

{kind=link}
Last Updated on September 20, 2022
In languages the order of the words and their position in a sentence really matters. The meaning of the entire sentence can change if the words are re-ordered. When implementing NLP solutions, the recurrent neural networks have an inbuilt mechanism that deals with the order of sequences. The transformer model, however, does not use recurrence or convolution and treats each data point as independent of the other. Hence, positional information is added to the model explicitly to retain the information regarding the order of words in a sentence. Positional encoding is the scheme through which the knowledge of order of objects in a sequence is maintained.
For this tutorial, we’ll simplify the notations used in this awesome paper Attention is all You Need by Vaswani et al. After completing this tutorial, you will know:
What is positional encoding and why it’s important
Positional encoding in transformers
Code and visualize a positional encoding matrix in Python using NumPy
Let’s get started.
{kind=link}
A Gentle Introduction to Positional Encoding In Transformer Models
Photo by Muhammad Murtaza Ghani on Unsplash, some rights reserved
Tutorial Overview
This tutorial is divided into four parts; they are:
What is positional encoding
Mathematics behind positional encoding in transformers
Implementing the positional encoding matrix using NumPy
Understanding and visualizing the positional encoding matrix
What is Positional Encoding?
Positional encoding describes the location or position of an entity in a sequence so that each position is assigned a unique representation. There are many reasons why a single number such as the index value is not used to represent an item’s position in transformer models. For long sequences, the indices can grow large in magnitude. If you normalize the index value to lie between 0 and 1, it can create problems for variable length sequences as they would be normalized differently.
Transformers use a smart positional encoding scheme, where each position/index is mapped to a vector. Hence, the output of the positional encoding layer is a matrix, where each row of the matrix represents an encoded object of the sequence summed with its positional information. An example of the matrix that encodes only the positional information is shown in the figure below.
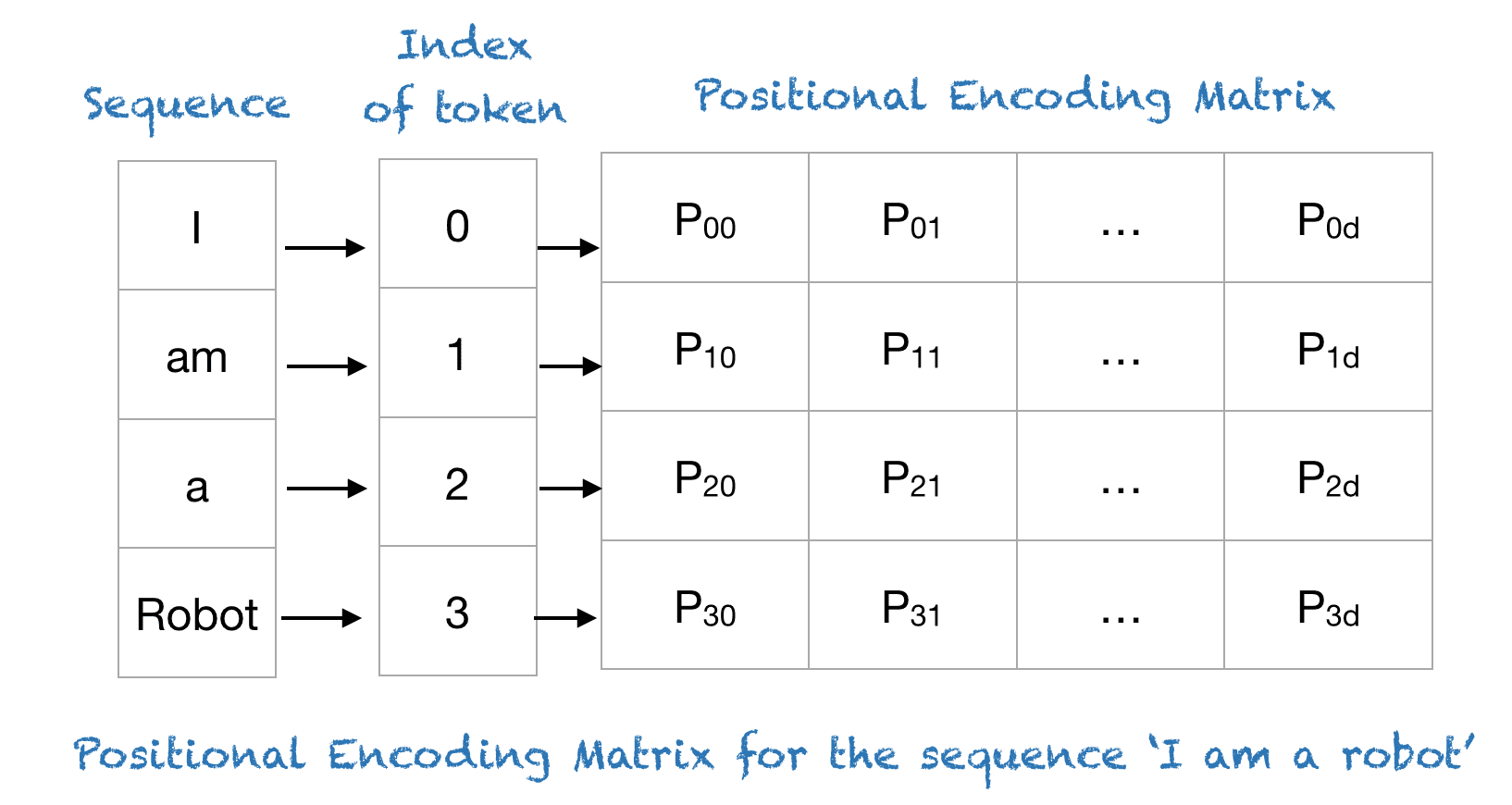{kind=link}
A Quick Run-Through Trigonometric Sine Function
This is a quick recap of sine functions and you can work equivalently with cosine functions. The function’s range is [-1,+1]. The frequency of this waveform is the number of cycles completed in one second. The wavelength is the distance over which the waveform repeats itself. The wavelength and frequency for different waveforms is shown below:
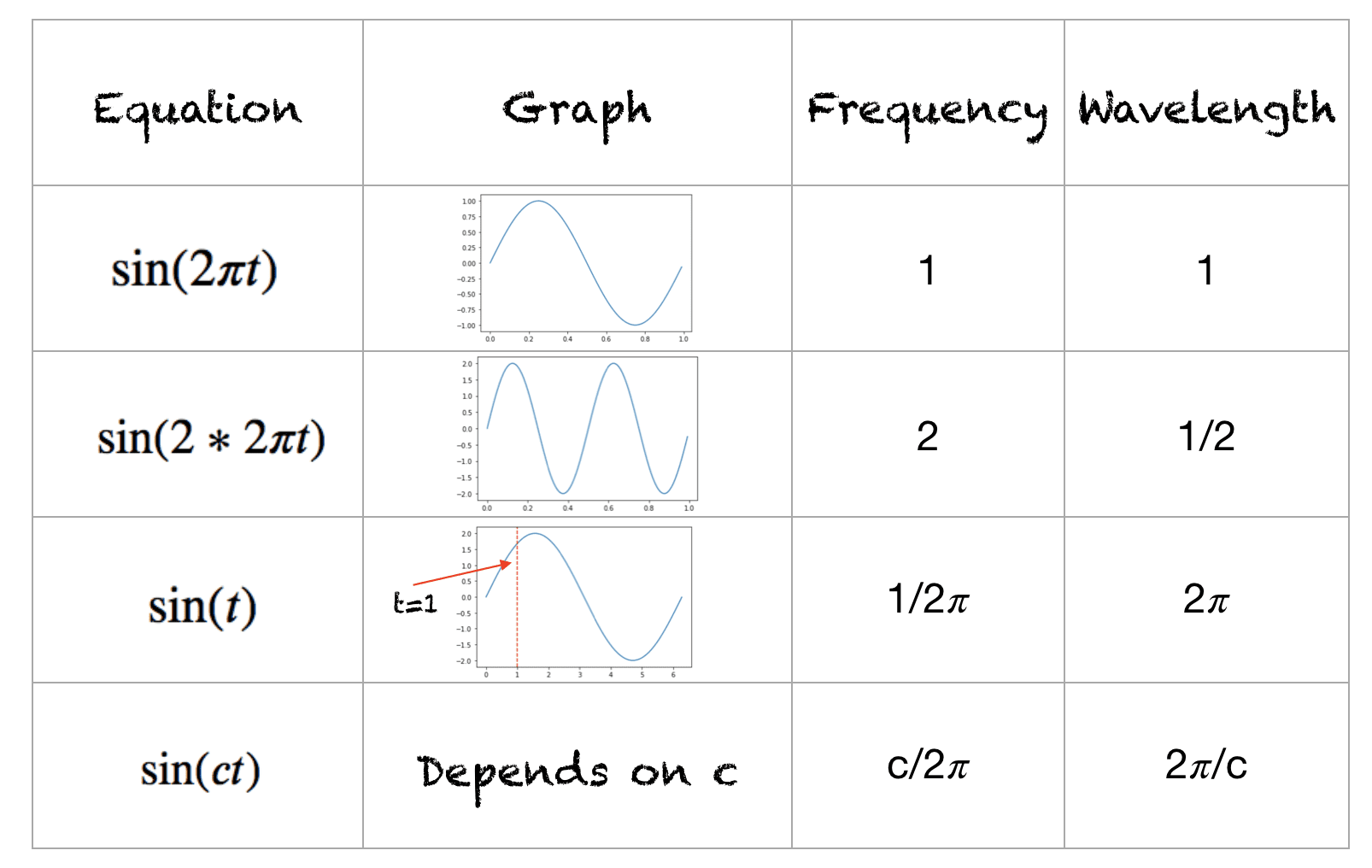{kind=link}
Positional Encoding Layer in Transformers
