

{kind=link}
In this post, we present several bulk data loading strategies optimized for Amazon Relational Database Service (Amazon RDS) for PostgreSQL. Although general optimization guides for bulk data loading into PostgreSQL are widely available, we illustrate how to apply these strategies in an Amazon RDS for PostgreSQL context.
First, a word of caution. No combination of optimizations or strategies is appropriate for every customer use case. DBAs and developers must decide what strategies are best given the business requirements and other operational risks.
How to optimize an Amazon RDS for PostgreSQL database for bulk loading is a common question we get from customers. Some scenarios customers describe for why they need to bulk load data are:
Enriching operational data with insights
Third-party data or data from other systems may be ingested and integrated in a data lake, but the refined data needs to be merged into the operational database to provide insights to users.
Specialized PostgreSQL capabilities
Some analysts prefer to use PostgreSQL’s specialized querying features for geospatial and JSON data.
Legacy reporting
Existing PostgreSQL reporting or analysis queries may be difficult or costly to migrate to alternative platforms.
Data security and tenant isolation
The business may want to use a PostgreSQL database to provide a few analysts with secure access to sensitive data. Similarly, the business could initialize a new PostgreSQL database to provide secure data access to an external stakeholder, such as a customer, vendor, or auditor.
Constraints
To narrow the focus and dive deep, we set the following constraints to control for several variables:
Amazon S3 and the COPY command – In all our testing scenarios, data is loaded into Amazon RDS for PostgreSQL from Amazon Simple Storage Service (Amazon S3) using the aws_s3 extension and the COPY command.
GZIP compression – PostgreSQL is capable of loading data files compressed with standard GZIP compression. Compressing data files reduces the amount of data transferred over the network from Amazon S3. We use GZIP compression in all scenarios.
AWS Graviton2 – We use AWS Graviton2-based instance types exclusively. Comparing the performance of different chipsets or instance families is out of scope for this post. Choosing one controls this variable.
