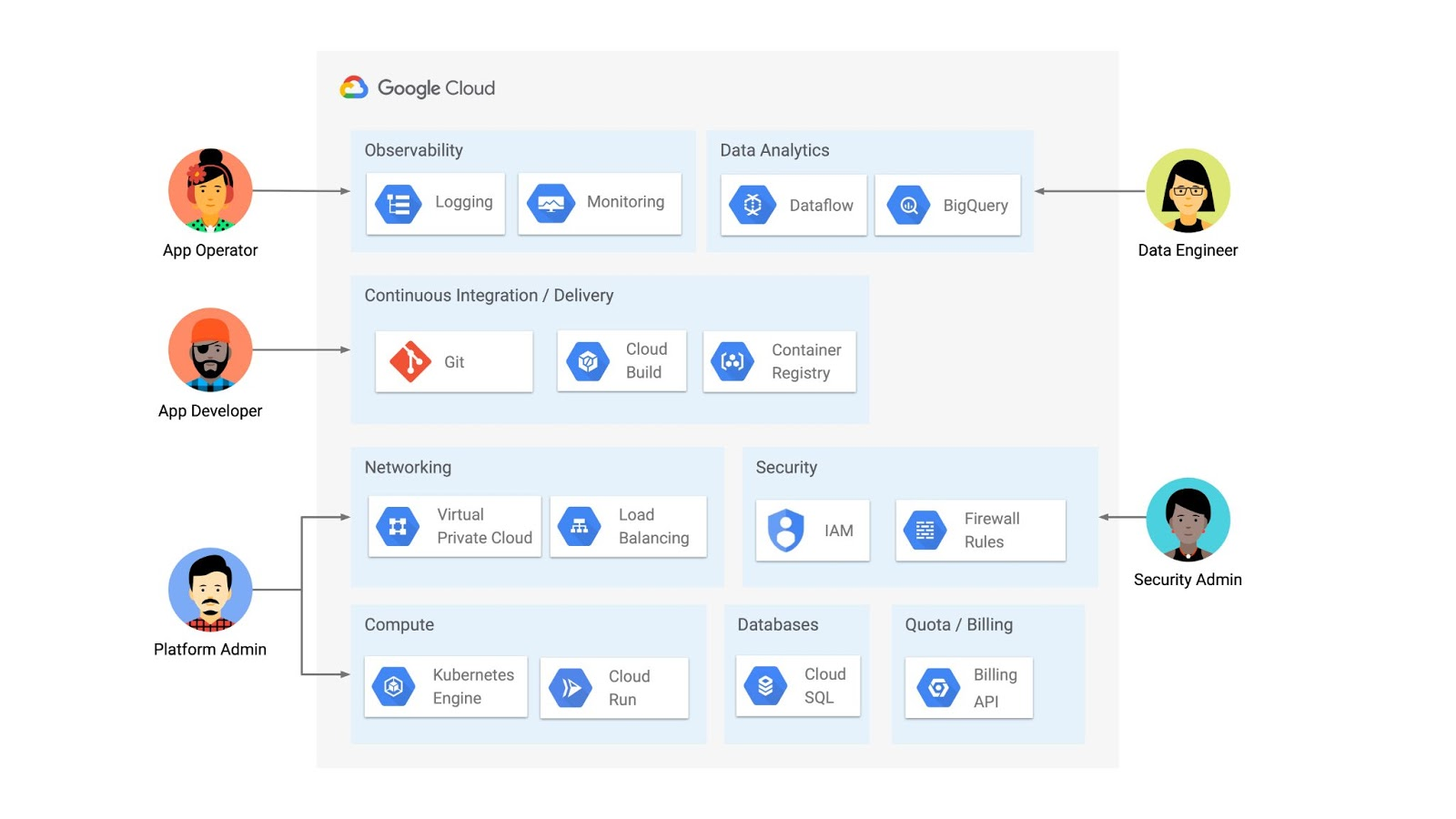
But if you’re operating a Kubernetes platform, it’s likely that you have resources that live entirely outside of Kubernetes. You might have CI/CD triggers, IAM policies, firewall rules, databases. The first post of this series introduced the platform diagram below, and asserted that “Kubernetes can be the powerful declarative control plane that manages large swaths” of that platform. Let’s close that loop by exploring how to use the Kubernetes Resource Model to configure and provision resources hosted in Google Cloud.
{kind=link}
Why use KRM for hosted resources?
