

{kind=link}
Today, customers can raise support tickets through multiple channels like – web, mobile, chat-bots, emails, or phone calls. When a support ticket is raised by a customer, it is processed and assigned to a category based on the information provided in the ticket. It is then routed to the support group for resolution according to the category of the ticket. It is estimated that a high number of support tickets are usually not routed to the right group due to incorrect ticket categorization. Incorrectly assigned tickets cause delay in overall resolution time, often resulting in severe customer dissatisfaction. It may also have other widespread impacts like financial, operational, or other business repercussions. Hence, ticket classification is an essential task for every organization these days. Although you may classify tickets manually, but it is prone to error, not cost-effective, and does not scale.
AWS Managed Services (AMS) uses Amazon Comprehend custom classifications to categorize inbound requests by resource and operation type based on how the customer described their issue. Amazon Comprehend is a natural language processing (NLP) service that uses machine learning (ML) to uncover valuable insights and connections in text. AMS utilizes custom classifiers to label customer requests with appropriate issue types, resource type, and resource action, thereby routing customer tickets to the SMEs. Amazon Comprehend classification is utilized to find opportunities for new internal automation tools that AMS engineers can use to fulfill customer requirements to reduce manual effort and chances of manual errors. The classification data is stored in an Amazon Redshift cluster and used to analyze customer requests and find new automation tool candidates. This automation results in increased operational efficiency and reduced cost.
In this post, we show how managed service providers can use Amazon Comprehend to classify and route the tickets, provide suggestions based on the classification, and utilize the classification data.
Solution overview
The following diagram shows the solution architecture.
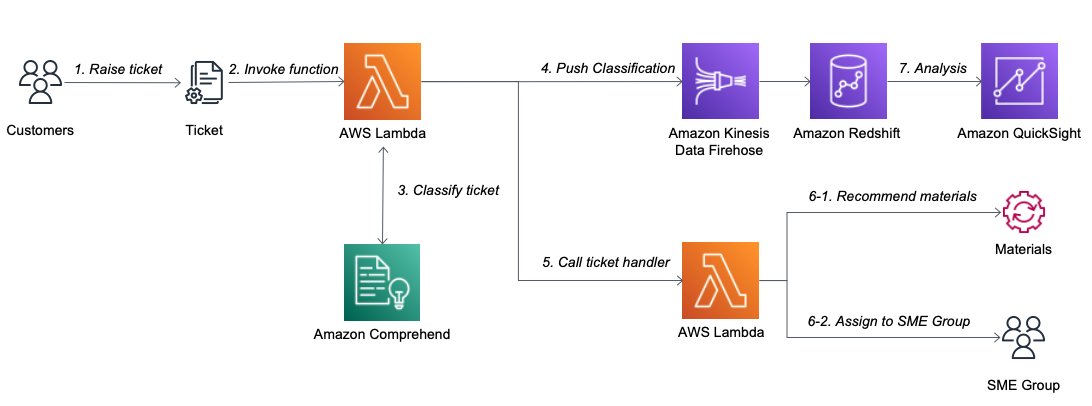{kind=link}
The workflow is as follows:
A customer submits the ticket.
The ticket system receives the ticket from the customer, and invokes the ticket classifier AWS Lambda function with the ticket details. Lambda is a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. Lambda is chosen for the solution to reduce cost and maintenance effort.
The ticket classifier Lambda function classifies the ticket with Amazon Comprehend using the ticket title and description. With Amazon Comprehend, you can train the NLP model and provide both batch and real-time classifiers without provisioning and maintaining infrastructure.
The ticket classifier Lambda function pushes the ticket classification data to the Amazon Redshift cluster via Amazon Kinesis Data Firehose. Kinesis Data Firehose is an extract, transform, and load (ETL) service that captures, transforms, and delivers streaming data to data lakes, data stores, and analytics services. Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price performance at any scale. Kinesis Data Firehose delivers data to an Amazon Simple Storage Service (Amazon S3) bucket first and then issues an Amazon Redshift COPY command to load the data into an Amazon Redshift cluster.
The ticket classifier Lambda function invokes the ticket handler Lambda function.
The ticket handler Lambda function runs code to help the ticket handling. In this example, it returns the recommended materials for handling the ticket based on the classification.
Ticket analysis can be done with Amazon QuickSight. From ticket analysis, you can find out the top requested ticket type. Based on the analysis, you can discover ticket trends and opportunities to automate top ticket types. QuickSight is a cloud-scale business intelligence (BI) service that you can use to deliver easy-to-understand insights to the people who you work with, wherever they are.
In the following sections, we walk you through the steps to implement the solution, integrate the ticket classification infrastructure with your ticketing system, and use the classification data with QuickSight.
Implement the solution
In this section, we walk through the steps to provision your solution resources and create the necessary infrastructure.
Configure Amazon Comprehend
In this step, we train two new Amazon Comprehend custom classification models: Operation and Resource, and create a real-time analysis endpoint for each model.
Upload the training data
To upload the training data, complete the following steps:
Download ticket_training_data.zip and unzip the file.