PostgreSQL version – We use PostgreSQL major version 14 in all scenarios.
Solution overview
The following diagram illustrates the solution architecture we use for the benchmark tests.
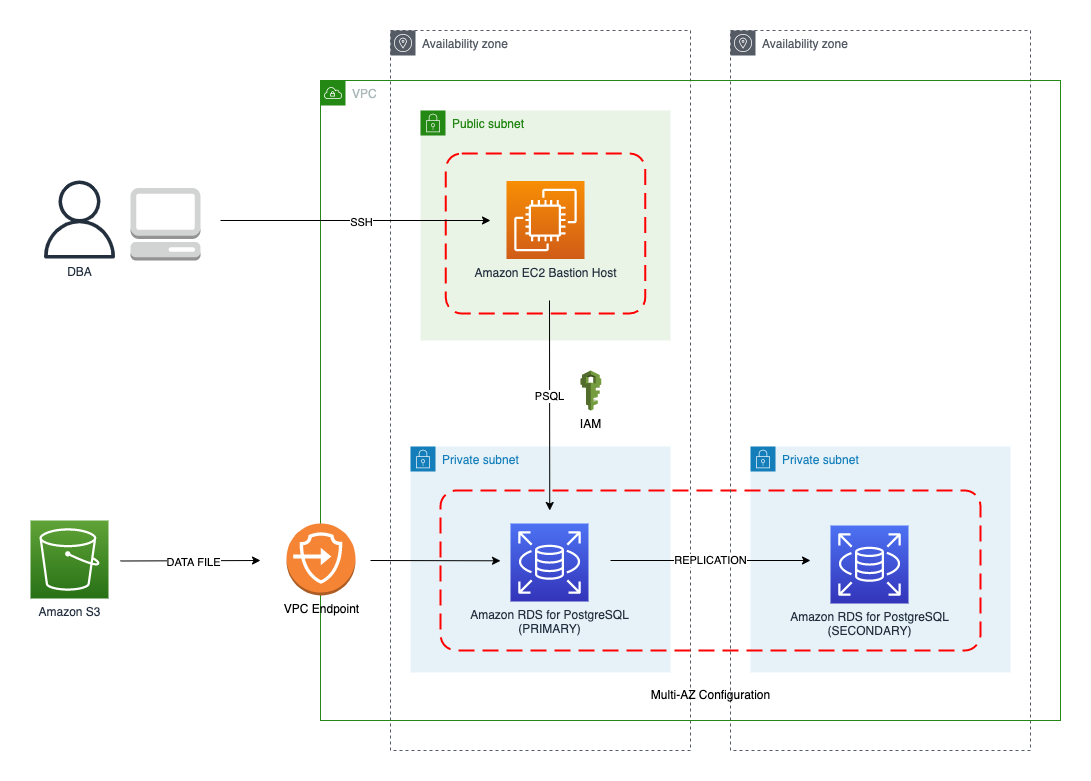{kind=link}
The database instance isn’t publicly accessible because it’s in a private subnet. Instead, the database instance is accessed via the bastion host in the public subnet. We use security group rules to restrict SSH access on the bastion host to our IP address. We use AWS Identity and Access Management (IAM) to authenticate to the database from the bastion host. Finally, we use an S3 VPC endpoint to provide a private route from Amazon S3 to our VPC where our RDS for PostgreSQL database resides.
We place the bastion host in the same Availability Zone as the RDS for PostgreSQL instance to minimize network latency. For our tests, we submit psql commands to the database from bash scripts run on the bastion host.
Prerequisites
If you intend to set up a similar testbench, note the following prerequisites.
Create an RDS for PostgreSQL instance
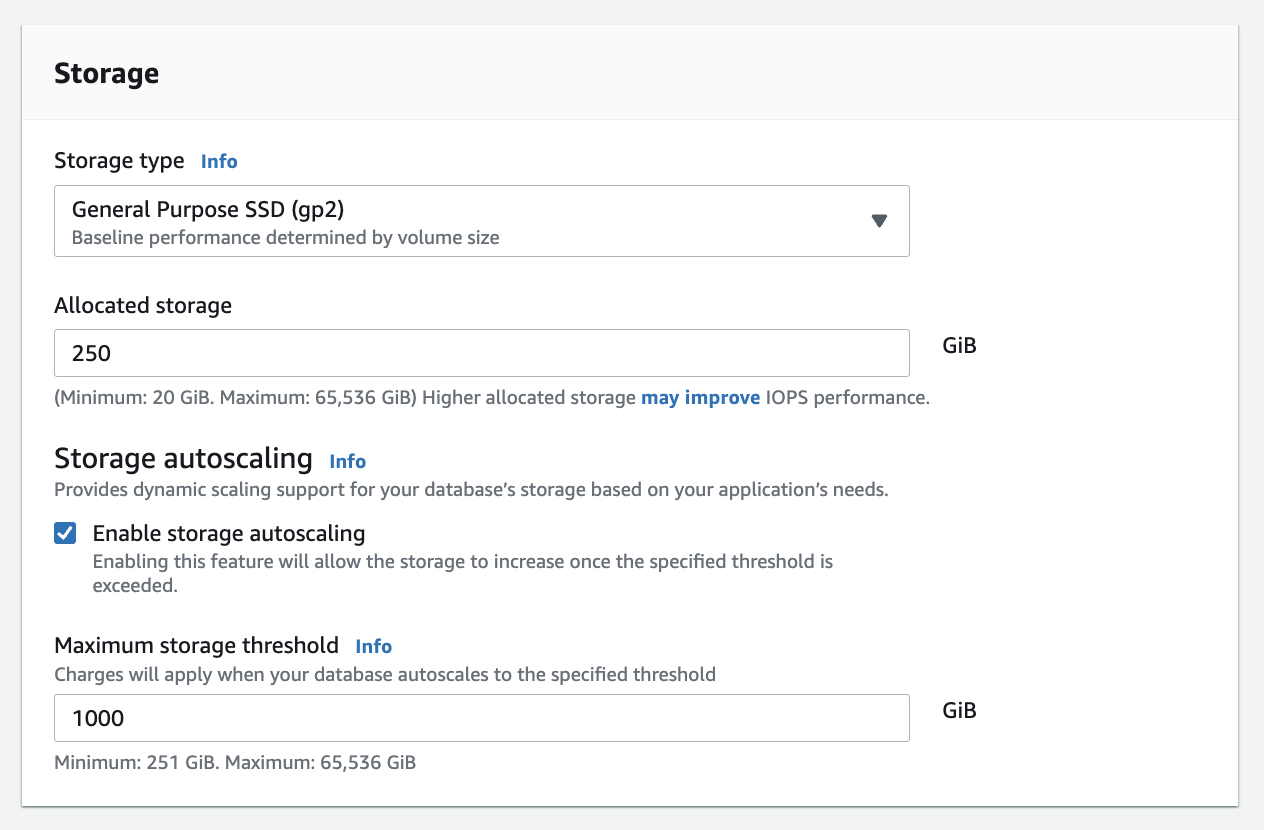
We use the db.r6g.2xlarge instance size with 250 GB of General Purpose SSD (gp2) storage. Later we will change the database storage type to Provisioned IOPS SSD (io1) to compare performance with gp2. Note that dedicated Amazon Elastic Block Store (Amazon EBS) bandwidth and network bandwidth vary by instance size. Refer to the RDS for PostgreSQL pricing page for cost information.
On the Amazon RDS console, choose Create database.
For Engine type, select PostgreSQL.
For Version, choose PostgreSQL 14.2-R1.
For DB instance identifier, enter a name for the DB instance.
Under Credentials Settings, enter a user name and password.
For DB instance class, select Memory optimized classes.
Choose db.r6g.2xlarge for the instance size.
Allocate 250 GB of General Purpose SSD (gp2) storage.
Select Enable storage autoscaling.
For Database authentication options, select Password and IAM database authentication.
{kind=link}
{kind=link}
{kind=link}
We recommend using IAM database authentication to connect to your database instance from the bastion host.
{kind=link}
To connect to your RDS instance using IAM database authentication, refer to How do I connect to my Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL using IAM authentication.
