

{kind=link}
The AWS Schema Conversion Tool (AWS SCT) accelerates migration for commercial database and data warehouse schemas along with code objects to open-source engines or AWS-native services, such as Amazon Aurora and Amazon Redshift.
For your database migration to the cloud, you can choose a rehost (lift and shift), replatform (lift and reshape), or refactor approach. Refactor migration involves reviewing, evaluating, and re-architecting workloads based on their purpose. The source and target database of this type of migration may include one or multiple types of databases. For example, you may migrate an existing on-premises Oracle database to Amazon Aurora PostgreSQL and Amazon Redshift, where different portions of the existing workload are migrated to the platform that is best suited to host it.
Previously, AWS SCT only supported a single source and target. If you wanted to replatform to different targets, you had to create a separate migration project for each target. The newest release of AWS SCT (656) includes a new feature to create a multi-server project. A multi-server project lets you create a conversion project for one or more sources to one or more target databases. It also introduces new mapping rules that allow mixing and matching of different source and target databases in the same project, providing a unified view. The new mapping rule supports the following scenarios:
Conversion of schemas from one source database to several targets
Conversion of schemas from different source databases to one or multiple targets
In this post, we demonstrate how to configure an AWS SCT multi-server project, including configuring drivers, adding connections, mapping schemas, generating and viewing an Assessment Report, and converting schemas.
Solution overview
Our use case for this post involves migrating two Oracle databases located on-premises to an AWS database platform. The first Oracle database contains a mix of online transaction processing (OLTP) and online analytical processing (OLAP) workloads. Some objects in the first Oracle database have a database link (DB_LINK) connected to the other Oracle database. The second Oracle database contains OLTP workloads.
Our proposed migration strategy includes the following tasks:
Migrate the OLTP workload to Aurora PostgreSQL.
Migrate the OLAP workload to Amazon Redshift.
Consolidate objects with DB_LINK and migrate them to Aurora PostgreSQL.
The following diagram illustrates our solution architecture.
{kind=link}
The multi-server project configuration process includes the following high-level steps:
Configure JDBC drivers in AWS SCT global settings.
Add the source and target connections.
Map the source and target schemas.
Generate an Assessment Report.
View the Assessment Report.
Convert schemas.
Configure JDBC drivers in AWS SCT global settings
AWS SCT requires JDBC drivers to connect to your source and target databases. To configure the driver path in AWS SCT, complete the following steps:
Download and install JDBC drivers. All supported database drivers are listed in AWS SCT User Guide.
Navigate to the global settings on the Settings page. Choose Drivers in the navigation pane, and add the file path to the JDBC driver for your source and target database engines.
For this post, I added an Oracle driver.
{kind=link}
Add source and target connections
AWS SCT version 656 only requires connectivity to source databases. A target connection is optional. This version includes a new feature called a virtual target. A virtual target allows you to run assessments and convert schemas without having to create a target database first. For this post, we only add a source connection. Complete the following steps:
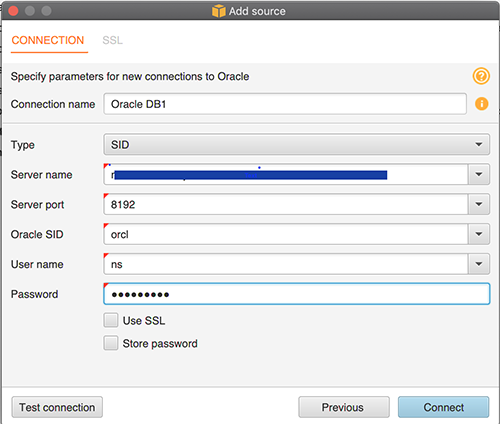
Choose Add source.
Choose your desired database vendor.
For Connection name, enter a name (for this post, Oracle DB1).
Provide the connection details.
Choose Connect.
{kind=link}
{kind=link}
{kind=link}
For this post, I added two Oracle databases, Oracle DB1 and Oracle DB2, to the project.