This folder contains the following two files:
training_data_operations.csv – This file is a two-column CSV file that we use to train the Operation classification model. The first column contains class, and the second column contains document.
training_data_resources.csv – This file is a two-column CSV file that we use to train the Resource classification model. Like the training_data_operations.csv file, the first column contains class, and the second column contains document.
On the Amazon S3 console, create a new bucket for Amazon Comprehend. Because S3 bucket names are globally unique, you need to create a unique name for the bucket. For this post, we call it comprehend-ticket-training-data. Enable server-side encryption and block public access when creating the bucket.
Upload training_data_operations.csv and training_data_resources.csv to the new S3 bucket.
Create two new models
To create your models, complete the following steps:
On the Amazon Comprehend console, choose Custom classification in the navigation pane.
Choose Create new model.
Provide the following information:
For Model name, enter ticket-classification-operation.
For Language, choose English.
For Classifier mode, select Using Single-label mode.
For Data format, select CSV file.
For Training dataset, enter the S3 path for training_data_operations.csv.
For Test data source, select Autosplit.
Autosplit automatically selects 10% of your provided training data to use as testing data.
For IAM Role, select Create an IAM role.
For Permissions to access, choose the training, test, and output data (if specified) in your S3 buckets.
For Name suffix, enter ticket-classification.
Choose Create.
Choose Create new model again to create your resource classification model.
Provide the following information:
For Model name, enter ticket-classification-resource.
For Language, choose English.
For Classifier mode, select Using Single-label mode.
For Data format, select CSV file.
For Training dataset, enter the S3 path for training_data_resources.csv.
For Test data source, select Autosplit.
For IAM Role, select Use an existing IAM role.
For Role name, choose AmazonComprehendServiceRole-ticket-classification.
{kind=link}
{kind=link}
Amazon Comprehend is now processing the CSV files and using them to train custom classifiers. We then use these to help classify customer tickets. The larger and more accurate our training data is, the more accurate the classifier will be.
Wait for the version status to show as Trained as below. It may take up to 1 hour to complete, depending on the size of the training data.
{kind=link}
Create Amazon Comprehend endpoints
Amazon Comprehend endpoints are billed in 1-second increments, with a minimum of 60 seconds. Charges continue to incur from the time you start the endpoint until it’s deleted, even if no documents are analyzed. For more information, see Amazon Comprehend Pricing. To create your endpoints, complete the following steps:
On the Amazon Comprehend console, choose Endpoints in the navigation pane.
Choose Create endpoint to create your operation classification endpoint.
Provide the following information:
For Endpoint name, enter ticket-classification-operation.
For Custom model type, select Custom classification.
For Classifier model, choose ticket-classification-operation.
For Version, choose No Version Name.
For Number of inference units (IUs), enter 1.
Choose Create endpoint.
Choose Create endpoint again to create the resource classification endpoint.
Provide the following information:
For Endpoint name, enter ticket-classification-resource.
For Custom model type, select Custom classification.
For Classifier model, choose ticket-classification-resource.
For Version, choose No Version Name.
For Number of inference units (IUs), enter 1.
{kind=link}
{kind=link}
After you create both endpoints, wait until the status for both shows as Active.
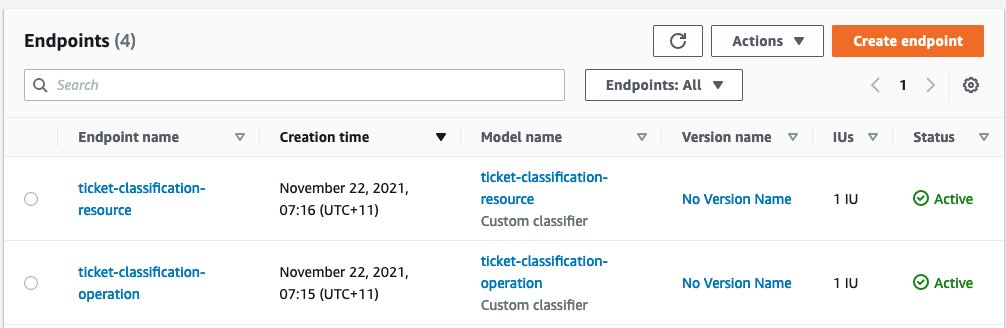{kind=link}
Test the Amazon Comprehend endpoints with real-time analysis
To test your endpoints, complete the following steps:
On the Amazon Comprehend console, choose Real-time analysis in the navigation pane.
For Analysis type¸ select Custom.
For Endpoint¸ choose ticket-classification-operation.
For Input text, enter the following:
Choose Analyze.
The results show that the Update class has the highest confidence score.
Change Endpoint to ticket-classification-resource and choose Analyze again.
The results show that the EC2 class has the highest confidence score.
