

{kind=link}
Amazon Neptune, a fully managed graph database, is purpose built to work with highly connected data such as relationships between customers and products, or between pieces of equipment within a complex industrial plant. Neptune is designed to support highly concurrent online transaction processing (OLTP) over graph data models.
Neptune supports both property graphs, which you can query via Apache TinkerPop Gremlin or openCypher, and graphs containing RDF data that can be queried via SPARQL. Neptune is secure by default, only being natively accessible from within a customer’s Amazon Virtual Private Cloud (Amazon VPC), or peered VPC or private network.
In this post, we focus on how you can use a container running the Apache TinkerPop Gremlin Server to run functional tests against queries that have been written to run against a property graph in Neptune. This is important as it enables Gremlin queries to be functionally tested within a CI/CD pipeline, without the need to connect to a Neptune database inside the VPC. In our code example accompanying this post, we use Node.js and the associated Gremlin library that is available for Node, although the concept can be extended to other programming languages that may be used to access Neptune, such as Python, or Java.
Initial considerations
Introducing Neptune as a data store into an application offers significant advantages in being able to naturally represent large-scale, highly connected data and query it at millisecond latency. When adopting Neptune, teams should consider the following:
The database is natively secured within a customer’s VPC and, by design, access from hosts outside the customer’s VPC, peered VPCs, or private networks is protected.
As the graph database market grows rapidly, more developers are gaining experience with graph query languages such as Gremlin. Declarative graph query languages such as openCypher and SPARQL are similar to SQL, which many developers are already familiar with from working with relational databases.
Being able to automate the testing of database queries enables you to shift testing left, helping to catch bugs as early as possible in the development life-cycle.
Testing and debugging graph queries
The code, test, and debug cycle that is at the very heart of software development can be challenging when the only way to test and debug graph queries is to run them against a compatible database. Neptune is secured within the VPC, whereas many developers use local development environments. Neptune offers Jupyter notebooks as a valuable resource to developers wanting to learn and experiment with queries against a Neptune database as part of the Neptune graph notebook project. You can provision a notebook when you create a Neptune database. It provides tutorials, code samples, and a visualization component in an interactive coding environment. You can either run notebooks in a fully managed environment within Amazon SageMaker within the VPC, or run them locally, connected to a Neptune instance.
The Neptune workbench provides several magic commands in the notebook that save time and effort for developers wanting to test their queries against a Neptune graph. The following screenshot shows two cell magics: %%gremlin issues Gremlin queries to the graph, and %%opencypher issues openCypher queries to the graph. This illustrates how you can use different query languages against the same property graph in Neptune.
{kind=link}
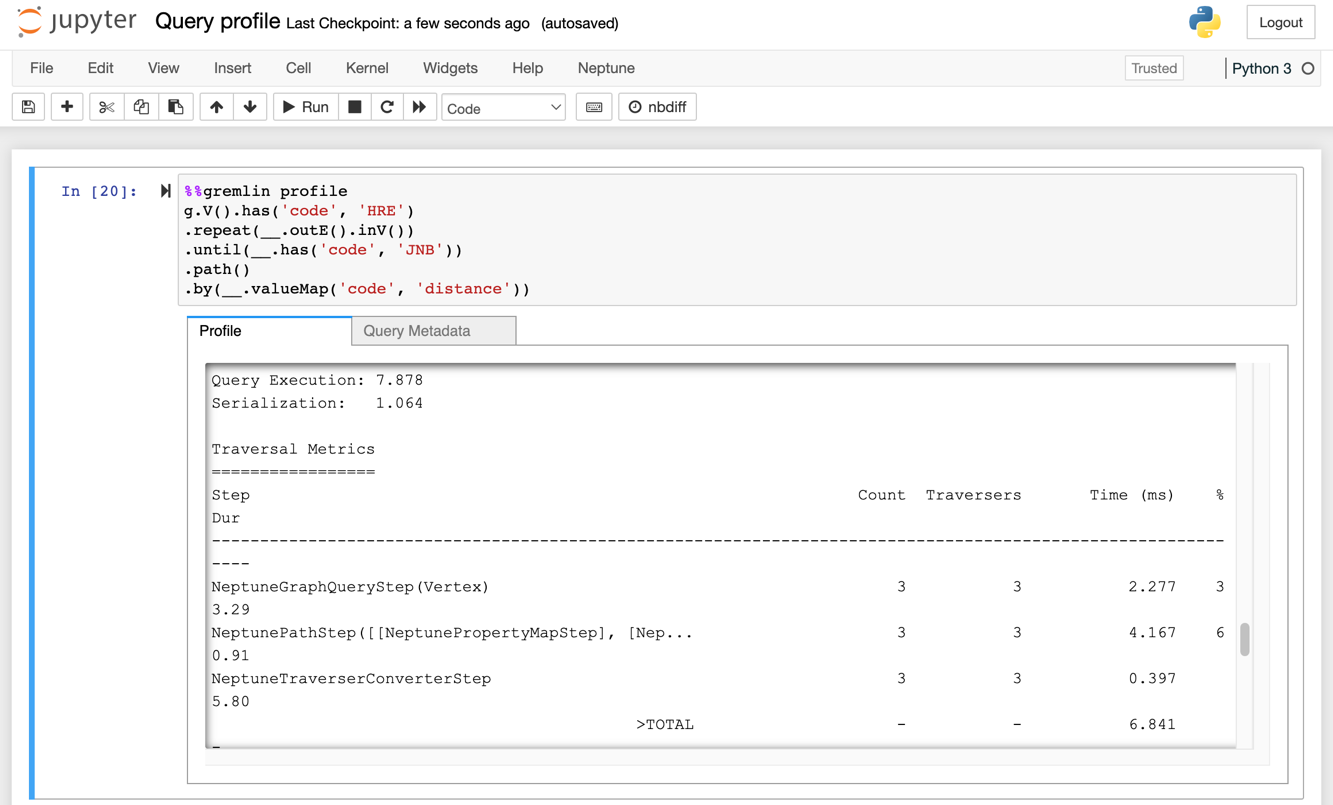
Another useful feature offered by the Neptune workbench to developers needing to analyze the performance of their Gremlin queries is the ability to profile Gremlin queries using the %%gremlin profile cell magic, as shown in the following screenshot. The query profiler provides data about the traversal and its runtime metrics that support developers in tuning their queries.