Set up bastion host
If you don’t have a bastion host set up already you can refer to the Linux Bastion Hosts on AWS reference deployment. You will need to update the security group for your RDS for PostgreSQL instance to allow access from the security group of the bastion host.
Create database and target tables
Use the DDL scripts provided in the GitHub repo associated with this post to create the imdb database, the staging schema, and the target tables. There are no indexes, keys, or constraints and the data type of the table columns are text to simplify loading.
Install the aws_s3 extension
To bulk load files from Amazon S3 using the COPY command, you need to install the aws_s3 extension on the RDS database server. You also need to associate an IAM role and policy that provides S3 bucket permissions for the s3import function. For instructions, refer to Importing Amazon S3 data into an RDS for PostgreSQL DB instance.
Connect to the imdb database from the bastion host using psql command. Execute the following command to Install the aws_s3 extension:
Use the following CLI command to create an IAM policy that provides S3 bucket permissions for the s3import extension:
Create an IAM role and associate the policy you just created:
Attach the policy:
Add the IAM role to the RDS for PostgreSQL instance:
Acquire benchmark datasets
We use the publicly available IMDb datasets for the benchmarking tests presented in this post. We opted not to use the popular benchmarking tool pgbench because its intended primary use is to measure performance of simulated concurrent users executing transactional SQL operations (SELECT, INSERT, UPDATE) rather than bulk loading using the COPY command.
Upload these public datasets to the S3 bucket you specified in the IAM policy.
{kind=link}
Benchmark baseline
Before we start applying optimizations, let’s take a baseline measurement using the default database settings in a Multi-AZ configuration. From the IMDb dataset, we bulk load the largest file, titles.principals.tsv.gz, which is 361 MB.
From our Amazon Elastic Compute Cloud (Amazon EC2) bastion, we use a psql command from a shell script. Setting up a pgass file with credentials allows us to run commands using these scripts.