{kind=link}
Map source and target schemas
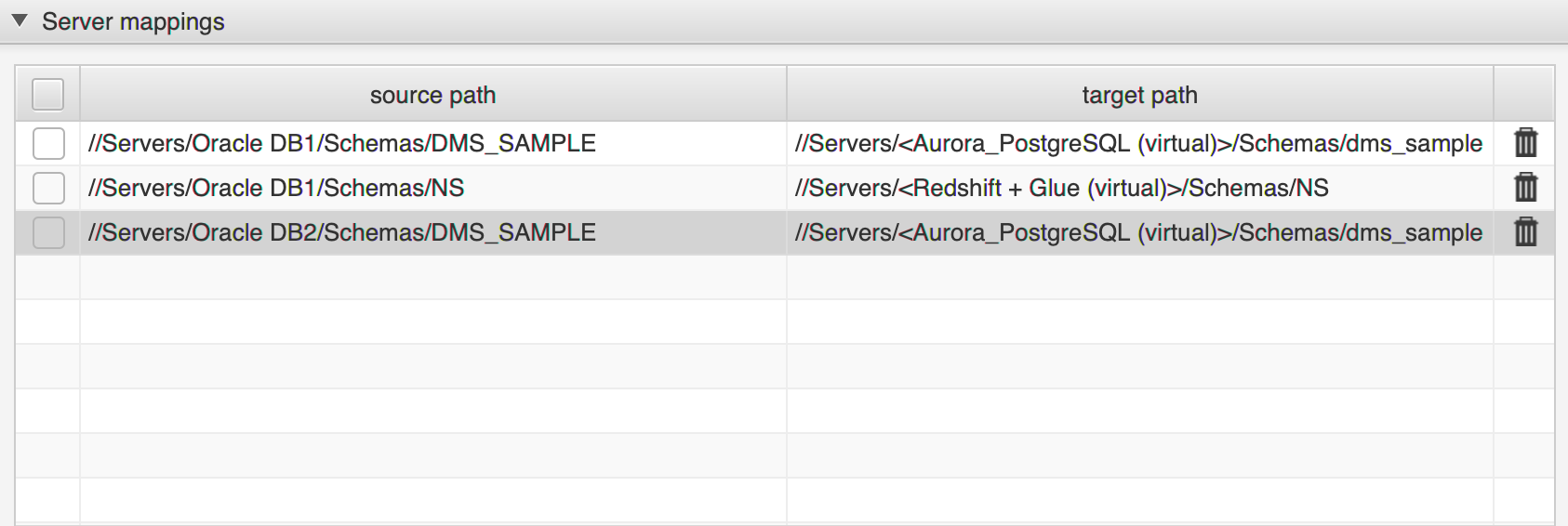
An AWS SCT multi-server project connects all elements in a single project, which requires proper mapping configurations. In this scenario, I have one schema in Oracle DB1 mapped to Aurora PostgreSQL, another schema in Oracle DB1 mapped to Amazon Redshift, and a schema in Oracle DB2 mapped to Aurora PostgreSQL.
In the source tree, choose one or more schemas for mapping. Right-click and choose and Create mapping to create the mapping for the intended target database platform.
{kind=link}
After you create the mappings, the mapping view is available.
{kind=link}
Generate an Assessment Report
After you create your mappings, you can generate an Assessment Report.
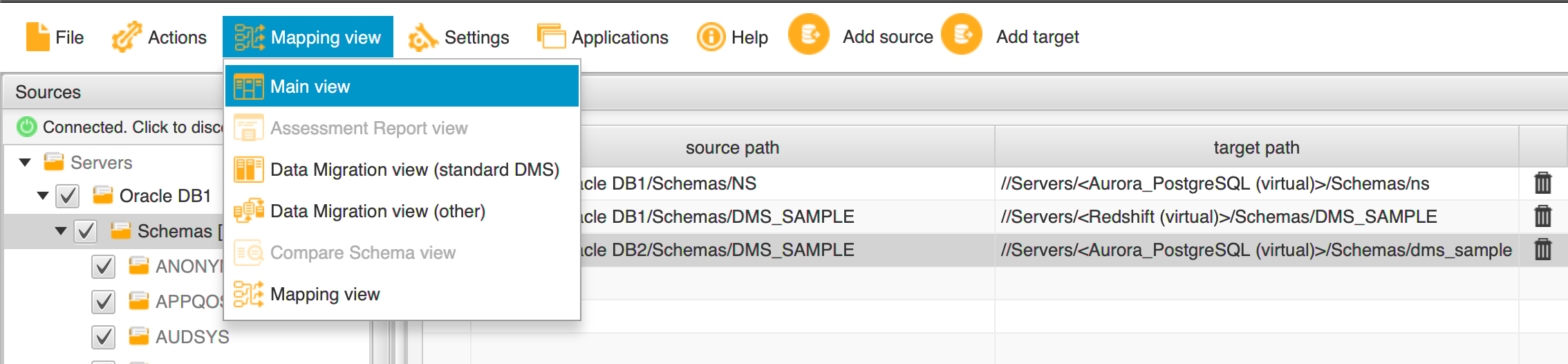
On the Mapping view menu, choose Main view.
