

{kind=link}
The fields of natural language processing (NLP), natural language understanding (NLU), and related branches of machine learning (ML) for text analysis have rapidly evolved to address use cases involving text classification, summarization, translation, and more. State-of-the art, general-purpose architectures such as transformers are making this evolution possible. Looking at text classification in particular, a supervised learning technique that allows you to associate open-ended texts to predefined categories, we can see it’s being used for different use cases, such as identifying topics in documents, sentiment in customer reviews, detecting spam email, organizing medical records or files, categorizing news articles, and many other applications. Organizations of all sizes are applying these techniques, for example, to get insights from their data, or add intelligence to their business processes.
Hugging Face is a popular open-source library for NLP, with over 7,000 pretrained models in more than 164 languages with support for different frameworks. AWS and Hugging Face have a partnership that allows a seamless integration through Amazon SageMaker with a set of AWS Deep Learning Containers (DLCs) for training and inference in PyTorch or TensorFlow, and Hugging Face estimators and predictors for the SageMaker Python SDK. These capabilities in SageMaker help developers and data scientists get started with NLP on AWS more easily. Processing texts with transformers in deep learning frameworks such as PyTorch is typically a complex and time-consuming task for data scientists, often leading to frustration and lack of efficiency when developing NLP projects. Therefore, the rise of AI communities like Hugging Face, combined with the power of ML services in the cloud like SageMaker, accelerate and simplify the development of these text processing tasks.
In this post, we show you how to bring your own data for a text classification task by fine-tuning and deploying state-of-the-art models with SageMaker, the Hugging Face containers, and the SageMaker Python SDK.
Overview of the solution
In this example, we rely on the library of pre-trained models available in Hugging Face. We demonstrate how you can bring your own custom data to fine-tune the models, and use the processing scripts available in the Hugging Face Hub to speed up the process of tasks such as tokenization and data loading. Finally, we deploy the model to a SageMaker endpoint and perform real-time inferences with sample phrases on our text classification use case.
The Hugging Face community can help you get started easily with SageMaker by providing code snippets for use with any transformer and use case. To get started, choose Train or Deploy for any of the models in the Hugging Face portal, and choose Amazon SageMaker from the options.
{kind=link}
This will show you code examples for the most common tasks, that you can use in your own notebooks.
{kind=link}
For this example, we built a Jupyter notebook available in the GitHub repository that you can run from your environment of choice. You can use Amazon SageMaker Studio or your own Jupyter Server elsewhere, as long as you can communicate with the AWS Cloud through the SageMaker Python SDK and Boto3. In this notebook, we complete the following tasks:
Download the training data – We use the AG News dataset cited in the paper Character-level Convolutional Networks for Text Classification by Xiang Zhang and Yann LeCun. This dataset is available on the AWS Open Data Registry.
Create a Hugging Face estimator – We use the SageMaker Python SDK to directly point our estimator to the Hugging Face’s GitHub repository, and use Hugging Face scripts for preprocessing tasks such as data loading and tokenization. We also use DLCs for training with Hugging Face.
Train our news classification model – To run the actual training, we pass the training and testing data locations in Amazon Simple Storage Service (Amazon S3) as channels for our estimator.
Deploy our news classification model – Finally, we run inferences in real time with a SageMaker endpoint.
The following diagram shows our solution architecture.
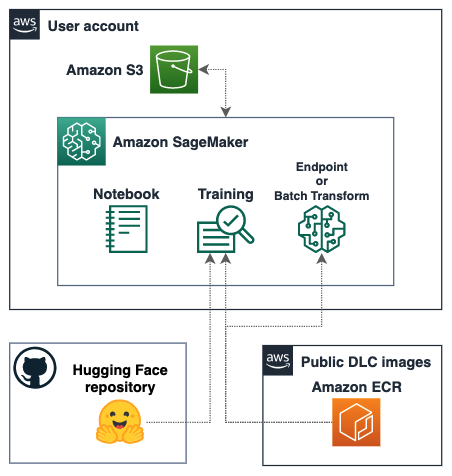{kind=link}
You can also copy and paste the code shown in this post directly to your own notebook if preferred.
Prerequisites
To follow along with this post, you should have the following prerequisites:
An AWS account.
A Studio domain, or any Jupyter Server environment with AWS SDK authentication. For instructions on how to onboard with Studio, see Onboard to Amazon SageMaker Studio Using Quick Start.
A copy of the sample notebook provided with this post, by either cloning the GitHub repository or downloading the notebook file from it.
Prepare the environment and data
Follow the instructions in the sample notebook we provided. You start by making sure your notebook environment has an updated version of the SageMaker SDK. Then, import the required libraries, and set up your session, role, Region, and S3 bucket and prefix to use for storing the data and resulting models.
With regards to the data, the AG News dataset contains more than 490,000 news articles obtained from more than 2,000 news sources, and is classified according to the four largest classes from AG’s corpus of news articles: World, Sports, Business, and Sci/Tech. These are provided in two files: one for training with 30,000 samples, and one for testing with 1,900 samples.
Follow the instructions in the notebook to download the dataset, extract the compressed CSV files, and add a header to them. We upload the resulting files to Amazon S3.
You can also check the map of classes included in the dataset, just to use as a reference when we run inferences with our models (see the following screenshot). The index of each label in this map corresponds to the IDs returned by our model’s predictions later on.