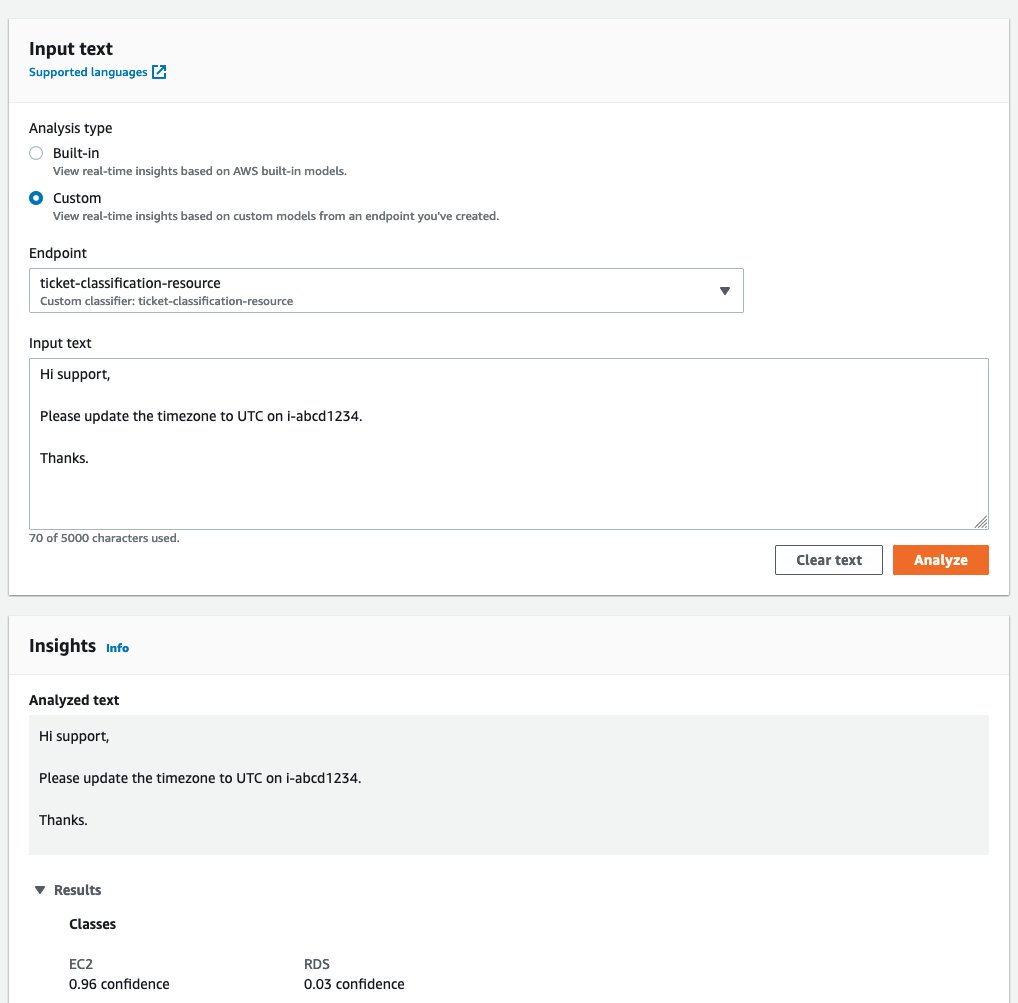{kind=link}
Create a secret for the Amazon Redshift cluster password
In this step, we create an AWS Secrets Manager secret for your Amazon Redshift cluster password. Secrets Manager helps you protect secrets needed to access your applications, services, and IT resources. The service enables you to easily rotate, manage, and retrieve database credentials, API keys, and other secrets throughout their lifecycle. In this post, we store the Amazon Redshift cluster password in a Secrets Manager secret.
On the Secrets Manager console, choose Secrets in the navigation pane.
Choose Store a new secret.
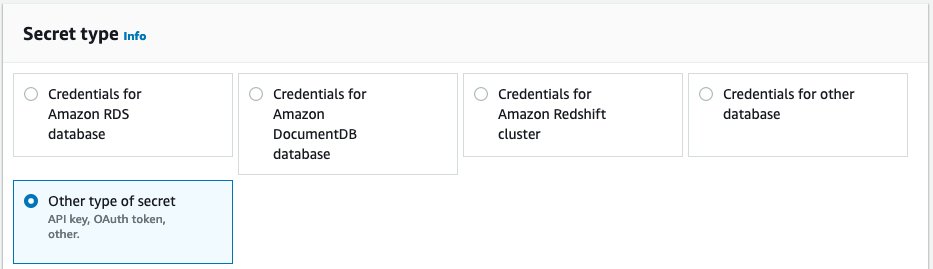
For Secret type, select Other type of secret.
