

{kind=link}
Building accurate computer vision models to detect objects in images requires deep knowledge of each step in the process—from labeling, processing, and preparing the training and validation data, to making the right model choice and tuning the model’s hyperparameters adequately to achieve the maximum accuracy. Fortunately, these complex steps are simplified by Amazon Rekognition Custom Labels, a service of Amazon Rekognition that enables you to build your own custom computer vision models for image classification and object detection tasks without requiring any prior computer vision expertise or advanced programming skills.
In this post, we showcase how we can train a model to detect bees in images using Amazon Rekognition Custom Labels. We also compare these results against a custom-trained TensorFlow model (DIY model). We use Amazon SageMaker as the platform to develop and train our model. Finally, we demonstrate how to build a serverless architecture to process new images using Amazon Rekognition APIs.
When and where to use each model
Before diving deeper, it is important to understand the use cases that drive the decision of which model to use, whether it’s an Amazon Rekognition Custom Labels model or a DIY model.
Amazon Rekognition Custom Labels models are a great choice when our desired goal is to achieve maximum quality results in our task quickly. These models are heavily optimized and fine-tuned to perform at a high accuracy and recall. This is a cloud service, so when the model is trained, images must be uploaded to the cloud to be analyzed. A great advantage of this service is that the user doesn’t need to have expertise to run this training pipeline. You can do it on the AWS Management Console with just a few clicks, and it takes care of the heavy lifting of training and fine-tuning the model for you. Then, a simple set of API calls is offered, tailored to this specific model, for you to apply when needed.
DIY models are the choice for advanced users with expertise in machine learning (ML). They allow you to control every aspect of the model, and tune the training data and the necessary parameters as needed. This requires advanced coding skills. These models trade off accuracy for latency: you can run them faster at the expense of lower qualitative performance. This lower latency fits really well in low bandwidth scenarios where the model needs to be deployed on the edge. For instance, IoT devices that support these models can host and run them and only upload the inference results to the cloud, which reduces the amount of data sent upstream.
Overview of solution
To build our DIY model, we follow the solution from the GitHub repo TensorFlow 2 Object Detection API SageMaker, which consists of these steps:
Download and prepare our bee dataset.
Train the model using a SageMaker custom container instance.
Test the model using a SageMaker model endpoint.
After we have our DIY model, we can proceed with the steps to build our bee detection model using Amazon Rekognition Custom Labels:
Deploy a serverless architecture using AWS CloudFormation.
Download and prepare our bee dataset.
Create a project in Amazon Rekognition Custom Labels and import the dataset.
Train the Amazon Rekognition Custom Labels model.
Test the Amazon Rekognition Custom Labels model using the automatically generated API endpoint using Amazon Simple Storage Service (Amazon S3) events.
Amazon Rekognition Custom Labels lets you manage the ML model training process on the Amazon Rekognition console, which simplifies the end-to-end process. After we train both models, we can compare them.
Set up the environment
We prepare our serverless environment using the CloudFormation template on GitHub. On the AWS CloudFormation console, we create a new stack and use the template.yaml file present in the root folder of our code repository. We provide a unique Amazon Simple Storage Service (Amazon S3) bucket name when prompted, where our images are downloaded for further processing. We also provide a name for the inference processing Amazon Simple Queue Service (Amazon SQS) queue, as well as an AWS Key Management Service (AWS KMS) alias to securely encrypt the inference pipeline.
The architecture diagram is as follows, and it is used for detecting objects in new images as they are uploaded to our bucket.
{kind=link}
Following the first notebook (1_prepare_data), we download and store our images in a bucket in Amazon S3. The dataset is already curated and annotated, and the images used have been licensed under CC0. For convenience, the dataset is stored in a single .zip archive: dataset.zip.
Inside the dataset folder, the manifest file output.manifest contains the bounding box annotations of the dataset. The Amazon S3 references of these images belong to a different S3 bucket where the images were annotated originally. To import this manifest in Amazon Rekognition Custom Labels, the notebook rewrites the manifest file according to the bucket name we chose.