Expand Oracle DB1 in the Servers list.
Select the desired schemas.
Choose Schemas (right-click) and choose Create report.
{kind=link}
{kind=link}
View the Assessment Report
In a multi-server project, the Assessment Report provides consolidated views of all the mapped schemas and targets from a single source database.
The following screenshots are samples of an Assessment Report from one of the source databases in this multi-server project. In this scenario, I have one schema mapped to Aurora PostgreSQL and another schema mapped to Amazon Redshift. The summary report provides a high-level view for both target databases. You can select the target server or scroll down to view details for each target database.
{kind=link}
The details report is grouped by each target database.
You can save this report in CSV and PDF format for viewing outside AWS SCT or sharing with others.
{kind=link}
{kind=link}
Convert schemas
When you’re ready to convert your schemas, complete the following steps:
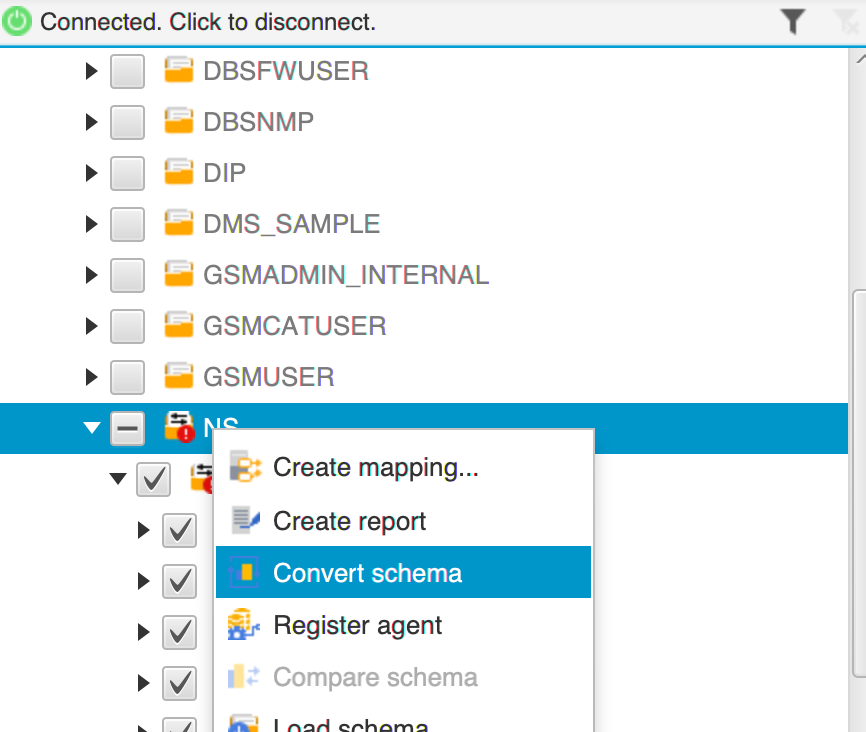
Select the desired objects from the source tree (right-click).
Choose Convert schema.
{kind=link}
AWS SCT doesn’t apply the converted code to the target database directly. You can view and edit the converted code inside AWS SCT or save it to a SQL script.
To view or edit the converted code inside AWS SCT, choose an object in the source tree. The converted code is displayed in the lower-center panel.
{kind=link}
To save the converted code to a SQL script, choose the intended schema on the target tree (right-click), and choose Save as SQL.
{kind=link}
To apply the converted code to the target database, choose the intended schema on the target tree (right-click), and choose Apply to database. This option is only available for non-virtual targets.
{kind=link}
Conclusion
With an AWS SCT multi-server project, you can manage migrations that include multiple sources and targets in a single project. In this post, we walked through how to configure drivers, add connections, configure schema mapping, generate and view an Assessment Report, and convert schemas in a multi-server project. For additional details, see the AWS SCT User Guide.
As always, AWS welcomes any feedback, so please share your comments and questions.
About the Authors
Nelly Susanto is a Senior Database Migration Specialist of AWS Database Migration Accelerator. She has over 10 years of technical background focusing on migrating and replicating databases along with data-warehouse workloads. She is passionate about helping customers in their cloud journey.
{kind=link}
Read MoreAWS Database Blog