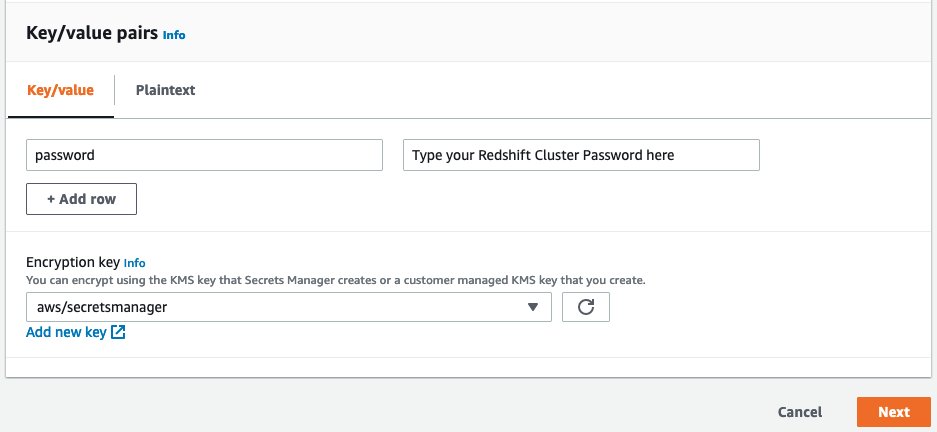
Under Key/value pairs, set your key as password and value as your Amazon Redshift cluster password.
The password must be between 8–64 characters in length and contain at least one uppercase letter, one lowercase letter, and one number. It can be any printable ASCII character except ‘ (single quote), “ (double quote), , /, @, or space.
Choose Next.
For Secret name, enter ClassificationRedshiftClusterPassword.
Choose Next.
In the Secret rotation section, choose Next.
Review your secret configuration and choose Store.
{kind=link}
{kind=link}
Provision your infrastructure with AWS CloudFormation
In this step, we provision the infrastructure for the solution using an AWS CloudFormation stack.
Upload the Lambda function code
Before launching the CloudFormation stack, upload your Lambda function code:
Download lambda_code.zip
On the Amazon S3 console, open the bucket that you created.
Upload lambda_code.zip.
Create your CloudFormation stack
To provision resources with AWS CloudFormation, complete the following steps:
Download cloudformation_template.json.
On the AWS CloudFormation console, choose Create stack.
Select With new resources (standard).
For Template source, choose Upload a template file.
Choose the downloaded CloudFormation template.
Choose Next.
For Stack name, enter Ticket-Classification-Infrastructure.
In the Parameters section, enter the following values:
For ClassificationRedshiftClusterNodeType, enter the Amazon Redshift cluster node type. dc2.large is the default.
For ClassificationRedshiftClusterPasswordSecretName, enter the Secrets Manager secret name that stores the Amazon Redshift cluster password.
For ClassificationRedshiftClusterSubnetId, enter the subnet ID where the Amazon Redshift Cluster is hosted. The subnet must be within the VPC which you mentioned in the ClassificationRedshiftClusterVpcId parameter.
For ClassificationRedshiftClusterUsername, enter the Amazon Redshift cluster user name.
For ClassificationRedshiftClusterVpcId, enter the VPC ID where the Amazon Redshift cluster is hosted.
For LambdaCodeS3Bucket, enter the S3 bucket name where you uploaded the Lambda code.
For LambdaCodeS3Key, enter the Amazon S3 key of the deployment package.
For QuickSightRegion, enter the Region for QuickSight. The Region for QuickSight should be consistent with the Region you’re using for Amazon Comprehend and the S3 bucket.
Choose Next.
In the Configure stack options section, choose Next.
In the Review section, select I acknowledge that AWS CloudFormation might create IAM resources.
Choose Create stack.
Configure your Amazon Redshift cluster
In this step, you enable audit logging and add the new table to the Amazon Redshift cluster created through the CloudFormation template.
Audit logging is not turned on by default in Amazon Redshift. When you turn on logging on your cluster, Amazon Redshift exports logs to Amazon CloudWatch, which capture data from the time audit logging is enabled to the present time. Each logging update is a continuation of the previous logs.
Enable audit logging
You can skip this step if you don’t need audit logging for your Amazon Redshift cluster.
On the Amazon Redshift console, choose Clusters in the navigation pane.
Choose the Amazon Redshift cluster starting with classificationredshiftcluster-.
On the Properties tab, choose Edit.
Choose Edit audit logging.
For Configure audit logging¸ choose Turn on.
For Log expert type, choose CloudWatch.
Select all log types.
Choose Save changes.
Create new table
To create a new table, complete the following steps:
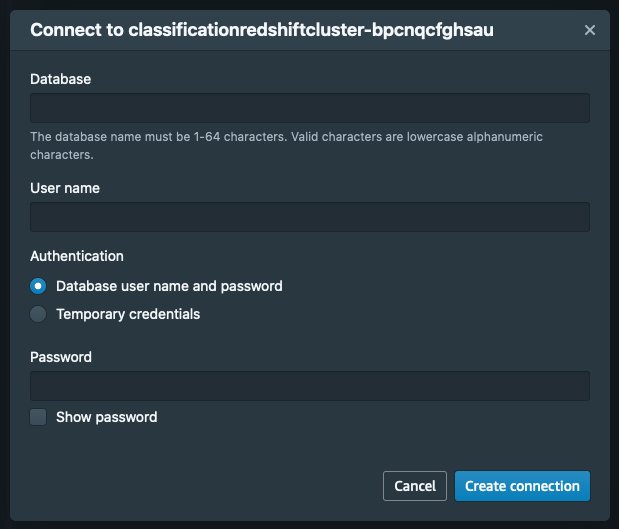
On the Amazon Redshift console, choose Query data.
