

{kind=link}
With the advent of artificial intelligence (AI) and machine learning (ML), customers and the general public have become increasingly aware of their privacy, as well as the value that it holds in today’s data-driven world. Enterprises are actively seeking out and marketing privacy-first solutions, especially in the Computer Vision (CV) domain. They need to reassure their customers that personal information such as faces are anonymized and generally kept safe.
Face blurring is one of the best-known practices when anonymizing both images and videos. It usually involves first detecting the face in an image/video, then applying a blob of pixels or other distortion effects on it. This workload can be considered a CV task. First, we analyze the pixels of the image/video until a face is recognized, then we extract the area where the face is in every frame, and finally we apply a mask on the previously found pixels. The first part of this can be achieved with ML and Deep Learning tools, such as Amazon Rekognition, while the second part is standard pixel manipulation.
In this post, we demonstrate how AWS Step Functions can be used to orchestrate AWS Lambda functions that call Amazon Rekognition Video to detect faces in videos, and use an open source CV and ML software library called OpenCV to blur them.
Solution overview
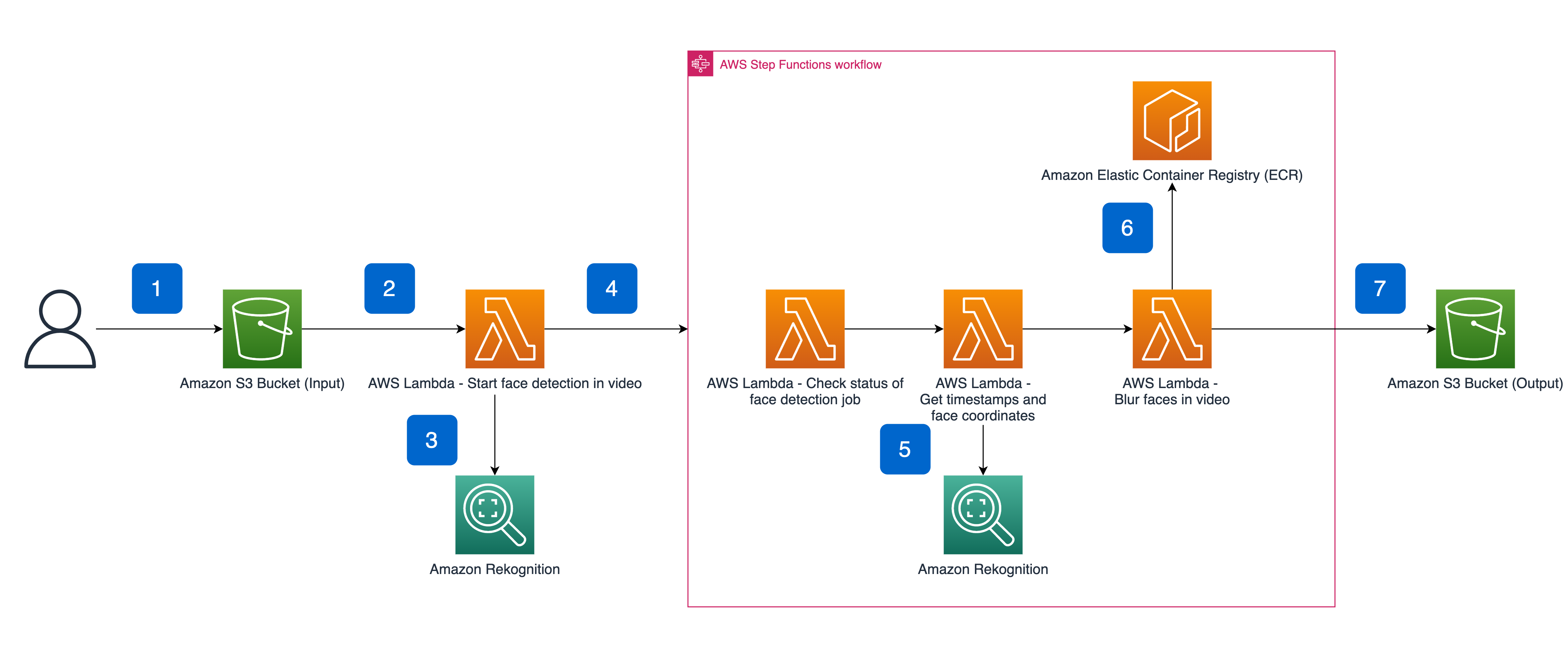
In our solution, AWS Step Functions, a low-code visual workflow service used to orchestrate AWS services, automate business processes, and build serverless applications, is used to orchestrate the calls and manage the flow of data between AWS Lambda functions. When an object is created in an Amazon Simple Storage Service (S3) bucket, for example by a video file upload, an ObjectCreated event is detected and a first Lambda function is triggered. This Lambda function makes an asynchronous call to the Amazon Rekognition Video face detection API and starts the execution of the AWS Step Functions workflow.