The principals.sql file contains the following SQL command using the aws_s3.table_import_from_s3 function:
We get the following results.
{kind=link}
This is significantly higher than expected. In the next section, we’ll demonstrate how to identify and eliminate bottlenecks.
Optimizing storage-based IOPS
A common bottleneck constraining bulk loading performance in Amazon RDS for PostgreSQL is storage disk IOPS capacity. Database IOPS capacity doesn’t reach peak utilization if the EBS volume IOPS capacity is a limiting factor. In this section, we demonstrate how to analyze and optimize EBS volume IOPS performance when used with Amazon RDS for PostgreSQL.
Three storage types are available, each with different IOPS capabilities, as described in the following table (Magnetic is listed in the table for completeness, but it is not recommended for database use).
Storage Type
IOPS
Price
Provisioned IOPS SSD (io1)
Flexibility in provisioning I/O
High
General Purpose SSD (gp2)
Determined by volume size
Medium
Magnetic (not recommended)
1,000 IOPS maximum
Low
To detect whether disk IOPS capacity is a bottleneck, we monitor the disk queue length metric from the performance insights dashboard. When an IOPS request can’t be served immediately by the disk, it’s added to a queue. The length of this queue indicates how much of the I/O load is deferred due to throughput limitations.
On the Amazon RDS dashboard, open your database.
On the Monitoring tab, expand the Monitoring menu and choose Performance Insights.
Choose Manage metrics.
Select the rdsdev.avgQueueLen metric from the diskIO section.
Choose Update graph.
{kind=link}
{kind=link}
Running the bulk loading benchmark with the baseline configuration again revealed a large average queue length, indicating that the operation is constrained by the IOPS capacity of the EBS volume.
{kind=link}
From these results, we see a max average queue length of 2,048 requests.
To remediate this, there are two primary options:
Increase the volume size of the Amazon EBS General Purpose SSD (gp2) volume
Choose the Amazon EBS Provisioned IOPS (io1) volume and set the IOPS independent of volume size
Let’s look at the gp2 option first. The General Purpose SSD (gp2) provides a baseline of 100 IOPS at a 33.33 GB volume size, then 3 IOPS per GB above that, with the ability to burst to 3,000 IOPS for extended periods. For more information, see Solid state drives (SSD).
We originally provisioned a General Purpose SSD (gp2) volume sized at 250 GB. This provides a baseline of 750 IOPS.
Combining 750 IOPS and the max average queue depth, we get 2750 IOPS. We increased the volume size to 1500 GB to yield 4400 IOPS and ran the same baseline benchmark.
{kind=link}
This reduced our max average queue depth by 10 times, from 2,048 to just under 200. To compare, we also converted storage of our test database to Provisioned IOPS (io1) and provisioned 10,000 IOPS. Results were comparable with a queue length of 170.
{kind=link}
With our EBS storage volumes optimized for higher IOPS capacity, we ran the baseline benchmark again, yielding a significant increase in throughput.
{kind=link}
Loading times dropped from 5 minutes, 45 seconds, to just over 1 minute, for an increase in throughput of 82%. Now that we have our storage IOPS optimized, let’s look at database configuration optimizations.
Parallelize bulk loading commands
You can run multiple psql commands in parallel by using the ampersand character suffix in a Linux bash script. This tells the OS to fork and run the command in a subshell. In this section, we test bulk loading multiple files in parallel and sequentially and compare the results. First let’s test sequential runs of our psql commands.
The following is our copy_bulk_sequential.sh bash script:
We observe the following results.
{kind=link}
Let’s look at some of the database metrics during the sequential load.
{kind=link}
As expected, our db.r6g.2xlarge instance with 8 vCPU shows one active session.
{kind=link}
CPU utilization averages 15% and doesn’t get above 30%.
{kind=link}
We average about 200K Kb/s and spike at just over 400K Kb/s.
Now let’s see how parallelizing the psql commands alters performance. The following copy_bulk_parallel.sh script runs each psql command in a separate subprocess. Each call creates a separate session in the RDS instance and performs the bulk loading of these seven files in parallel.