Train your DIY model
To establish a comparison between a DIY and Amazon Rekognition Custom Labels model, we follow the steps in the following public repository that demonstrates how to train a TensorFlow2 model using the same dataset.
We follow the steps described in this repository to train an EfficientNet object detector using our bee dataset. We modify the training notebook so that it runs for 10,000 steps. The model trains for about 2 hours, achieving an average precision of 83% and a recall of 56%.
Create your Amazon Rekognition Custom Labels project
To create your bee detection project, complete the following steps:
On the Amazon Rekognition console, choose Amazon Rekognition Custom Labels.
Choose Get Started.
For Project name, enter bee-detection.
Choose Create project.
{kind=link}
Import your dataset
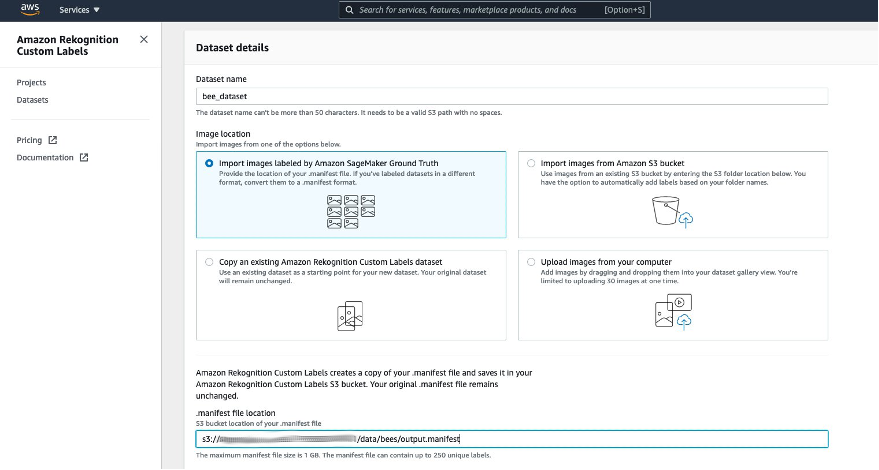
We created a manifest using the first notebook (1_prepare_data) that contains the Amazon S3 URIs of our image annotations. We follow these steps to import our manifest into Amazon Rekognition Custom Labels:
On the Amazon Rekognition Custom Labels console, choose Create dataset.
Select Import images labeled by Amazon SageMaker Ground Truth.
Name your dataset (for example, bee_dataset).
Enter the Amazon S3 URI of the manifest file that we created.
Copy the bucket policy that appears on the console.
Open the Amazon S3 console in a new tab and access the bucket where the images are stored.
On the Permissions tab, enter the bucket policy to allow access of the dataset by Amazon Rekognition Custom Labels.
Go back to the dataset creation console and choose Submit.
{kind=link}
Train your model
After the dataset is imported into Amazon Rekognition Custom Labels, we can train a model immediately.
Choose Train Model from the dataset page.
For Choose project, choose your bee-detection project.
For Choose training dataset, choose your bee_dataset dataset.
As part of model training, Amazon Rekognition Custom Labels requires a labeled test dataset to validate the model training. Amazon Rekognition Custom Labels uses the test dataset to verify how well your trained model predicts the correct labels and to generate evaluation metrics. Images in the test dataset are not used to train your model and should represent the same types of images you use your model to analyze.
For Create test set, select how you want to provide your test dataset.
Amazon Rekognition Custom Labels provides three options:
Choose an existing test dataset
Create a new test dataset
Split training dataset
For this post, we choose to split our training dataset, which sets aside 20% of our dataset for testing the model.
Select Split training dataset.
Choose Train.
{kind=link}
Our model took approximately 1.5 hours to train. The model achieved an average precision of 99% with a recall of 90% on the test data. The training time required for your model depends on many factors, including the number of images provided in the dataset and the complexity of the model. When training is complete, Amazon Rekognition Custom Labels outputs key quality metrics including F1 score, precision, recall, and the assumed threshold for each label. For more information about metrics, see Metrics for evaluating your model.