Before diving into the “what” and “how” of using KRM for cloud-hosted resources, let’s first ask “why.” There is already an active ecosystem of infrastructure-as-code tools, including Terraform, that can manage cloud-hosted resources. Why use KRM to manage resources outside of the cluster boundary?
Three big reasons. The first is consistency. The last post explored ways to ensure consistency across multiple Kubernetes clusters- but what about consistency between Kubernetes resources and cloud resources? If you have org-wide policies you’d like to enforce on Kubernetes resources, chances are that you also have policies around hosted resources. So one reason to manage cloud resources with KRM is to standardize your infrastructure toolchain, unifying your Kubernetes and cloud resource configuration into one language (YAML), one Git config repo, one policy enforcement mechanism.
The second reason is continuous reconciliation. One major advantage of Kubernetes is its control-loop architecture. So if you use KRM to deploy a hosted firewall rule, Kubernetes will work constantly to make sure that resource is always deployed to your cloud provider- even if it gets manually deleted.
A third reason to consider using KRM for hosted resources is the ability to integrate tools like kustomize into your hosted resource specs, allowing you to customize resource specifications without templating languages.
These benefits have resulted in a new ecosystem of KRM tools designed to manage cloud-hosted resources, including the Crossplane project, as well as first-party tools from AWS, Azure, and Google Cloud.
Let’s explore how to use Google Cloud Config Connector to manage GCP-hosted resources with KRM.
Introducing Config Connector
Config Connector is a tool designed specifically for managing Google Cloud resources with the Kubernetes Resource Model. It works by installing a set of GCP-specific resource controllers onto your GKE cluster, along with a set of Kubernetes Custom Resources for Google Cloud products, from Cloud DNS to Pub/Sub.