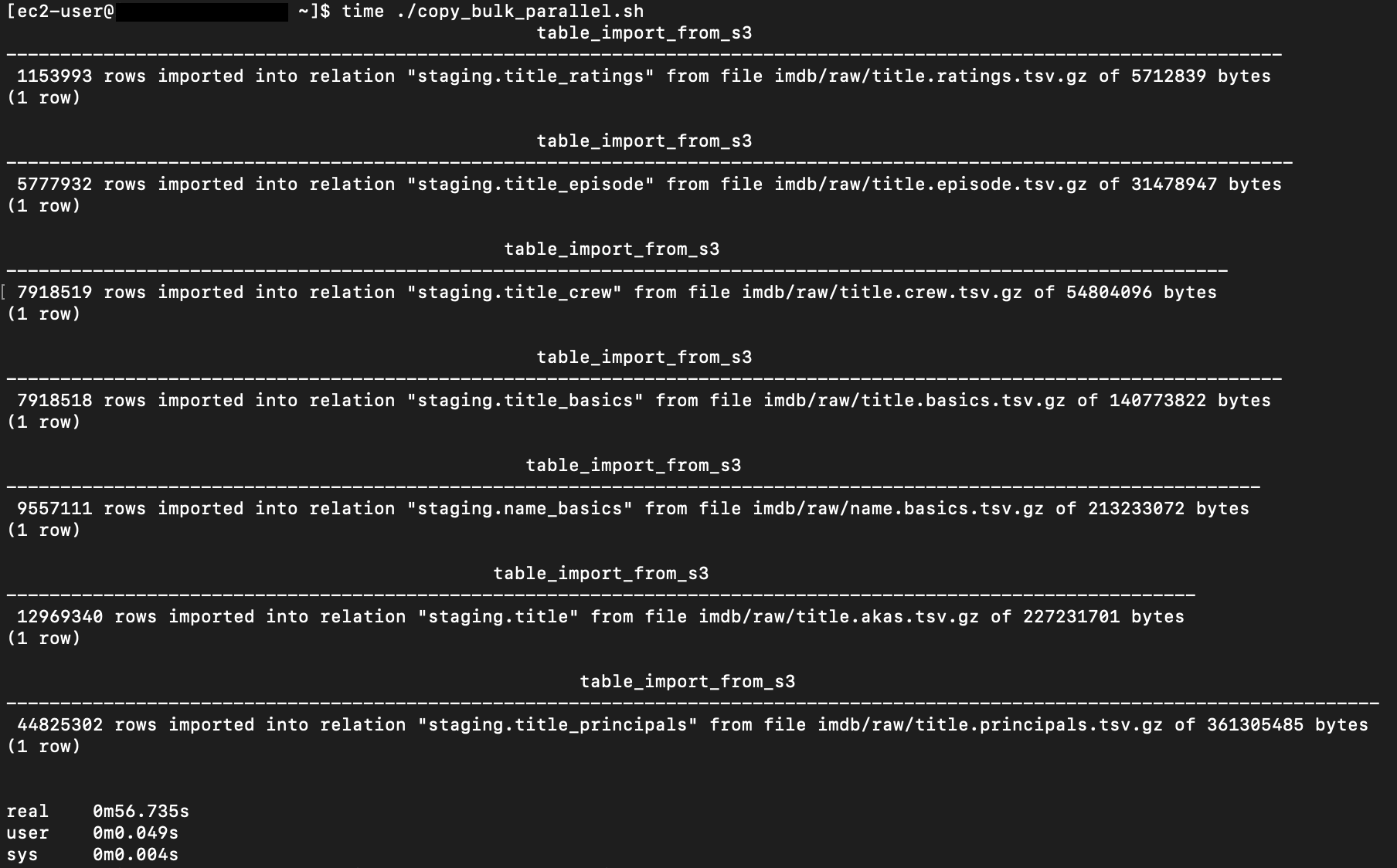
The following screenshot shows the results of our parallel load.