Choose Query in query editor v2.
On the Database page, choose your cluster.
For Database, enter ticketclassification.
Enter the user name and password you configured in the CloudFormation stack parameters.
Choose Create connection.
When the connection is made, choose the plus sign and open a new query window.
Enter the following query:
{kind=link}
{kind=link}
Choose Run.
Test the classification infrastructure
Now the infrastructure for ticket classification is ready. Before integrating with your ticket system, let’s test the classification infrastructure.
Run the test
To run the test, complete the following steps:
On the Lambda console, choose Functions in the navigation pane.
Choose the function that starts with Ticket-Classification-Inf-TicketClassifier.
On the Test tab, choose Test event.
For Name, enter TestTicket.
Enter the following test data:
{kind=link}
The ticket is classified, and the classification data is stored in the Amazon Redshift cluster. After the classification, the ticket handler Lambda function runs, which handles the ticket based on the classification, including recommending materials to support engineers.
Check the ticket classifier test log
To check the test log, complete the following steps:
In the result section of the test, choose Logs, or choose View logs in CloudWatch on the Monitor tab.
Choose the log stream.
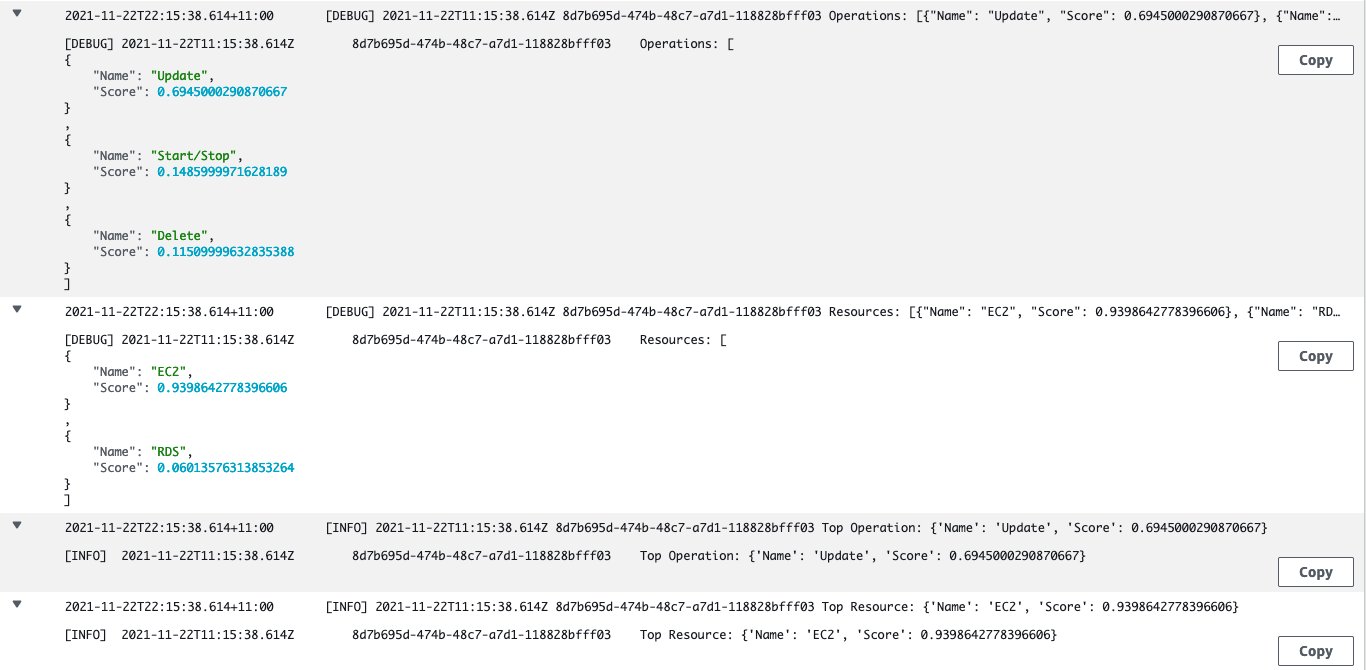
You can view the logs in the following screenshot, which shows the output from Amazon Comprehend and the final top classification of the ticket. In this example, the test ticket is classified as Resource=EC2, Operation=Update.
{kind=link}
Check the ticket classification output in the Amazon Redshift cluster
To validate the output in your cluster, complete the following steps:
On the Amazon Redshift query editor v2 console, choose the plus sign to open a new query window.
Enter the following query:
Choose Run.
The following screenshot shows the ticket classification. If it’s not available yet, wait for a few minutes and retry (Kinesis Data Firehose needs some time to push the data). We can now use this data in QuickSight.
{kind=link}
Check the ticket handler test log
After the ticket classifier pushes the classification data in the Amazon Redshift cluster, the ticket handler Lambda function runs, which handles the ticket based on the classification, including recommending materials to support engineers. In this example, the ticket handler returns recommended materials including the runbook, AWS documentation, and SSM documents so support can refer to them when handling the ticket. You can integrate the output with your ticket handling system, and you can customize the handling processes in the Lambda function code. In this step, we check what recommendations were made.