Let’s dive straight into this. Suppose we have an input sequence of length $L$ and we require the position of the $k^{th}$ object within this sequence. The positional encoding is given by sine and cosine functions of varying frequencies:
begin{eqnarray}
P(k, 2i) &=& sinBig(frac{k}{n^{2i/d}}Big)\
P(k, 2i+1) &=& cosBig(frac{k}{n^{2i/d}}Big)
end{eqnarray}
Here:
$k$: Position of an object in input sequence, $0 leq k < L/2$
$d$: Dimension of the output embedding space
$P(k, j)$: Position function for mapping a position $k$ in the input sequence to index $(k,j)$ of the positional matrix
$n$: User defined scalar. Set to 10,000 by the authors of Attention is all You Need.
$i$: Used for mapping to column indices $0 leq i < d/2$. A single value of $i$ maps to both sine and cosine functions
In the above expression we can see that even positions correspond to sine function and odd positions correspond to even positions.
Example
To understand the above expression, let’s take an example of the phrase ‘I am a robot’, with n=100 and d=4. The following table shows the positional encoding matrix for this phrase. In fact the positional encoding matrix would be the same for any 4 letter phrase with n=100 and d=4.
{kind=link}
Coding the Positional Encoding Matrix From Scratch
Here is a short Python code to implement positional encoding using NumPy. The code is simplified to make the understanding of positional encoding easier.