{kind=link}
For all seven files, we were able to reduce loading time by more than half, or 56%, from 2 minutes, 9 seconds, down to 57 seconds.
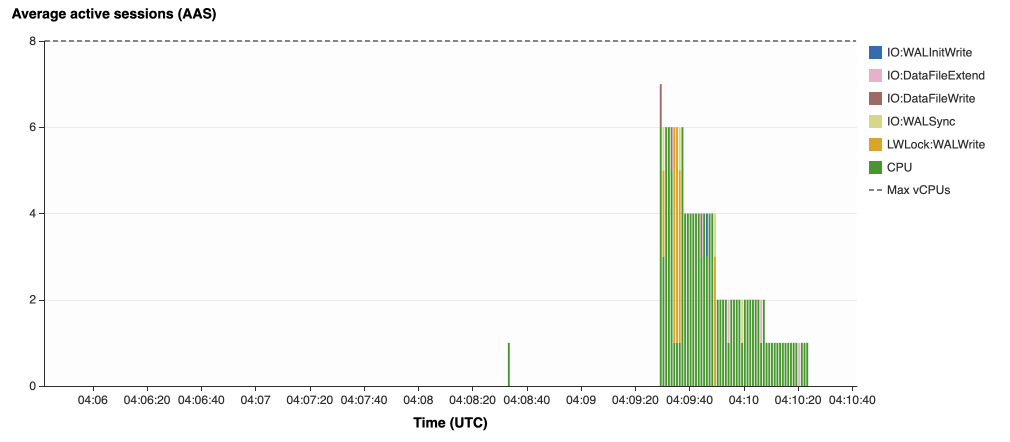{kind=link}
Our parallel load saturated nearly all the available cores. As files completed their load, sessions closed and quickly dropped our concurrent active sessions count.
{kind=link}
The CPU utilization initially spiked to 90%.
{kind=link}
Write throughput averaged over 400K Kb/s and spiked to over 800K Kb/s, essentially doubling the throughput of the sequential load.
When you have multiple large files to bulk load, run your bulk loading commands in parallel to achieve the highest throughput. A general guideline is to limit the number of concurrent bulk loading sessions to one less than the number of vCPUs.
Now let’s look at database configuration.
Database configuration optimizations
Section 14.4 Populating a Database of the official PostgreSQL documentation provides configuration recommendations to optimize for bulk loading. We implement many of these recommendations in Amazon RDS for PostgreSQL.
Because certain administrative rights are restricted in AWS managed databases, setting database configuration in RDS databases is performed through a conceptual container called database parameter groups. Database parameter groups are engine-specific and can be applied as part of a database modification task.
This abstraction provides a useful mechanism for persisting and managing multiple configurations that can be swapped in and out for different scenarios, including bulk data loading.
Configuration parameters are classified with either a dynamic or static apply type, which can be viewed through the console. Dynamic parameters can be applied immediately. Static parameters require a database server restart.
To create a parameter group for bulk loading, we choose the postgres14 parameter group family because it reflects the major PostgreSQL version of our database instance. The creation of database parameter groups and the setting of parameter values can be done programmatically via the AWS Command Line Interface (AWS CLI), SDK, or API. We use the AWS CLI for these examples, which are available in the GitHub repo.
Create the parameter groups with the following code:
The following screenshot shows the JSON response.
{kind=link}
Now we set the parameter values for Amazon RDS for PostgreSQL. We use a JSON file with database parameter values optimized for bulk loading.
Pass the JSON file to the AWS CLI command to modify the values stored in our bulk load parameter group:
Modify the RDS instance by applying the bulk loading parameter group:
Before we continue, let’s review the parameter changes made and how they impact bulk loading performance.
Increase maintenance_work_mem
Increasing maintenance_work_mem doesn’t improve performance of the COPY itself, but it does improve performance of CREATE INDEX, ADD FOREIGN KEY, and ALTER TABLE statements that would likely follow if keys and indexes are dropped prior to loading and readded after loading completes. AUTOVACUUM performance is also improved by this parameter setting.