How does it work? Let’s say that a security administrator at Cymbal Bank wants to start working more closely with the platform team to define and test Policy Controller constraints. But they don’t have access to a Linux machine, which is the operating system used by the platform team.
The platform team can address this by manually setting up a Google Compute Engine (GCE) Linux instance for the security admin. But with Config Connector, the platform team can instead create a declarative KRM resource for a GCE instance, commit it to the config repo, and Config Connector will spin up the instance on their behalf.
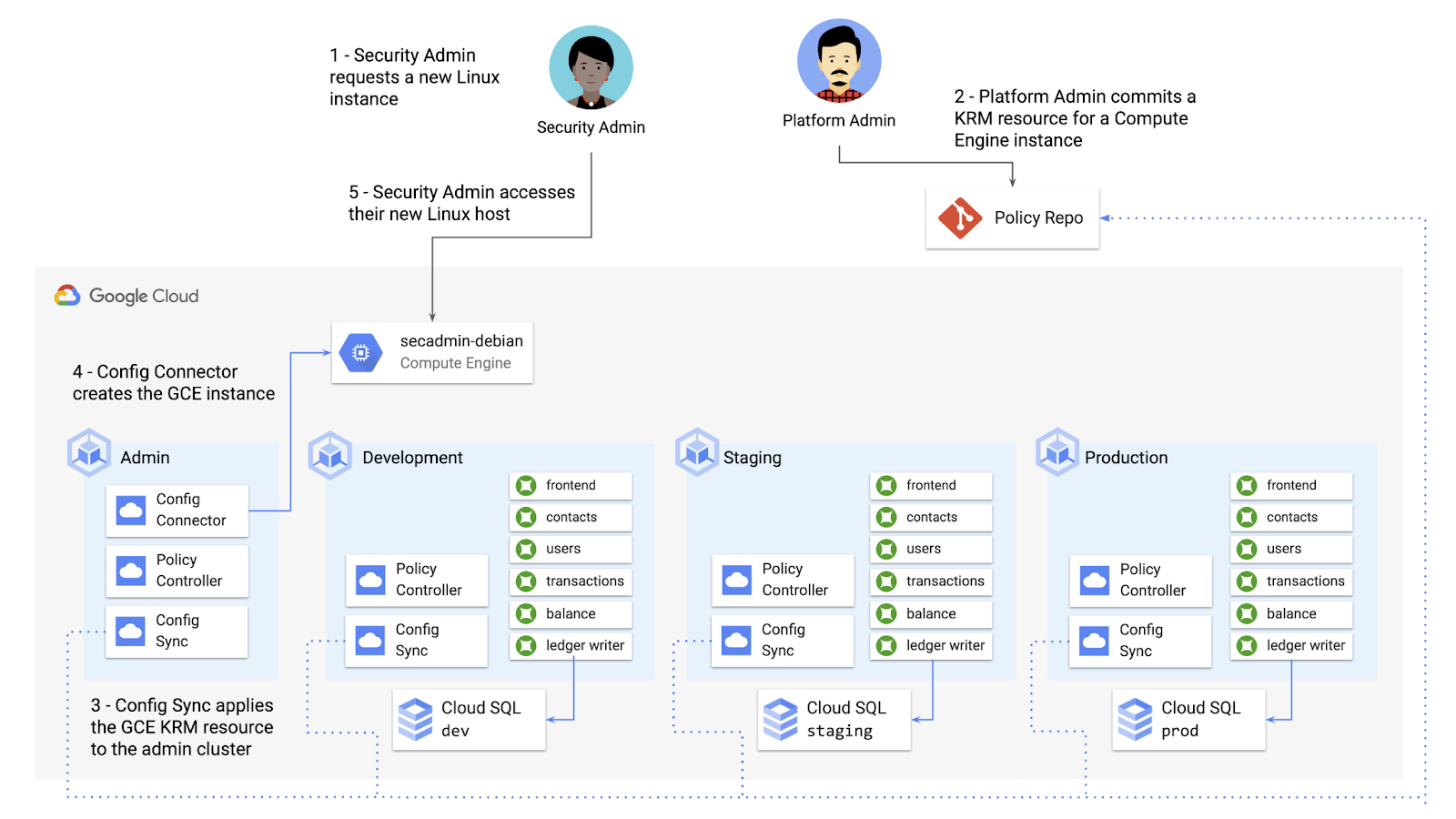{kind=link}
What does this declarative resource look like? A Config Connector resource is just a regular Kubernetes-style YAML file- in this case, a custom resource called Compute Instance. In the resource spec, the platform team can define specific fields, like what GCE machine type to use.
Once the platform team commits this resource to the Config Sync repo, Config Sync will deploy the resource to the cymbal-admin GKE cluster, and Config Connector, running on that same cluster, will spin up the GCE resource represented in the file.
{kind=link}
This KRM workflow for cloud resources opens the door for powerful automation, like custom UIs to automate resource requests within the Cymbal Bank org.
Integrating Config Connector with Policy Controller
By using Config Connector to manage Google Cloud-hosted resources as KRM, you can adopt Policy Controller to enforce guardrails across your cloud and Kubernetes resources.
Let’s say that the data analytics team at Cymbal Bank is beginning to adopt BigQuery. While the security team is approving production usage of that product, the platform team wants to make sure no real customer data is imported. Together, Config Connector and Policy Controller can set up guardrails for BigQuery usage within Cymbal Bank.
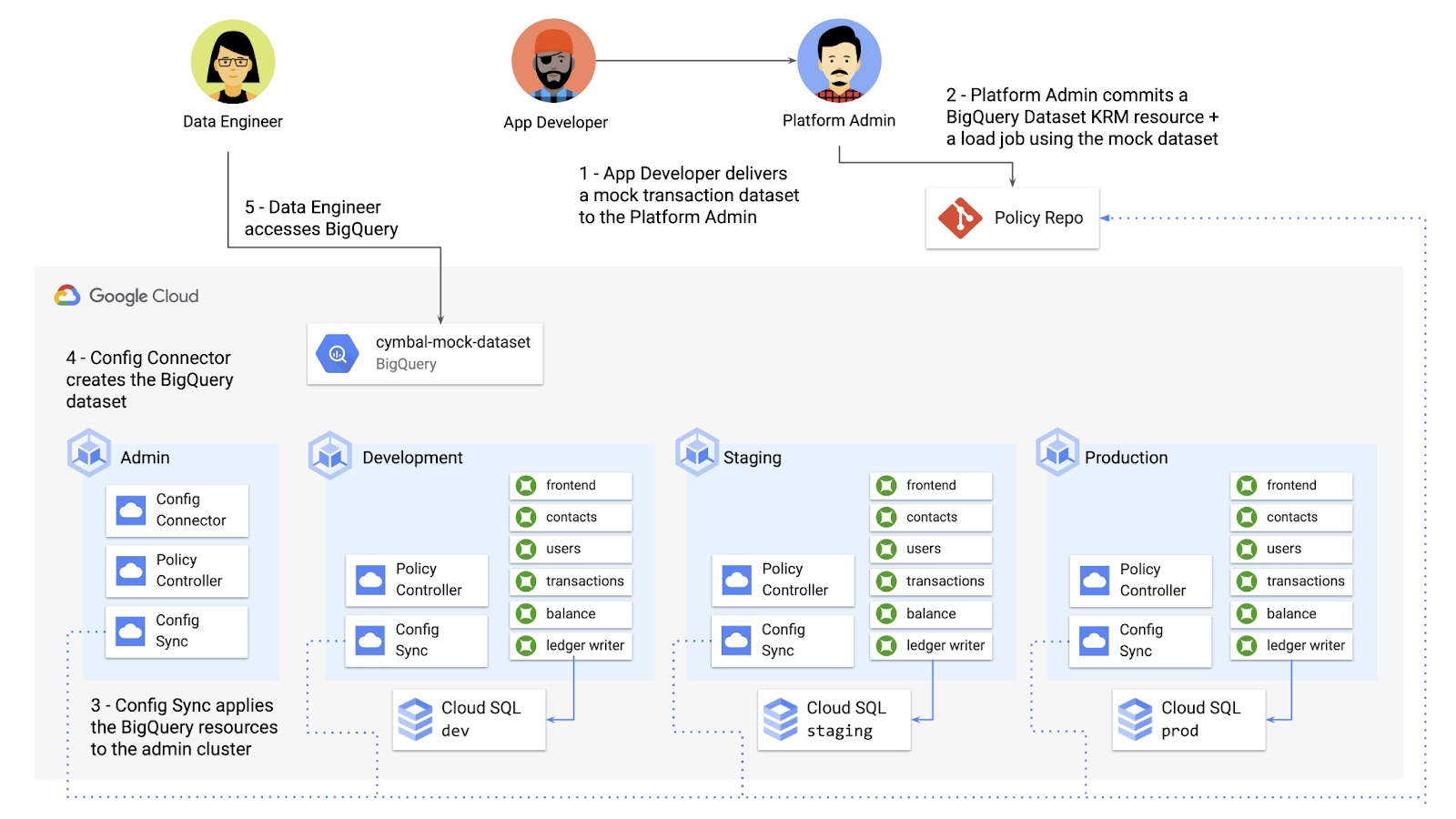{kind=link}