{kind=link}
Fine-tune the model
Now that we have the input data in Amazon S3, we can fine-tune our news classifier. For this task, we use the pre-trained model bert-large-uncased available in the Hugging Face Hub. BERT-large (uncased) is a highly popular model pre-trained on a large corpus of English data in a self-supervised fashion. For this task, we can simply define the basic hyperparameters, and point our Git configuration towards the Hugging Face open-source repository for transformers. You can use any other model of your choice available in the Hub by changing the model_name_or_path parameter in the configuration:
One advantage of relying on the SageMaker and Hugging Face integration for this task is the ability to use the processing scripts already available in the Hub, so we don’t have to write any processing or training script on our own. These are made available to SageMaker through the git_config parameter:
Finally, we define our SageMaker estimator, relying on the SDK and the pre-built DLCs, and proceed to fit (train) the model. We set the flag wait as false so we don’t have to wait for the training to finish holding our notebooks’ kernel.
For a full list of AWS DLCs currently supported with SageMaker, visit the available images information in GitHub; you can check the Hugging Face Training and Inference containers sections in particular.
We’re pointing directly towards the entry point script run_glue.py located in the Hugging Face repository in GitHub, so we don’t need to copy this script manually to our environment. You can rely on this script for bringing any custom data in CSV or JSON format for your text classification tasks, as long as it includes the classification label and text fields. You have other equivalent scripts available in the transformers repository for other text processing tasks, such as summarization, text generation, and more. In our news classification example, this script together with the SageMaker and Hugging Face integration automatically does the following:
Preprocesses our input data, for example, encoding text labels
Performs the relevant tokenization in the text automatically
Prepares the data for training our BERT model for text classification
This represents a huge improvement in development time and operational efficiency compared to developing and performing these tasks manually in an equivalent PyTorch implementation.
In summary, note we are providing the configuration and data channels as inputs for our estimator, and it will provide us the trained model with its logs and metrics as outputs.
{kind=link}
The duration of the training job depends on the type of instance you choose in your estimator configuration. For example, using an ml.g4dn.12xlarge instance should take around 1.5 hours to complete the full training, whereas using a ml.p3.16xlarge reduces this time to 1 hour. We can always check the status, logs, and metrics for our SageMaker training jobs on the SageMaker console.
{kind=link}
As a comparison example, in the notebook we have included a section for testing another model from the hub called amazon/bort. BORT is a model developed by the Amazon Alexa team as a highly compressed version of BERT-large, with an optimal sub-architecture found using neural architecture search. This model can be useful when looking for faster training and inference performance with a trade-off of performance loss.
When we compare both models in our news classification example, we can see the training time for BORT just takes 18 minutes, which is 80% faster than our BERT example. When we check the resulting model artifacts stored in Amazon S3, we also see the size of the resulting model is 82% lighter for BORT than for BERT. However, this optimization comes with a decrease of around 3% in accuracy after a single training epoch (from 0.95 to 0.92 evaluation accuracy). You can further improve this effect by increasing the epochs and adjusting hyperparameters, but this is outside the scope of this post.
In general, you should consider this kind of performance vs. efficiency trade-off when choosing a given model from the transformers’ hubs, according to your specific use case needs.
Deploy the model
After we finish fine-tuning our model with our news data, we can test it by deploying a SageMaker endpoint for each.
Again, we rely on the pre-built AWS DLC for Hugging Face, but this time the HuggingFaceModel points towards the inference container images:
We can now run inferences towards the endpoint to test our model. Let’s see how well our model classifies news headlines that it has never seen before:
{kind=link}
{kind=link}
You can try writing your own news titles and prove the model performs well in classifying headlines that aren’t in our dataset.
We can also check the inference time for the model, for example, by running 1,000 inference requests programmatically and calculating the average response time. On average, we see our BERT model responds in around 30 milliseconds, and coming back to our BORT comparison example, it runs the inferences in around 13 milliseconds, which is 57% faster than BERT.
Costs
With this solution, SageMaker charges your account for the following:
Development – The time we had the Studio kernel running for the notebook
Training – The time SageMaker was effectively training the models
Inference – The time we had the SageMaker endpoints active for inference
This is estimated around $12 USD in total (as of this writing), using ml.t3.medium instances for the notebook kernel, ml.g4dn.12xlarge for training, and ml.g4dn.xlarge for inference.
For more details on the public pricing of SageMaker, you can check the pricing page, or create your own cost estimation for SageMaker using the AWS Pricing Calculator. Also, if you will consistently use SageMaker in the future, consider using the SageMaker Saving Plans to reduce your costs by up to 64%.
Clean up
To avoid incurring future charges after completing the exercise, delete the endpoints you created.
{kind=link}
Additionally, stop the Studio kernel running for your notebook.
{kind=link}
For more information on how to clean up SageMaker resources, see Clean Up.
Conclusion
With this example, we saw how to bring our own dataset for fine-tuning models available in the Hugging Face Hub, and how to integrate this with the SageMaker SDK and DLCs for Hugging Face training and inference. The main advantage of this integration is that it helps data scientists in these ML projects by allowing you to do the following:
Accelerate NLP experiments by making it easy to use well-known pre-trained transformer models, and compare multiple models, hyperparameters, and configurations
Reuse existing preprocessing scripts for NLP, reducing human errors and administration needs
Remove the heavy lifting from the ML process to make it easier to develop high-quality models
Have direct access to one of the most popular open-source NLP communities in the industry
For more information on SageMaker and Hugging Face, see Use Hugging Face with Amazon SageMaker.
About the Author
Antonio Rodriguez is an Artificial Intelligence and Machine Learning Specialist Solutions Architect in Amazon Web Services, based out of Spain. He helps companies of all sizes solve their challenges through innovation, and creates new business opportunities with the AWS Cloud and AI/ML services. Apart from work, he loves to spend time with his family and play sports with his friends.
Read MoreAWS Machine Learning Blog