Setting the maintenance_work_mem parameter to 1 GB is recommended (PostgreSQL doesn’t use more than 1GB so setting this higher won’t add any benefit). The parameter takes an integer value in kB. For 1 GB, the value is 1048576.
Avoid automatic checkpointing
All modifications to a PostgreSQL database are written to a log called the Write-Ahead Log (WAL). A checkpoint is a point in the WAL at which all data files have been written to disk. An automated operation called checkpointing occurs regularly to flush dirty pages to disk so the WAL up to that checkpoint can be recycled. In normal operation, frequent checkpointing ensures faster recovery in the event of system failure. During bulk loading, checkpointing inhibits overall write throughput.
Three PostgreSQL parameters control the frequency of checkpointing:
max_wal_size
checkpoint_completion_target
checkpoint_timeout
The max_wal_size and checkpoint_completion_target parameters set the size the WAL can grow to before automatic checkpointing is triggered. By default, the checkpoint_completion_target is 0.9. This means that the I/O needed to process 90% of the checkpointing (90% of the max_wal_size limit) is spread evenly within the time period specified in the checkpoint_timeout to reduce the impact on other database operations. The checkpoint_timeout parameter triggers checkpointing after a specified time interval. The default is 5 minutes.
You can trigger the checkpointing process manually using the CHECKPOINT command immediately after bulk loading is complete. This is recommended. For bulk loading, we advise setting the parameter values high enough to avoid automatic checkpointing as much as possible. For max_wal_size, we follow the recommendation specified in Importing data into PostgreSQL on Amazon RDS, and set it to 4 GB. We increase checkpoint_timeout to 30 minutes. Note that these gains in performance come with availability risk. In the event of a failover or crash, these settings could result in a recovery time of 10 minutes or more (depending on the workload) instead of the default 1 to 2 minutes.
In addition to these global parameter settings, there are local settings that provide additional optimizations. Let’s review these next.
Disable synchronous_commit at the transaction level
The synchronous_commit setting can be applied at the global, session, or transaction level. It is never recommended to disable synchronous_commit at the global level to improve bulk loading performance. If a failover or crash occurs, this will cause data loss for transactions executing in any session. We can instead disable synchronous_commit locally from within the transaction, which will expire when the transaction is committed. This limits the risk when the data to be loaded is staged in a durable storage service like S3. Any bulk loaded data lost can simply be reloaded.
The following code block demonstrates how to disable synchronous_commit at the transaction level:
Disable autovacuum at the table level
Never turn off autovacuum globally. Autovacuum performs necessary maintenance tasks that keeps the database working. Prior to PostgreSQL version 13, autovacuum wasn’t triggered by inserts so it didn’t have a performance impact during bulk loading. The downside was that insert-only tables were never vacuumed. For these tables, vacuuming needed to be performed manually. Starting with PostgreSQL version 13, autovacuum is now triggered by inserts. For most scenarios, the performance impact of autovacuum during bulk loading will be negligible. Optimizing maintenance_work_mem as discussed previously also enhances autovacuum performance. If I/O operations from autovacuuming is observed to impact performance, the service can be disabled at the table level and vacuum can be run manually after bulk loading completes.