From there, the platform team can create a custom Constraint Template for Policy Controller, limiting the allowed Cymbal datasets to only the pre-vetted mock dataset:
These guardrails, combined with IAM, can allow your organization to adopt new cloud products safely- not only defining who can set up certain resources, but within those resources, what field values are allowed.
Manage existing GCP resources with Config Connector
Another useful feature of Config Connector is that it supports importing existing Google Cloud resources into KRM format, allowing you to bring live-running resources into the management domain of Config Connector.
You can use the config-connector command line tool to do this, exporting specific resource URIs into static files:
Output:
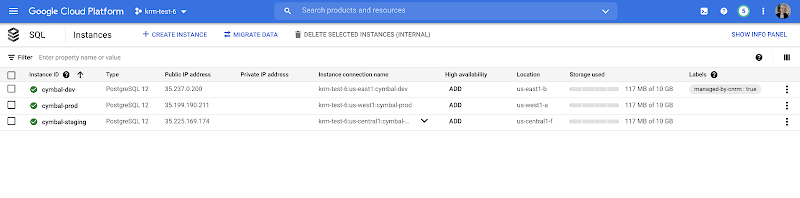
From here, we can push these KRM resources to the config repo, and allow Config Sync and Config Controller to start lifecycling the resources on our behalf. The screenshot below shows that the cymbal-dev Cloud SQL database now has the “managed-by-cnrm” label, indicating that it’s now being managed from Config Connector (CNRM = “cloud-native resource management”).
{kind=link}
This resource export tool is especially useful for teams looking to try out KRM for hosted resources, without having to invest in writing a new set of YAML files for their existing resources. And if you’re ready to adopt Config Connector for lots of existing resources, the tool has a bulk export option as well.
Overall, while managing hosted resources with KRM is still a newer paradigm, it can provide lots of benefits for resource consistency and policy enforcement. Want to try out Config Connector yourself? Check out the part 5 demo.
This post concludes the Build a Platform with KRM series. Hopefully these posts and demos provided some inspiration on how to build a platform around Kubernetes, with the right abstractions and base-layer tools in mind.
Thanks for reading, and stay tuned for new KRM products and features from Google.
Cloud BlogRead More