

{kind=link}
Neural networks are computationally intensive and often take hours or days to train. Data parallelism is a method to scale the training speed with the number of workers (e.g. GPUs). At each step, the training data is split in mini-batches to be distributed across workers, and each worker computes its own set of gradient updates, which are applied to all replicas. All-reduce is the default cross-device communication operation in TensorFlow, PyTorch, and Horovod to gather gradients in each iteration and sum over multiple workers. The communication in each training iteration utilizes significant network bandwidth.
To improve the speed of data parallel training on GPU clusters, Vertex AI launches Reduction Server, a faster gradient aggregation algorithm developed at Google to double the algorithm bandwidth of all-reduce operations. Reduction Server enables distributed ML training jobs to run with efficient bandwidth utilization (up to 2x more throughput) and completes the training job faster. This benefit in reduced training time could lead to reduced total cost of operation. In addition, a user can implement Reduction Server on Vertex AI without changing any of the underlying training code.
This blog post introduces the concept of Reduction Server and demonstrates how Google Cloud customers can leverage this feature on Vertex AI to improve their training time. In the next section, we will dive into the technical details and examine all-reduce, a key operation for distributed data-parallel training.
All-reduce
All-reduce is a collective operation to reduce (an operation such as sum, multiply, max, or min) target arrays in all workers to a single array and return the result to all workers. It has been successfully used in the distributed neural network training scenario where gradients from multiple workers need to be summed and delivered to all workers. Figure 1 illustrates the semantics of all-reduce.
{kind=link}
There are numerous approaches to implement all-reduce efficiently. In traditional all-reduce algorithms, workers communicate and exchange gradients with each other over a topology of communication links (e.g. a ring or a tree). Ring all-reduce is a bandwidth-optimal all-reduce algorithm, in which workers form a logical ring and communicate with their immediate neighbors only. However, even the bandwidth-optimal all-reduce algorithms still need to transfer input data twice1 over the network.
Reduction Server
Reduction Server is a faster GPU all-reduce algorithm developed at Google. There are two types of nodes: workers and reducers. Workers run model replicas, compute gradients, and apply optimization steps. Reducers are lightweight CPU VM instances (significantly cheaper than GPU VMs), dedicated to aggregating gradients from workers. Figure 2 illustrates the overall architecture with 4 workers and a sharded collection of reducers.
{kind=link}
Each worker only needs to transfer one copy of the input data over the network. Therefore, Reduction Server effectively halves the amount of data to be transferred. Another advantage of Reduction Server is that its latency does not depend on the number of workers. Reduction Server is also stateless and only reduces the gradients and shares back with the workers.
The table below summarizes the amount of data transfer and latency per worker of Reduction Server compared to ring and tree based all-reduce algorithms with n workers.
{kind=link}
Reduction Server provides transparent support to many frameworks that use NCCL for distributed GPU training (e.g. TensorFlow and PyTorch) and is available on Vertex AI. This allows ML practitioners to use Reduction Server without having to change the training code.
Performance wins
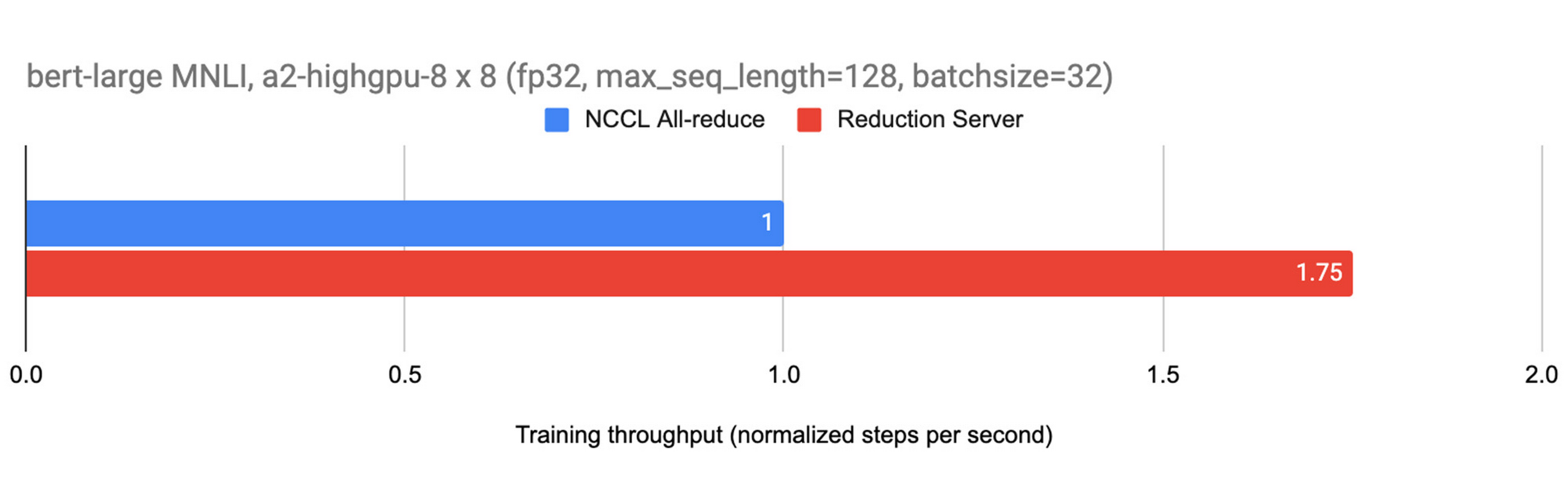
Figure 3 shows the performance gains from using Reduction Server on fine tuning a BERT model from the TensorFlow Model Garden on the MNLI dataset using 8 GPU worker nodes each equipped with 8 NVIDIA A100 GPUs. In this experiment, with 20 reducer nodes the training throughput increased by 75%. Other large models benefit from Reduction Server with increased throughput and reduced training time as well.
{kind=link}
Conclusion
In this blog, we introduced how Reduction Server available on Vertex AI can provide significant improvements in distributed data-parallel GPU training and make transparent transition from traditional all-reduce to Reduction Server for ML practitioners.
To learn more, visit our documentation for in-depth information to help you get some hands-on experience with Reduction Server on Vertex AI.
1. If the target array size has n elements, each worker needs to send and receive 2(n-1) elements over the network during an all-reduce operation.
Cloud BlogRead More