Serverless inference architecture
After our model is trained, Amazon Rekognition Custom Labels provides the API calls for starting, using, and stopping your model. In the environment setup section, we set up a serverless architecture to process test images that are uploaded to our S3 bucket via Amazon S3 events. It uses an AWS Lambda function to call the inference API, and manages these API calls using Amazon SQS.
We’re ready now to start applying our trained model to new images. We first need to start the project model version via the Amazon Rekognition Custom Labels console.
{kind=link}
We take note of our model’s ARN and update the Lambda function bee-detection-inference with it. This indicates which endpoint we must invoke to retrieve the object detection results. We can also change the assumed threshold to accept or reject results with a low confidence score.
Now it’s time to start uploading our test images to our S3 bucket prefix (s3://your-bucket/test_images). We can either use the Amazon S3 console or the AWS Command Line Interface (AWS CLI). We choose some test images present in our bee detection dataset and upload them using the console. As the images are uploaded, they’re queued in Amazon SQS and then processed by our Lambda function, leaving the result with the same file name, plus the .json suffix.
{kind=link}
We visualize the results of the JSON response from our Amazon Rekognition Custom Labels model using the second notebook (2_visualize_images). The following is an example of a response output:
This bee is detected with a confidence of 99.97%
{kind=link}
In the following image on the left, we find six bees over 99.4% confidence, which is our optimal threshold. The image on the right shows the same result with a threshold of 90% (15 bees).
{kind=link}
{kind=link}
Clean up
When you’re done, remember to follow these steps to avoid incurring in unnecessary charges:
Stop the model version on the Amazon Rekognition Custom Labels console.
Empty the S3 bucket that was created where images were uploaded.
Delete the CloudFormation stack to remove all provisioned resources.
Comparison with a custom DIY model
The performance of our Amazon Rekognition Custom Labels model is quantitatively better than our DIY model, achieving almost perfect precision (99%). It is noticeable how it’s also able to prevent false negatives, yielding a very robust recall of 90%, smashing the 56% recall of our DIY model. This is partly due to the optimized tuning that Amazon Rekognition Custom Labels applies to the model, and the assumed thresholds that it yields after training to achieve the best performance at test time.
For the first example, our single bee is detected at a much lower confidence score (64%), and with a rather large bounding box that doesn’t reflect accurately the size of the bee.
{kind=link}
For the more challenging picture, we must lower our threshold to 81% to find the very first detection (left), and lower it even more to 50% to find 7 bees (right).
{kind=link}
{kind=link}
Playing with this threshold can be risky. Setting a very low threshold can detect more bees (better recall), but at the same time find false detections, lowering our model precision. However, Amazon Rekognition Custom Labels can detect bees with a much higher confidence, which allows us to set a higher threshold for a much better overall performance.
Conclusion
In this post, we showed you how to create a computer vision object detection model with Amazon Rekognition Custom Labels using annotated data, and compared the results with a custom DIY model. Amazon Rekognition Custom Labels brings a great advantage over using your own models. Amazon Rekognition Custom Labels enables you to build and optimize your own specialized computer vision models to detect unique objects without the need of advanced programming knowledge.
With more experiments with other model architectures and hyperparameters, an ML scientist can improve the DIY model we tested in this post. The Amazon Rekognition Custom Labels value proposition is that it does these experiments on your behalf, thereby reducing the time to get a usable model and its development costs. Finally, we also showed how to set up a minimal serverless architecture to process new images using our trained model.
For more information about using custom labels, see What Is Amazon Rekognition Custom Labels?
About the Author
Raúl Díaz García is a Sr Data Scientist in the EMEA SDT IoT Team. Raúl works with customers across the EMEA region, where he helps them enable solutions related to Computer Vision and Machine Learning in the IoT space.
{kind=link}
Read MoreAWS Machine Learning Blog