Disable autovacuum for table:
Enable autovacuum for table:
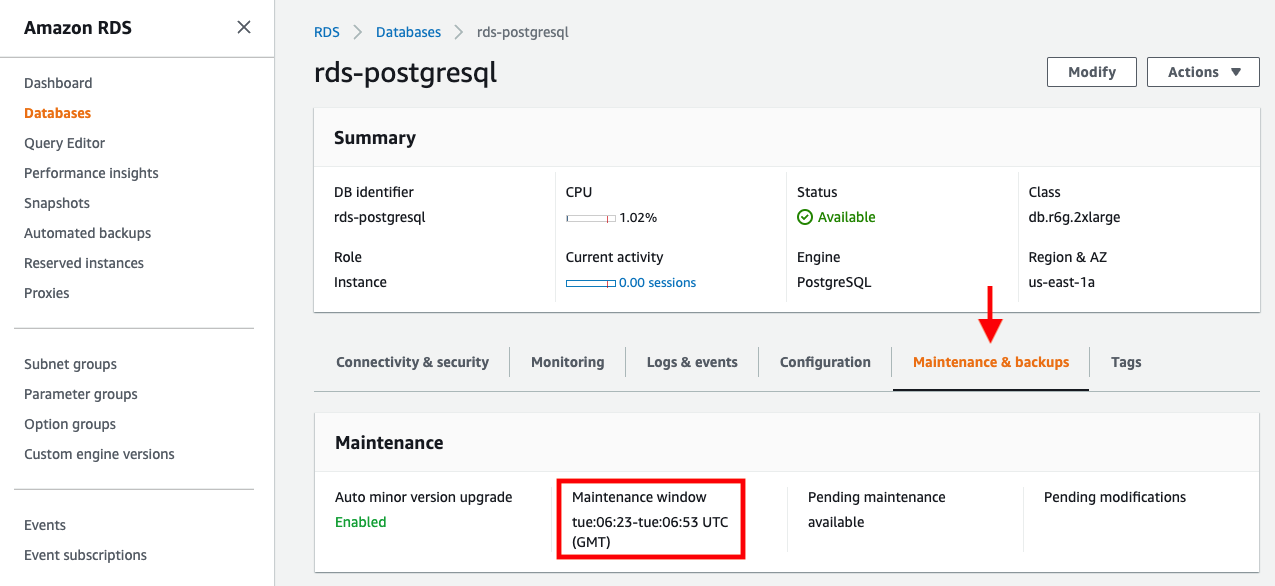
Avoid bulk loading when weekly maintenance is being performed
It is recommended to avoid bulk loading when weekly maintenance is being performed. You can view the weekly maintenance window from the Maintenance & backups tab of the RDS dashboard.
{kind=link}
You can set a maintenance window when creating or modifying the database.
This concludes the review of PostgreSQL database configuration settings and approaches for optimizing bulk loading.
Now let’s run our single file load test using the principals.gz file with these database optimizations applied. Here are the results.
{kind=link}
The loading time for our single file dropped from 57 to 44 seconds for an additional 23% speedup.
Anti-patterns
Before we conclude, let’s discuss some optimization strategies for bulk loading that are not recommended. The following are anti-patterns that should be avoided.
Do not disable Multi-AZ
Amazon RDS for PostgreSQL with the Multi-AZ feature enabled increases availability by synchronously replicating data to a standby instance in a different Availability Zone. The database can fail over to this standby instance if the primary instance becomes unreachable. Disabling Multi-AZ will yield better bulk loading performance, but it is not recommended for production workloads due to the durability and availability risk.
Do not disable table logging
PostgreSQL truncates all unlogged tables on startup, including failovers and snapshot restores. Unlogged tables are also not replicated to PostgreSQL replicas. Due to the risk of data loss, use of unlogged tables is not recommended for production workloads.
Conclusion
In this post, we presented strategies for optimizing RDS for PostgreSQL databases for bulk loading from Amazon S3. We demonstrated how to detect if a bulk loading operation is constrained by insufficient storage-based IOPS capacity and provided options for remediation. We demonstrated how to parallelize bulk loading operations using psql commands from bash scripts. We presented several recommendations to maximize bulk loading performance. As a result of these optimizations, we were able to reduce single file loading times for our benchmark dataset from 5 minutes, 45 seconds, to 44 seconds—a performance gain of 87%. We also identified anti-patterns for bulk loading optimization that should be avoided.
If you found our guidance helpful, let us know in the comments.
About the Author
Justin Leto is a Sr. Solutions Architect at Amazon Web Services with specialization in databases, big data analytics, and machine learning. His passion is helping customers achieve better cloud adoption. In his spare time, he enjoys offshore sailing and playing jazz piano. He lives in New York City with his wife Veera and baby daughter Elsi.
{kind=link}
Read MoreAWS Database Blog