On the Lambda console, choose Functions in the navigation pane.
Choose the Lambda function that starts with Ticket-Classification-Inf-TicketHandlerLambdaFunct.
On the Monitor tab, choose View logs in CloudWatch.
Choose the log stream.
The following screenshot shows the logs. You can see the output from Amazon Comprehend and the list of recommended AWS documents and SSM documents for the ticket classified as Update EC2. You can add your own runbooks, documents, SSM documents, or any other materials in the Lambda function code.
{kind=link}
Integrate the ticket classification infrastructure with your ticketing system
In this section, we walk through the steps to integrate your ticketing classification infrastructure with your ticketing system and customize your configuration.
Most ticketing systems have a trigger feature, which allows you to run code when the ticket is submitted. Set up your ticketing system to invoke the ticket classifier Lambda function with the following formatted input:
If you want to customize the input, modify the ticket classifier Lambda function code. You need to add or remove parameters (lines 90–105) and customize the input for Amazon Comprehend (lines 15–17).
You can customize the ticket handler Lambda function to run automation or edit the recommendations. For example, you can add the internal comment to the ticket with the recommendations. To customize, open the ticket handler Lambda code, and edit lines 68–70 and 75–81.
Use classification data with QuickSight
After you integrate the ticket classification infrastructure with your ticket system, the ticket classification data is stored in the Amazon Redshift cluster. You can use QuickSight to check this data and generate reports. In this example, we generate a QuickSight analysis with the classification data.
Sign up for QuickSight
If you don’t already have QuickSight, sign up with the following steps:
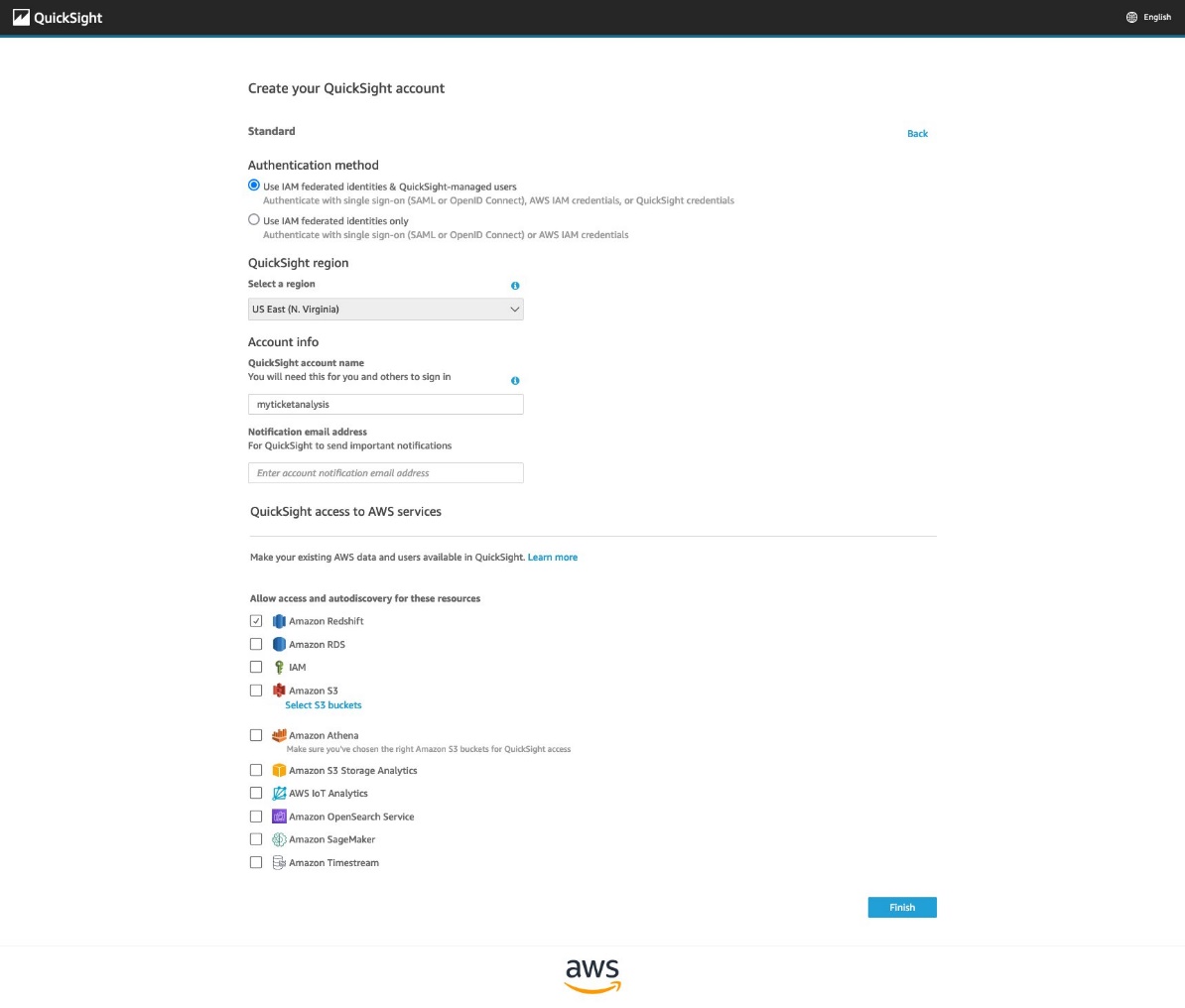
On the QuickSight console, choose Sign up for QuickSight.