{kind=link}
There are several ways to establish a connection from a local developer machine to a Neptune instance inside the VPC, for example using an AWS Client VPN or via a bastion host and AWS Systems Manager Session Manager port forwarding. Both these mechanisms enable you to run a local graph notebook and use the features offered by it, as well as run graph queries on your local machine, against a Neptune instance, and use your favorite debugger to test your queries.
Although the Neptune graph notebook is an invaluable tool to developers for initial testing and experimentation, you can’t integrate it into an automated test pipeline. Likewise, with potentially multiple developers needing to run fast and frequent unit tests for their graph queries, the use of a Neptune database for testing queries isn’t ideal for the following reasons:
It’s difficult to provide the isolation required to run deterministic tests—the state of the database persists between test runs and the database may be shared between more than one developer
Developers must maintain tunnel or VPN connections into the VPC
Testing can’t be performed without connectivity to the internet
Speed is essential when running unit tests. If the test suites can’t be run quickly and often, the fast feedback essential for effective development is lost.
For these reasons, we advocate using a local database running within a container to run functional tests against. Apache TinkerPop provides the Gremlin Server, which is ideal for this purpose because it provides a way to remotely run Gremlin queries against compatible graph instances hosted within it. This way the Gremlin Server acts as a test double for the system under test as illustrated in the following figure.
When following this approach, you should be aware of the few important differences that exist between the Neptune implementation of Gremlin and Apache TinkerPop as implemented in Gremlin Server. For more information, refer to Gremlin Standards compliance in Amazon Neptune. Furthermore, this approach isn’t suitable for any type of performance testing of queries, because the performance characteristics of Neptune and Gremlin Server will differ.
{kind=link}
We can use Docker to create a container that starts an instance of Gremlin Server, and exposes it over a local port for tests to run against.
In the code sample accompanying this post, we create a class that is responsible for bootstrapping test data within the database prior to each test run, with the starting of the container, running the test, and stopping the container orchestrated by a simple Makefile.
The test data that is loaded to the graph consists of a property graph that represents the data under test. The following figure shows a small subset of the air routes graph referenced in the popular Practical Gremlin book, which is used in the accompanying sample code to run tests against. The test data contains sufficient detail to perform functional tests of graph queries.
{kind=link}
Figure 4: A minimal subset of the air routes graph used by unit tests showing airport codes and distances between them
The following code is the Dockerfile that uses version 3.5.2 of the TinkerPop Gremlin Server container image, which is the latest version of Gremlin compatible with Neptune at the time of writing, for our tests to run against:
To configure the Gremlin Server to test queries that are written for Neptune, there is some minor configuration that must be made to configure TinkerGraph to work with string IDs. The following code shows the relevant section from the configuration properties file located in the test/db/conf directory in the accompanying code sample in GitHub
The Gremlin Server instance running in Docker is configured via the following configuration file, gremlin-server.yml:
The updated configuration files for the Gremlin Server instance are mounted to the Docker container via a volume in a Docker compose file:
The accompanying example code demonstrates the implementation of this concept using Typescript as the language for running graph queries, although you can easily apply the concept to other languages such as Python or Java using the same Gremlin Server container. The sample code contains the following key classes:
The Dod (or data on demand) class builds the graph in the Gremlin Server that the tests run against. This graph represents the data under test. In the example code, this is the graph illustrated in the preceding diagram.
The GremlinClient class contains methods that run Gremlin queries against the graph.
There are a set of tests in the sample code that exercise the Gremlin queries against the same Gremlin Server hosted property graph running within a Docker container. Following this approach, you can add automated testing of Gremlin queries to a continuous integration (CI) pipeline and run them on every commit to the repository, providing fast feedback and assurance. The following screenshot illustrates debugging Gremlin queries within an IDE, which is another useful feature offered by running tests against a local database.
{kind=link}
Conclusion
With graph databases increasing in popularity, and the need to shift testing left as far as possible, it’s essential to have an approach to effectively test graph queries during local development and CI. The Neptune notebook project supports developers in initial testing and experimentation with supported query languages, as well as the ability to profile Gremlin queries. As graph database adoption increases, automated testing of queries needs to be moved into the CI pipeline.
In this post, we showed how an ephemeral database running inside a container can support this for property graphs that will be stored inside Neptune and queried via Gremlin. We demonstrated how to use this approach to test and debug Gremlin queries in an automated manner, without needing to open access to the VPC.
A complete example of the approach described that creates a Gremlin Server and test graph within a container and runs a test suite of Gremlin queries against the test graph is available in the GitHub repo.
About the Author
Greg Biegel is a Senior Cloud Architect with AWS Professional Services in Perth, Western Australia. He loves spending time working with customers in the Mining, Energy, and Industrial sector, helping them to achieve valuable business outcomes. He has a PhD from Trinity College Dublin and over 20 years of experience in software development.
{kind=link}
Read MoreAWS Database Blog