Inside the workflow, we use a Lambda function and a Wait State until the Amazon Rekognition Video asynchronous analysis started earlier finishes execution. Afterward, another Lambda function retrieves the result of the completed process from Amazon Rekognition and passes it to another Lambda function that uses OpenCV to blur the detected faces. To easily use OpenCV with our Lambda function, we built a Docker image hosted on Amazon Elastic Container Registry (ECR), and then deployed on AWS Lambda thanks to Container Image Support.
The architecture is entirely serverless, so we don’t need to provision, scale, or maintain our infrastructure. We also use Amazon Rekognition, a highly scalable and managed AWS AI service that requires no deep learning expertise.
Moreover, we have built our application with the AWS Cloud Development Kit (AWS CDK), an open-source software development framework. This lets us write Infrastructure as Code (IaC) using Python, thereby making the application easy to deploy, modify, and maintain.
{kind=link}
Let’s look closer at the suggested architecture:
The event flow starts at the moment of the video ingestion into Amazon S3. Amazon Rekognition Video supports MPEG-4 and MOV file formats, encoded using the H.264 codec.
After the video file has been stored into Amazon S3, it automatically kicks-off an event triggering a Lambda function.
The Lambda function uses the video’s attributes (name and location on Amazon S3) to start the face detection job on Amazon Rekognition through an API call.
The same Lambda function then starts the Step Functions state machine, forwarding the video’s attributes and the Amazon Rekognition job ID.
The Step Functions workflow starts with a Lambda function waiting for the Amazon Rekognition job to be finished. Once it’s done, another Lambda function gets the results from Amazon Rekognition.
Finally, a Lambda function with Container Image Support fetches its Docker image, which supports OpenCV from Amazon ECR, blurs the faces detected by Amazon Rekognition, and temporarily stores the output video locally.
Then, the blurred video is put into the output S3 bucket and removed from local files.
{kind=link}
Providing a serverless function access to OpenCV is easier than ever with Container Image Support. Instead of uploading a code package to AWS Lambda, the function’s code resides in a Docker image that is hosted in Amazon Elastic Container Registry.
If you want to build your own application using Amazon Rekognition face detection for videos and OpenCV to process videos with Python, consider the following:
Amazon Rekognition API responses for videos contain faces-detected timestamps in milliseconds
OpenCV works on frames and uses the video’s frame rate to combine frames into a video
Therefore, you must convert Amazon Rekognition information to make it usable with OpenCV. You may find our implementation in the apply_faces_to_video function, in /rekopoc-apply-faces-to-video-docker/video_processor.py.
Deploy the application
If you want to deploy the sample application to your own account, go to this GitHub repository. Clone it to your local environment (you can also use tools such as AWS Cloud9) and deploy it via cdk deploy. Find more details in the later section “Deploy the AWS CDK application”. First, let’s look at the repository project structure.
Project structure
This project contains source code and supporting files for a serverless application that you can deploy with the AWS CDK. It includes the following files and folders.
rekognition_video_face_blurring_cdk/ – CDK Python code for deploying the application.
rekopoc-apply-faces-to-video-docker/ – Code for Lambda function: uses OpenCV to blur faces per frame in video, uploads final result to output S3 bucket.
rekopoc-check-status/ – Code for Lambda function: Gets face detection results for the Amazon Rekognition Video analysis.
rekopoc-get-timestamps-faces/ – Code for Lambda function: Gets bounding boxes of detected faces and associated timestamps.
rekopoc-start-face-detect/ – Code for Lambda function: is triggered by an S3 event when a new .mp4 or .mov video file is uploaded, starts asynchronous detection of faces in a stored video, and starts the execution of AWS Step Functions’ State Machine.
requirements.txt – Required packages for deploying the AWS CDK application.