Choose Standard.
Under QuickSight region, choose the Region you configured in the CloudFormation parameter QuickSightRegion.
Under Account info, enter your QuickSight account name and notification email address.
Under QuickSight access to AWS services, select Amazon Redshift.
If you want to allow access and autodiscovery for other resources, select them as well.
Choose Finish.
Choose Go to Amazon QuickSight after you’re signed up.
{kind=link}
Connect your Amazon Redshift cluster to QuickSight
To connect your cluster to QuickSight as a data source, complete the following steps:
On the QuickSight console, choose Datasets in the navigation pane.
Choose New dataset.
Choose Redshift Auto-discovered.
Provide the following information:
For Data source name, enter ticketclassification.
For Instance ID, choose the Amazon Redshift cluster starting with classificationredshiftcluster-.
For Connection type, choose Public network.
For Database name, enter ticketclassification.
Enter the Amazon Redshift cluster user name and password you configured in the CloudFormation stack parameters.
Choose Validate connection to see if the connection works.
If it doesn’t work, this is likely due to using the wrong user name and password, or the QuickSight Region is different from what you specified in the CloudFormation stack.
Choose Create data source.
In the Choose your table section, select the tickets table.
Choose Select.
Select Import to SPICE for quicker analytics.
SPICE is the QuickSight Super-fast, Parallel, In-memory Calculation Engine. It’s engineered to rapidly perform advanced calculations and serve data. Importing (also called ingesting) your data into SPICE can save time and money. For more information on SPICE, refer to Importing Data into SPICE. If you get the error “Not enough SPICE capacity,” purchase more SPICE capacity. For more information, refer to Purchasing SPICE capacity in an AWS Region.
Choose Visualize.
{kind=link}
{kind=link}
{kind=link}
Create a ticket classification analysis report
Once you finish dataset creation, you can see the new QuickSight analysis. In this section, we walk through the steps to create a ticket classification analysis report, including a pivot table, pie charts, and line charts.
Choose AutoGraph.
Under Visual types, choose the pivot table.
Drag operation from Fields list to Rows.
Drag resource from Fields list to Columns.
On the Add menu, choose Add visual.
Under Visual types, choose the pie chart.
Drag operation from Fields list to Group/Color.
On the Add menu, choose Add visual again.
Under Visual types, choose the pie chart again.
Drag resource from Fields list to Group/Color.
On the Add menu, choose Add visual again.
Under Visual types, choose the line chart.
Drag creation_time from Fields list to X axis.
Drag operation from Fields list to Color.
On the Add menu, choose Add visual again.
Under Visual types, choose the line chart again.
Drag creation_time from Fields list to X axis.
Drag operation from Fields list to Color.
Resize and reorder the charts as needed.
Choose Save as.
Enter a name for your analysis and choose Save.
Congratulations! Your first ticket analysis is ready. Once you have more data, the analysis will look like the following screenshot.
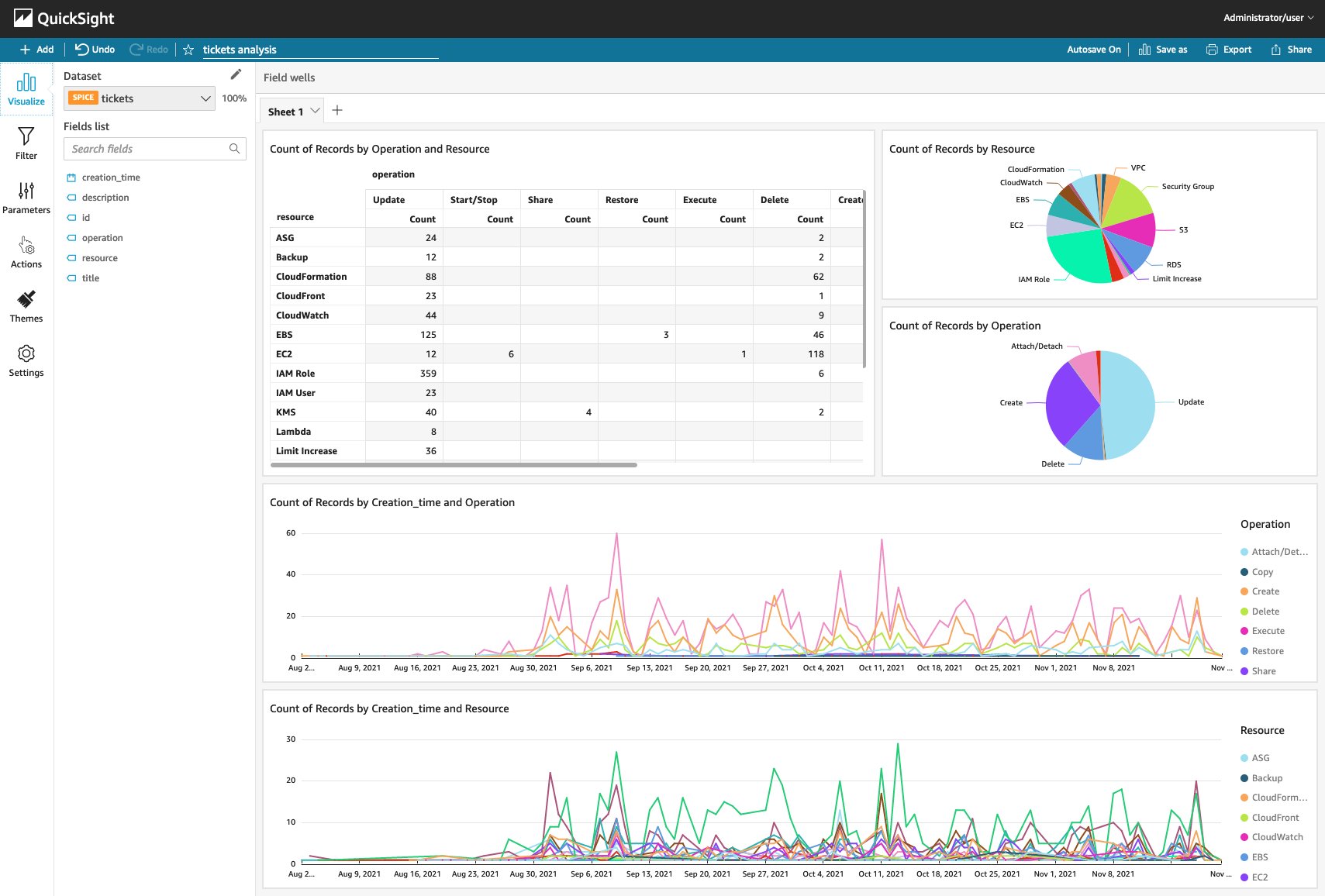{kind=link}
Clean up
In this step, we clean up the resources we created with various services.