import numpy as np
import matplotlib.pyplot as plt
def getPositionEncoding(seq_len, d, n=10000):
P = np.zeros((seq_len, d))
for k in range(seq_len):
for i in np.arange(int(d/2)):
denominator = np.power(n, 2*i/d)
P[k, 2*i] = np.sin(k/denominator)
P[k, 2*i+1] = np.cos(k/denominator)
return P
P = getPositionEncoding(seq_len=4, d=4, n=100)
print(P)
[[ 0. 1. 0. 1. ]
[ 0.84147098 0.54030231 0.09983342 0.99500417]
[ 0.90929743 -0.41614684 0.19866933 0.98006658]
[ 0.14112001 -0.9899925 0.29552021 0.95533649]]
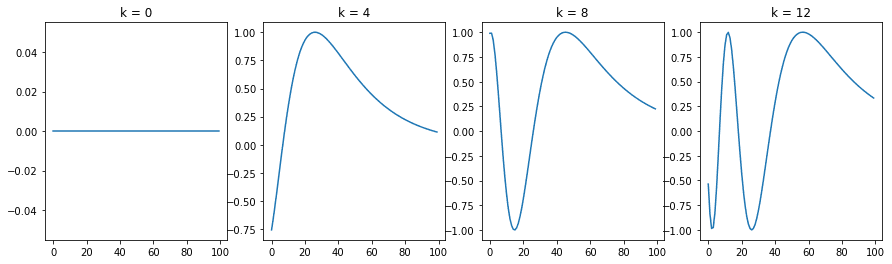
Understanding the Positional Encoding Matrix
x = np.arange(0, 100, 1)
denominator = np.power(n, 2*x/d)
y = np.sin(k/denominator)
plt.plot(x, y)
plt.title(‘k = ‘ + str(k))
fig = plt.figure(figsize=(15, 4))
for i in range(4):
plt.subplot(141 + i)
plotSinusoid(i*4)
The following figure is the output of the above code:
{kind=link}
We can see that each position $k$ corresponds to a different sinusoid, which encodes a single position into a vector. If we look closely at the positional encoding function, we can see that the wavelength for a fixed $i$ is given by:
$$
lambda_{i} = 2 pi n^{2i/d}
$$
Hence, the wavelengths of the sinusoids form a geometric progression and vary from $2pi$ to $2pi n$. The scheme for positional encoding has a number of advantages.
The sine and cosine functions have values in [-1, 1], which keeps the values of the positional encoding matrix in a normalized range.
As the sinusoid for each position is different, we have a unique way of encoding each position.
We have a way of measuring or quantifying the similarity between different positions, hence enabling us to encode relative positions of words.
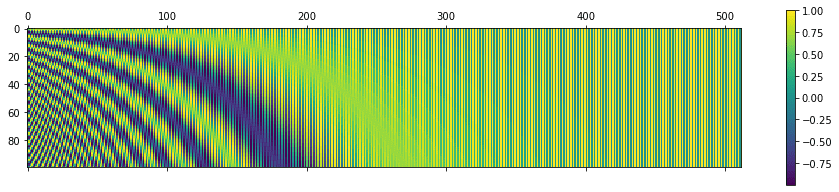
Visualizing the Positional Matrix
Let’s visualize the positional matrix on bigger values. We’ll use Python’s matshow() method from the matplotlib library. Setting n=10,000 as done in the original paper, we get the following:
P = getPositionEncoding(seq_len=100, d=512, n=10000)
cax = plt.matshow(P)
plt.gcf().colorbar(cax)
{kind=link}
What is the Final Output of the Positional Encoding Layer?
The positional encoding layer sums the positional vector with the word encoding and outputs this matrix for the next layers. The entire process is shown below.