The application uses several AWS resources, including AWS Step Functions, Lambda functions, and S3 buckets. These resources are defined in the rekognition_video_face_blurring_cdk/rekognition_video_face_blurring_cdk_stack.py of this project. Update the Python code to add AWS resources through the same deployment process that updates your application code. Depending on the size of the video that you want to anonymize, you might need to update the configuration of the Lambda functions and adjust memory and timeout. You can provision a maximum of 10,240 MB (10 GB) of memory, and configure your AWS Lambda functions to run up to 15 minutes per execution.
Deploy the AWS CDK application
The AWS Cloud Development Kit (AWS CDK) is an open-source software development framework to define your cloud application resources using familiar programming languages. This project uses the AWS CDK in Python.
AWS CDK – Getting started with the AWS CDK
AWS CDK on GitHub – AWS CDK on GitHub – Contribute!
AWS CDK API Reference (for Python) – AWS CDK Python API Reference
Docker – Install Docker community edition
To build and deploy your application for the first time, you must:
Step 1: Ensure you have Docker running.
You will need Docker running to build the image before pushing it to Amazon ECR.
Step 2: Configure your AWS credentials.
The easiest way to satisfy this requirement is to issue the following command in your shell:
For additional guidance on how to set up your AWS CLI installation, follow the Quick configuration with aws configure from the AWS CLI user guide.
Step 3: Install the AWS CDK and the requirements.
Simply run the following in your shell:
The first command will install the AWS CDK Toolkit globally using Node Package Manager.
The second command will install all of the Python packages needed by the AWS CDK using pip package manager. This command should be issued from the root folder of the cloned GitHub repository.
Step 4: Bootstrap your AWS environment for the CDK and deploy the application.
The first command will provision initial resources that the AWS CDK needs to perform the deployment. These resources include an Amazon S3 bucket for storing files and IAM roles that grant permissions needed to perform deployments.
Finally, cdk deploy will deploy the stack.
Step 5: Test the application.
Upload a video to the input S3 bucket through the AWS Management Console, the AWS CLI, or the SDK, and find the result in the output bucket.
Cleanup
To delete the sample application that you created, use the AWS CDK:
Conclusion
In this post, we showed you how to deploy a solution to automatically blur videos without provisioning any resources to your AWS account. We used Amazon Rekognition Video face detection feature, Container Image Support for AWS Lambda functions to easily work with OpenCV, and we orchestrated the whole workflow with AWS Step Functions. Finally, we made our solution comprehensive and reusable with the AWS CDK to make it easier to deploy and adapt.
Next Steps
If you have feedback about this post, submit it in the Comments section below. For more information, visit the following links about the tools and services that we used and follow the code in GitHub. We look forward to your feedback and contributions!
Amazon Rekognition – Developer Guide
Amazon Rekognition – API Reference
Amazon Rekognition – AWS SDK for Python
Docker – Install Docker community edition
AWS CDK – Getting started with the AWS CDK
AWS CDK on GitHub
AWS CDK API Reference (for Python) – AWS CDK Python API Reference
About the Authors
Anastasia Pachni Tsitiridou is a Solutions Architect at AWS. She is based in Amsterdam and supports ISVs across the Benelux in their cloud journey. She studied Electrical and Computer Engineering before being introduced to Computer Vision. What she enjoys most nowadays is working at the intersection of CV and ML.
{kind=link}
Olivier Sutter is a Solutions Architect in France. He is based in Paris and always sets his customers’ best interests as his top priority. With a strong academic background in applied mathematics, he started developing his AI/ML passion at university, and now thrives applying this knowledge on real-world use-cases with his customers.
{kind=link}
Davide Gallitelli is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customer throughout Benelux. He has been a developer since very young, starting to code at the age of 7. He has started learning AI/ML since the latest years of university, and has fallen in love with it since then.
{kind=link}
Read MoreAWS Machine Learning Blog