Amazon Comprehend
To delete your endpoints, complete the following steps:
On the Amazon Comprehend console, choose Endpoints in the navigation pane.
Select the endpoint ticket-classification-operation.
Choose Delete and follow the prompts.
Repeat these steps to delete the ticket-classification-resource endpoint.
Next, delete the custom classifications you created.
Choose Custom classification in the navigation pane.
Select the classification ticket-classification-operation.
Select No Version Name.
Choose Delete and follow the prompts.
Repeat these steps to delete the ticket-classification-resource classification.
Amazon S3
Next, clean up the S3 bucket you created.
On the Amazon S3 console, select the bucket you created.
Delete all the objects in the bucket.
Delete the bucket.
Amazon QuickSight
Delete the QuickSight analyses and dataset you created.
On the QuickSight console, choose Analyses in the navigation pane.
Choose the options icon (three dots) on the analysis you created.
Choose Delete and follow the prompts.
Choose Datasets in the navigation pane.
Choose the tickets dataset.
Choose Delete dataset and follow the prompts.
AWS CloudFormation
Clean up the resources you created as part of the CloudFormation stack.
On the AWS CloudFormation console, choose Stacks in the navigation pane.
Choose the Ticket-Classification-Infrastructure stack.
On the Resources tab, choose the physical ID of ClassificationDeliveryStreamS3Bucket.
The Amazon S3 console opens.
Delete any objects in this bucket.
Return to the AWS CloudFormation console, choose Delete, and follow the prompts.
AWS Secrets Manager
Lastly, delete the Secrets Manager secret.
On the Secrets Manager console, select the secret ClassificationRedshiftClusterPassword.
On the Actions menu, choose Delete secret.
Set the waiting period as 7 days and choose Schedule Delete.
Your secret will be automatically deleted after 7 days.
Conclusion
In this post, you learned how to utilize AWS services to create an automatic classification and recommendation system. This solution will help your organizations build the following workflow:
Classify customer requests.
Recommend automated solutions.
Analyze customer request classifications and discover top customer requests.
Release a new automated solution and increase the automation rate.
For more information about Amazon Comprehend, see Amazon Comprehend Documentation. You can also discover other Amazon Comprehend features and get inspiration from other AWS blog posts about using Amazon Comprehend beyond classification.
About the Authors
Seongyeol Jerry Cho is a Senior Systems Development Engineer at AWS Managed Services based in Sydney, Australia. He focuses on building highly scalable and automated cloud operations software using a variety of technologies, including machine learning. Outside of work, he enjoys travel, camping, reading, cooking, and running.
{kind=link}
Manu Sasikumar is a Sr. Systems Engineer Manager with AWS Managed Services. Manu and his team focus on building powerful and easy-to-use automations to reduce manual effort, and build AI and ML-based solutions for managing customer requests. Outside of work, he loves spending his spare time with his family, as well as being part of various humanitarian and volunteer activities.
{kind=link}
Read MoreAWS Machine Learning Blog