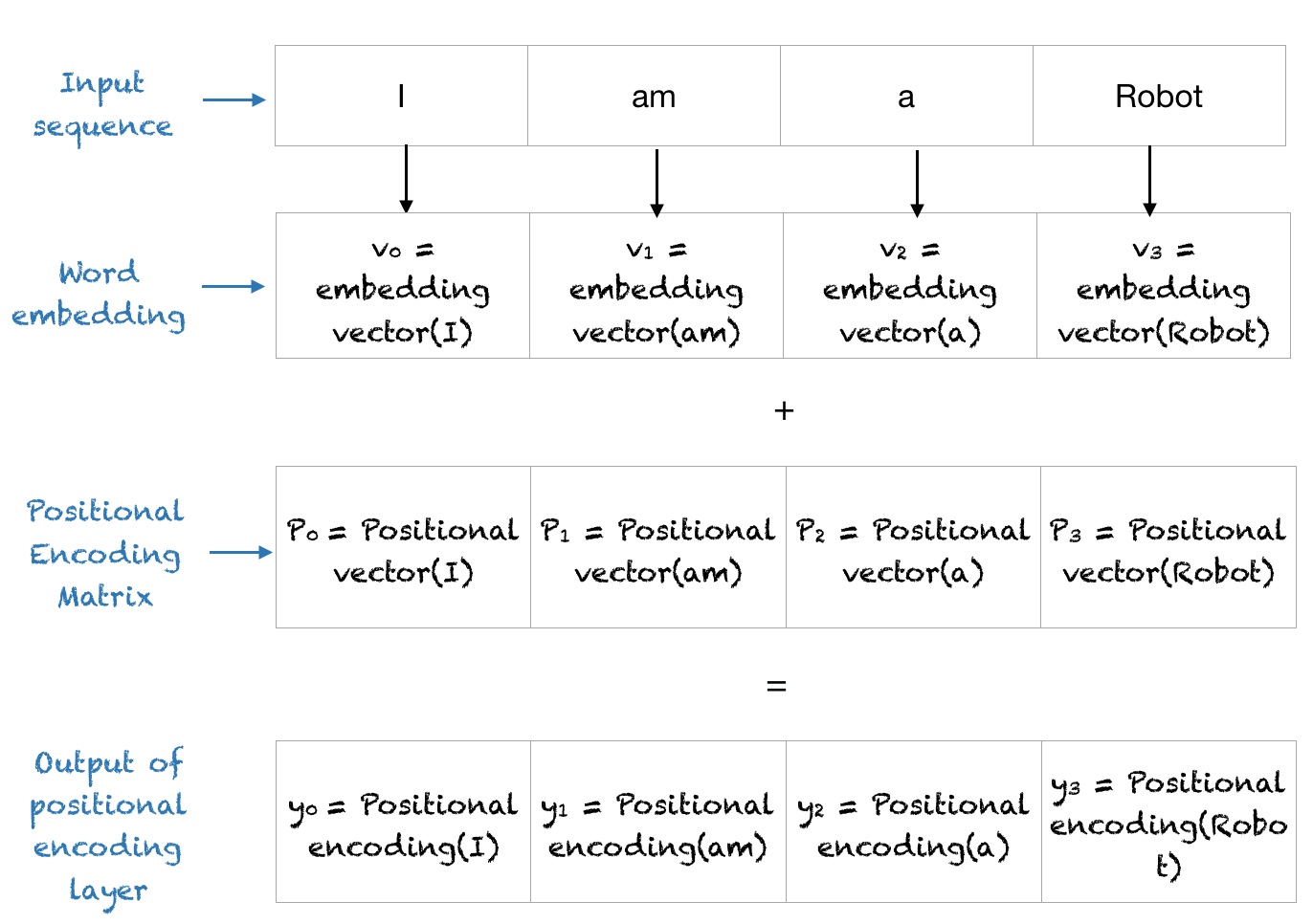{kind=link}
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
Transformers for natural language processing, by Denis Rothman.
Papers
Attention Is All You Need, 2017.
Articles
The Transformer Attention Mechanism
The Transformer Model
Transformer model for language understanding
Summary
In this tutorial, you discovered positional encoding in transformers.
Specifically, you learned:
What is positional encoding and why it is needed.
How to implement positional encoding in Python using NumPy
How to visualize the positional encoding matrix
Do you have any questions about positional encoding discussed in this post? Ask your questions in the comments below and I will do my best to answer.
The post A Gentle Introduction to Positional Encoding In Transformer Models, Part 1 appeared first on Machine Learning Mastery.
Read MoreMachine Learning Mastery